データ分析ワークロードで Azure Data Lake Storage Gen2 を使用する
Azure Data Lake Store Gen2 は、複数のデータ分析ユース ケースを実現するテクノロジです。 いくつかの一般的な種類の分析ワークロードを調べ、Azure Data Lake Storage Gen2 が他の Azure サービスとどのように連携してそれらをサポートするかを明らかにしましょう。
ビッグ データの処理と分析
ビッグ データのシナリオとは、通常、高速 (velocity) で処理する必要があるさまざまな (variety ) 形式の大量 (volumes) のデータを含む分析ワークロードを指します (いわゆる "3 つの v")。 Azure Data Lake Storage Gen 2 では、Azure Synapse Analytics、Azure Databricks、Azure HDInsight などのビッグ データ サービスが Apache Spark、Hive、Hadoop などのデータ処理フレームワークを適用できる、スケーラブルで安全な分散データ ストアが提供されます。 ストレージと処理コンピューティングの分散という性質により、タスクを並列で実行できるため、大量のデータを処理する場合でも高パフォーマンスとスケーラビリティが得られます。
データ ウェアハウス
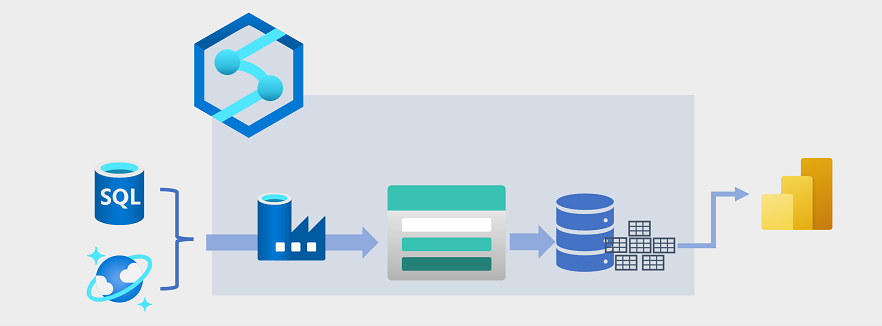
データ ウェアハウスは、データ レイク内のファイルとして格納された大量のデータと、データ ウェアハウス内のリレーショナル テーブルを統合するように、近年進化しています。 データ ウェアハウス ソリューションの一般的な例では、データは、Azure SQL Database や Azure Cosmos DB などの運用データ ストアから抽出されて、分析ワークロードに適した構造に変換されます。 多くの場合、データは、リレーショナル データ ウェアハウスに読み込まれる前に、分散処理を容易にするためにデータ レイクにステージングされます。 場合によっては、データ ウェアハウスでは、"外部" テーブルを使ってデータ レイク内のファイルの上位にリレーショナル メタデータ レイヤーが定義され、ハイブリッドの "データ レイクハウス" または "レイク データベース" アーキテクチャが作成されます。 その後、データ ウェアハウスは、レポートと視覚化のための分析クエリをサポートできます。
この種のデータ ウェアハウス アーキテクチャを実装するには、複数の方法があります。 この図で示されているソリューションでは、Azure Synapse Analytics によってホストされた "パイプライン" で、Azure Data Factory テクノロジを使って "抽出、変換、読み込み" (ETL) プロセスが実行されています。 これらのプロセスでは、運用データ ソースからデータが抽出されて、Azure Data Lake Storage Gen2 コンテナーでホストされているデータ レイクに読み込まれます。 その後、データは処理され、Azure Synapse Analytics 専用の SQL プール内のリレーショナル データ ウェアハウスに読み込まれて、そこから Microsoft Power BI を使用したデータの視覚化とレポートをサポートできます。
リアルタイム データ分析
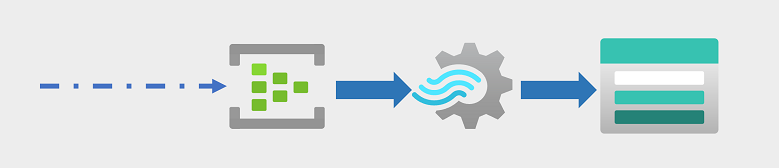
企業や他の組織では、永続的なデータ ストリームをキャプチャし、リアルタイム (または可能な限りほぼリアルタイム) で分析することが、ますます必要になっています。 これらのデータ ストリームは、接続されたデバイス (多くの場合、"モノのインターネット" または "IoT" デバイスと呼ばれます) から、またはソーシャル メディア プラットフォームや他のアプリケーションでユーザーによって生成されたデータから生成できます。 従来の "バッチ処理" ワークロードとは異なり、ストリーミング データでは、発生するデータ イベントの際限のないストリームをキャプチャして処理できるソリューションが必要です。
ストリーミング イベントは、多くの場合、処理のためにキューにキャプチャされます。 図で示されている Azure Event Hubs などの複数のテクノロジを使って、このタスクを実行できます。 ここから、データは処理されて、多くの場合はテンポラル ウィンドウに集計されます (たとえば、特定のタグを持つソーシャル メディア メッセージの数を 5 分ごとにカウントしたり、インターネットに接続されたセンサーの読み取り値の 1 分間の平均を計算したりするため)。 Azure Stream Analytics を使うと、到着したイベント データのクエリと集計を実行して、結果を出力 "シンク" に書き込む、"ジョブ" を作成できます。 このようなシンクの 1 つが Azure Data Lake Storage Gen2 であり、そこからキャプチャされたリアルタイム データを分析して視覚化できます。
データ サイエンスと機械学習

データ サイエンスには大量のデータの統計分析が含まれ、多くの場合、Apache Spark などのツールや Python などのスクリプト言語が使われます。 Azure Data Lake Storage Gen 2 は、データ サイエンスのワークロードで必要な大量のデータのための、拡張性の高いクラウドベースのデータ ストアを提供します。
機械学習は、予測モデルのトレーニングを扱うデータ サイエンスの下位区分です。 モデルのトレーニングには、大量のデータと、そのデータを効率的に処理する機能が必要です。 クラウド サービスである Azure Machine Learning を使うことで、データ科学者は、動的に割り当てられた分散コンピューティング リソースを使ってノートブックの Python コードを実行できます。 コンピューティングは、Azure Data Lake Storage Gen2 コンテナー内のデータを処理してモデルをトレーニングします。その後、そのモデルを、予測分析ワークロードをサポートするための運用 Web サービスとしてデプロイできます。