演習 - join 演算子を使ってテーブルの結果を結合する
この演習では、join 演算子を使用する方法を学習します。 join 演算子では、各テーブルの指定された列の値を照合することにより、2 つのテーブルの行をマージすることを思い出してください。
join 演算子の結果を使用して、売上に関する質問に答えてみましょう。
join 演算子を使用します
小売会社のシナリオでは、チームはあなたに売上が最も多い 3 つの国/地域をリストすることを求めています。
SalesFact テーブルの調査を開始すると、必要な数値は SalesAmount 列に表示されているものの、そのテーブルにはどの国/地域のデータも含まれていないことがわかります。 他のテーブルを調べると、Customers テーブルの RegionCountryName 列に国/地域のデータが表示されていることがわかります。 また、両方のテーブルに CustomerKey 列があることがわかります。
データは 2 つのテーブルに分散されるため、要求された情報を提供するクエリを作成するには、顧客データと売上データの両方が必要です。 クエリを作成するには、join 演算子と CustomerKey 列を使い、両方のテーブルの行を照合します。
これでクエリを作成する準備ができました。 inner join を使って、両方のテーブルから一致するすべての行を取得します。 最適なパフォーマンスを得るには、顧客 "ディメンション" テーブルを左側のテーブルとして使用し、売上 "ファクト" テーブルを右側のテーブルとして使用します。
次の手順では、join 演算子を使用した結果について理解を深めるために、クエリを段階的に作成します。
次のクエリを実行し、Customers テーブルと SalesFact テーブルから 10 個の一致する任意の行を取得します。
Customers | join kind=inner SalesFact on CustomerKey | take 10結果の一覧を確認します。 テーブルには、Customers テーブルの列の後に SalesFact テーブルの一致する列が含まれていることがわかります。
次のクエリを実行して結合テーブルを集計し、売上が最も多い 3 つの国/地域を取得します。
Customers | join kind=inner SalesFact on CustomerKey | summarize TotalAmount = round(sum(SalesAmount)) by RegionCountryName | top 3 by TotalAmount結果は次の図のようになるはずです。
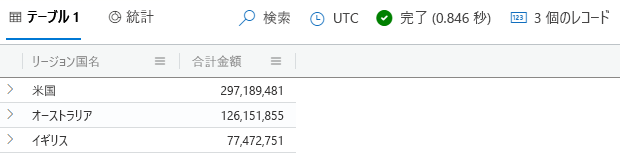
結果の一覧を確認します。 クエリを変更し、これらの国/地域の対応する総コストと利益も表示してみてください。
その後、あなたはチームから、過去 1 年間の収益が最も低い国/地域を月別に特定するように求められました。 このデータを取得するには、同様のクエリを使用します。 ただし、今回は、startofmonth() 関数を使って月別のグループ化を容易にします。 また、arg_min() 集計関数も使って、各月の収益が最も低い国/地域を見つけます。
次のクエリを実行します。
Customers | join kind=inner SalesFact on CustomerKey | summarize TotalAmount = round(sum(SalesAmount)) by Month = startofmonth(DateKey), RegionCountryName | summarize arg_min(TotalAmount, RegionCountryName) by Month | top 12 by Month desc結果は次の図のようになるはずです。
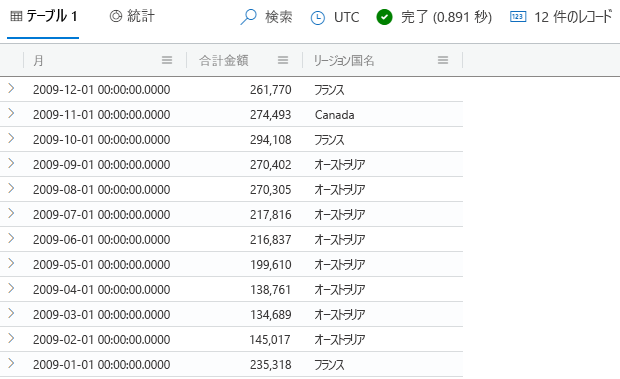
各行を確認します。 最初の列には前年の月が降順で表示され、その後、その月の売上が最も低い国/地域の総売上を示す列が続いていることがわかります。
join の rightouter の種類を使う
営業チームは、製品カテゴリごとの総売上を知りたいと考えています。 利用できるデータの確認を始めると、製品カテゴリの一覧を取得するには Products テーブルが必要であり、売上データを取得するには SalesFact テーブルが必要であることがわかりました。 また、各カテゴリの売上をカウントし、すべての製品カテゴリを一覧表示する必要があることがわかりました。
要求を分析した後、rightouter join を使用することにしました。これにより、右側のテーブルからすべての売上レコードが返され、左側のテーブルの一致するデータの製品カテゴリでエンリッチされるためです。 Products テーブルを左側のディメンション テーブルとして使用し、SalesFact ファクト テーブルからのデータを照合し、結果を製品カテゴリ別にグループ化するクエリを作成します。
次のクエリを実行します。
Products | join kind=rightouter SalesFact on ProductKey | summarize TotalSales = count() by ProductCategoryName | order by TotalSales desc結果は次の図のようになるはずです。
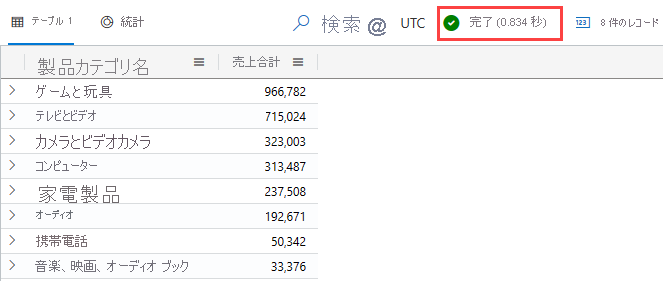
実行時間は 0.834 秒ですが、この時間は実行によって異なる場合があることに注目してください。 このクエリはこの答えを得る方法の 1 つであり、パフォーマンスのために最適化されていないクエリの良い例です。 後で、この時間と、この型のデータに最適化された、
lookup演算子を使用する同等のクエリの実行時間を比較できます。
join の rightanti の種類を使う
同様に、営業チームは、各製品カテゴリで販売されていない製品の数を知りたいと考えています。 rightanti join を使って、SalesFacts テーブルのどの行とも一致しない Products テーブルのすべての行を取得し、その結果を製品カテゴリ別にグループ化できます。
次のクエリを実行します。
SalesFact | join kind=rightanti Products on ProductKey | summarize Count = count() by ProductCategoryName | order by Count desc結果は次の図のようになるはずです。
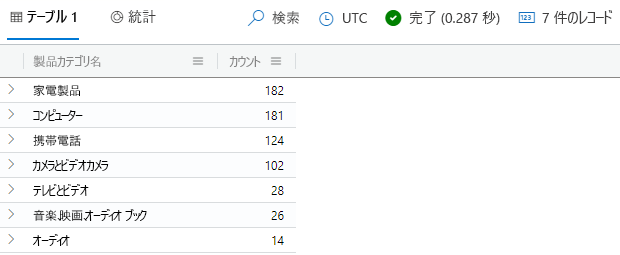
各行を確認します。 結果には、製品カテゴリごとの未販売製品の数が示されます。 rightanti
joinでは、売上ファクトがない製品のみが選択されることに注目してください。これは、join演算子によって返された製品の売上がなかったことを示しています。