データを結合して最適化する
多くの場合、組織は多くのソースから得たさまざまな種類の情報を照合します。 情報は、多数のテーブルに格納されます。 場合によっては、より詳細な分析やレポート作成のために、テーブル間の論理的なリレーションシップに基づいてテーブルを結合することが必要になる場合があります。 小売企業のシナリオでは、顧客、製品、販売に関する情報のテーブルを使います。
このモジュールでは、Kusto クエリでデータを結合して、製品認知度と売上の向上のために必要な情報をチーム メンバーに提供するためのさまざまな方法について学習します。
データを理解する
テーブルから得た情報を結合するクエリの作成を開始する前に、データを理解する必要があります。 Kusto クエリを操作する場合、テーブルが大まかに次の 2 つのカテゴリのいずれかに属していると考える必要があります。
- "ファクト テーブル": 小売企業のシナリオの SalesFact テーブルなど、レコードが変更できない "ファクト" であるテーブル。 これらのテーブルでは、レコードが、ストリーミング形式または大きなチャンクで徐々に追加されます。 レコードは削除されるまで残っていて、更新されることはありません。
- "ディメンション テーブル": レコードが、小売業界の Customers および Products テーブルなど、レコードが変更可能な "ディメンション" であるテーブル。 これらのテーブルは、エンティティ識別子からそのプロパティへの参照テーブルなどの参照データを保持します。 ディメンション テーブルが定期的に新しいデータで更新されることはありません。
この小売企業のシナリオでは、ディメンション テーブルを使って、追加情報で SalesFact テーブルをエンリッチしたり、クエリ用にデータをフィルター処理するための追加オプションを提供したりします。
また、操作するデータの量とその構造またはスキーマ (列名と型) も理解する必要があります。 次のクエリを実行すると、その情報を取得できます。TABLE_NAME は調べるテーブルの名前に置き換えてください。
テーブル内のレコード件数を取得するには、
count演算子を使用します。TABLE_NAME | countテーブルのスキーマを取得するには、
getschema演算子を使用します。TABLE_NAME | getschema
小売企業のシナリオのファクト テーブルとディメンション テーブルに対してこれらのクエリを実行すると、次の例のような情報が得られます。
| テーブル | レコード | スキーマ |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (real) - TotalCost (real) - DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| 顧客 | 18,484 | - CityName (string) - CompanyName (string) - ContinentName (string) - CustomerKey (long) - Education (string) - FirstName (string) - Gender (string) - LastName (string) - MaritalStatus (string) - Occupation (string) - RegionCountryName (string) - StateProvinceName (string) |
| 製品 | 2,517 | - ProductName (string) - Manufacturer (string) - ColorName (string) - ClassName (string) - ProductCategoryName (string) - ProductSubcategoryName (string) - ProductKey (long) |
この表では、テーブル間でレコードを結合するために使われる CustomerKey と ProductKey を強調して示してあります。
複数テーブルのクエリについて
データを分析した後は、必要な情報を提供するためにテーブルを結合する方法を理解する必要があります。 Kusto クエリには、複数のテーブルからデータを結合するために使用できる演算子がいくつか用意されています。たとえば、lookup、join、union 演算子などです。
join 演算子は、各テーブルの指定された列の値を照合して、2 つのテーブルの行をマージします。 結果として得られるテーブルは、使用する結合の種類によって異なります。 たとえば、"内部結合" を使うと、テーブルには、左側のテーブル ("外部テーブル" とも呼ばれます) と同じ列に加えて、右側のテーブル ("内部テーブル" とも呼ばれます) の列が含まれます。 次のセクションでは、結合の種類についてさらに学習します。 最適なパフォーマンスを得るために、一方のテーブルが他方よりも常に小さい場合は、それを join 演算子の左側として使用します。
lookup 演算子は、join 演算子の特別な実装であり、ファクト テーブルをディメンション テーブルのデータでエンリッチして、クエリのパフォーマンスを最適化します。 これは、ディメンション テーブルで検索された値でファクト テーブルを拡充します。 最適なパフォーマンスを得るために、システムでは既定で、左側のテーブルが大きい (ファクト) テーブルで、右側のテーブルが小さい (ディメンション) テーブルであると仮定します。 この仮定は、join 演算子で使われる仮定とまったく逆です。
union 演算子は、2 つ以上のテーブルからすべての行を返します。 これは、複数のテーブルのデータを結合する場合に便利です。
materialize() 関数は、後でクエリで再利用できるように、クエリ実行内の結果をキャッシュします。 サブクエリの結果のスナップショットを取得し、それをクエリ内で複数回使うようなものです。 この関数は、結果が次のようなものであるシナリオでクエリを最適化するのに役立ちます。
- コンピューティング コストが高い
- 非決定論的
この後、さまざまなテーブル マージ演算子と materialize() 関数、およびそれらの使用方法について詳しく学習します。
結合の種類
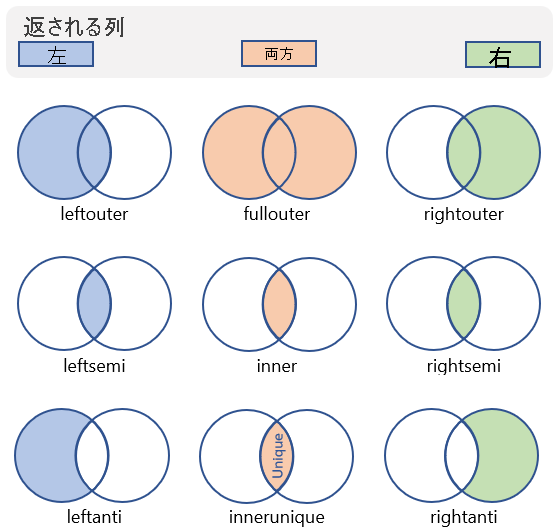
結果として得られるテーブル内のスキーマと行に影響を与えるさまざまな種類の結合を実行できます。 次の表は、Kusto 照会言語でサポートされる結合の種類と、それらから返されスキーマと行を示します。
| 結合の種類 | 説明 | 図 |
|---|---|---|
innerunique (既定値) |
左側の重複を除去する内部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 右側のテーブルの行と一致する左側のテーブルの重複除去されたすべての行 |
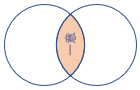
|
inner |
標準の内部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 両方のテーブルで一致する行のみ |
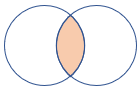
|
leftouter |
左外部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 左側のテーブルのすべてのレコードと、右側のテーブルの一致する行のみ |
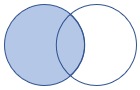
|
rightouter |
右外部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 右側のテーブルのすべてのレコードと、左側のテーブルの一致する行のみ |
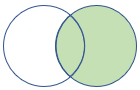
|
fullouter |
完全外部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 一致しないセルに null が設定された、両方のテーブルのすべてのレコード |
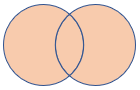
|
leftsemi |
左半結合 スキーマ: 左側のテーブルのすべての列 行: 右側のテーブルのレコードと一致する左側のテーブルのすべてのレコード |
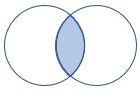
|
leftanti、anti、leftantisemi |
Left Anti Join と Semi Variant スキーマ: 左側のテーブルのすべての列 行: 右側のテーブルのレコードと一致しない左側のテーブルのすべてのレコード |
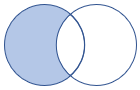
|
rightsemi |
右半結合 スキーマ: 右側のテーブルのすべての列 行: 左側のテーブルのレコードと一致する右側のテーブルのすべてのレコード |
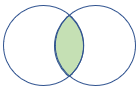
|
rightanti、rightantisemi |
Right Anti Join と Semi Variant スキーマ: 右側のテーブルのすべての列 行: 左側のテーブルのレコードと一致しない右側のテーブルのすべてのレコード |
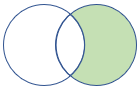
|
既定の結合の種類は innerunique であり、指定する必要がないことに注意してください。 ただし、明確にするために、常に結合の種類を明示的に指定することをお勧めします。
このモジュールを進めていくと、arg_min() および arg_max() 集計関数、let ステートメントに代わる as 演算子、データを月別にグループ化するのに役立つ startofmonth() 関数についても学習します。