高可用性とディザスター リカバリーを構成する
SQL Server でディザスター リカバリーと高可用性ソリューションを構成する場合、大部分は Azure Virtual Machine 上で実行される SQL Server でも同じです。 高可用性ソリューションは、コミット済みデータが障害によって失われないこと、ワークロードがメンテナンス操作の影響を受けないこと、データベースがソフトウェア アーキテクチャの単一障害点にならないことを保証するように設計されています。
ほとんどの Azure SQL サービス レベルでは、ローカル冗長からゾーン冗長モデルまで、さまざまな高可用性オプションを提供しています。
次に、Azure の PaaS オファリングのディザスター リカバリーと高可用性を実現するための具体的なソリューションを探ります。
継続的バックアップ
Azure SQL Database により、データベースの定期的かつ継続的バックアップが確実に行われます。その後に読み取りアクセス geo 冗長ストレージ (RA-GRS) にレプリケートされます。
毎週の完全バックアップ、12 時間から 24 時間ごとの差分バックアップ、5 分から 10 分ごとのトランザクション ログ バックアップが自動バックアップ戦略に含まれています。 バックアップの可用性を延長するために (最長 10 年間)、単一およびプールされたデータベースの両方に長期保有 (LTR) を構成できます。
長期保有 (LTR)
Azure には、通常の制限を超えて設定できるアイテム保持ポリシーが用意されています。これは長期保有が必要なシナリオに便利です。 保持ポリシーは最大 10 年間まで設定できます。このオプションは既定で無効になっています。

この画像は、Azure portal から長期保有ポリシーを設定する方法を示しています。 データベースを選ぶと、パネルの右側にパネルが表示されます。ここで既定の設定を変更できます。
長期保有の詳細については、「長期リテンション - Azure SQL Database と Azure SQL Managed Instance」を参照してください。
geo リストア
SQL Database と SQL Managed Instance のバックアップは、既定で geo 冗長です。 そのため、データベースを異なる地理的領域に簡単に復元することができます。あまり厳密ではないディザスター リカバリー シナリオに役立つ機能です。
バックアップ ストレージは、通常のデータベース ファイル ストレージとは別に課金されます。 ただし、SQL Database をプロビジョニングする際に、バックアップ ストレージは、データベースに対して選択されたデータ層の最大サイズで、追加コストなしで作成されます。
geo リストア操作の期間は、データベースのサイズ、復元操作に関係するトランザクション ログの数、ターゲット リージョンで同時に処理される復元要求の量など、いくつかの基になるコンポーネントの影響を受ける可能性があります。
ポイントインタイム復元 (PITR)
定義された保持期間に従ってデータベースを特定の時点に復元できますが、ポイントインタイム リストアがサポートされるのは、バックアップが開始されたのと同じサーバーにデータベースを復元する場合のみです。 SQL Database の復元には Azure portal、Azure PowerShell、Azure CLI、または REST API のいずれかを使用できます。
アクティブ geo レプリケーション
Azure SQL Database の可用性を向上させる方法の 1 つは、アクティブ geo レプリケーションを使うことです。 アクティブ geo レプリケーションでは、セカンダリ データベースのレプリカが別のリージョンに作成され、非同期的に最新の状態に保たれます。
このレプリカは、SQL Server の AlwaysOn 可用性グループと同様に読み取り可能です。 内部的には、Azure は可用性グループを使ってこの機能を維持しているので、用語の一部が似ています。
アクティブ geo レプリケーションは、大規模な災害時にプライマリ データベースをセカンダリ リージョンにプログラムまたは手動でフェールオーバーすることで、ビジネス継続性を実現しています。
Note
Azure SQL Managed Instance はアクティブ geo レプリケーションをサポートしていません。 代わりに自動フェールオーバー グループを使う必要があります。このトピックについては、このユニットで後ほど説明します。
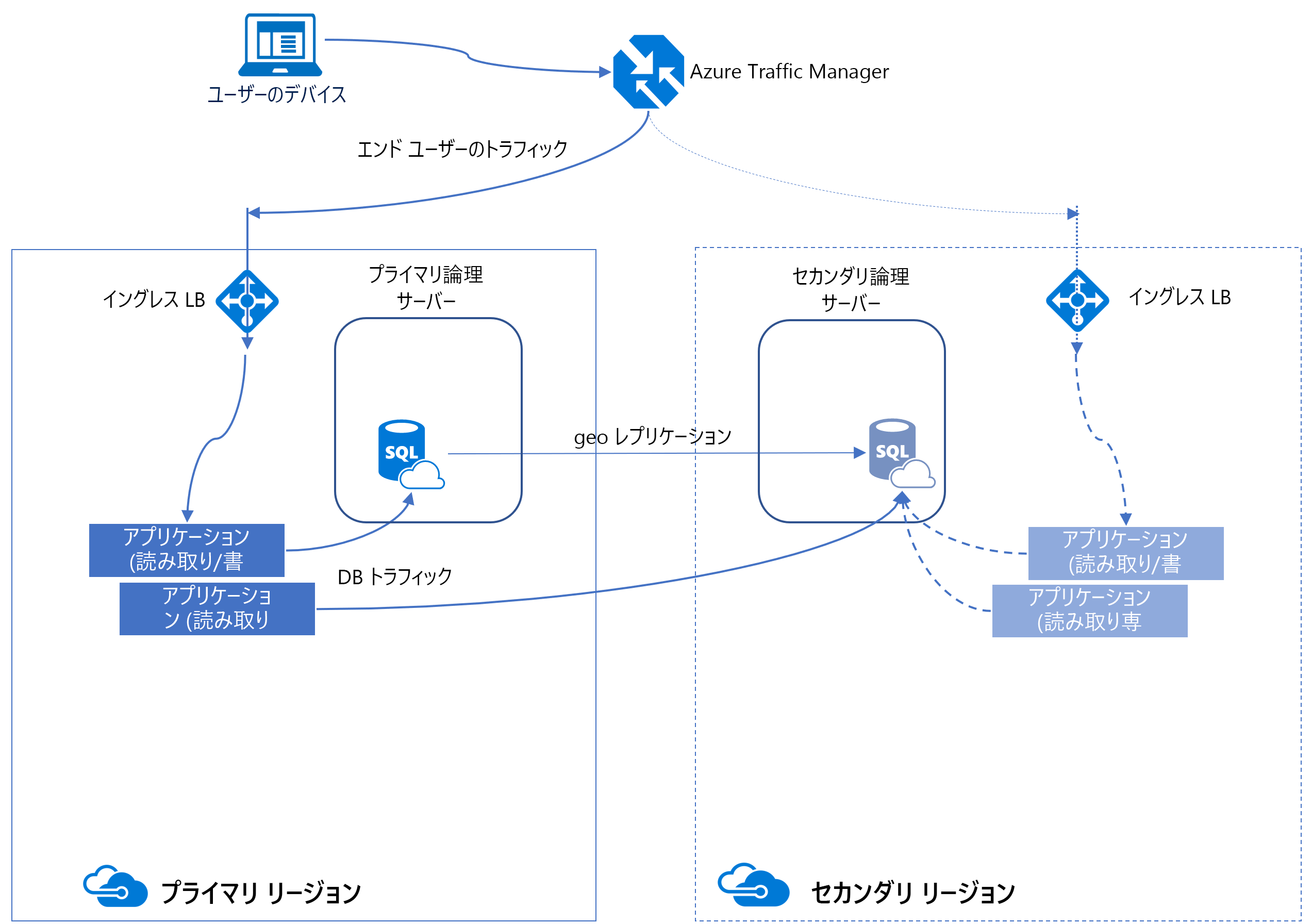
geo レプリケーションのリレーションシップに関わるすべてのデータベースは、同じサービス レベルを持つ必要があります。 さらに、大量の書き込みワークロードによるレプリケーション パフォーマンスの問題を防ぐために、プライマリと同じコンピューティング サイズでセカンダリ レプリカを構成することをお勧めします。

Azure SQL Database の geo レプリケーションを手動で構成するには、データベースのブレードにアクセスし、[データ管理] セクションで [レプリカ]、[+ レプリカの作成] の順に選びます。

セカンダリ レプリカを確立したら、手動でフェールオーバーを開始することもできます。 このプロセスでは、役割が逆転します。セカンダリ レプリカがプライマリの役割を引き継ぎ、元のプライマリがセカンダリになります。
サブスクリプション間 geo レプリケーション
シナリオによっては、プライマリ データベースとは異なるサブスクリプションでセカンダリ レプリカを構成する必要があります。 そこでサブスクリプション間 geo レプリケーションの機能が役立ちます。
Note
サブスクリプション間 geo レプリケーションは、プログラムでのみ使用できます。
サブスクリプション間 geo レプリケーションを構成するために必要な手順の詳細については、「サブスクリプション間 geo レプリケーション」を参照してください。
自動フェールオーバー グループ
自動フェールオーバー グループは、Azure SQL Database と Azure SQL Managed Instance の両方でサポートされている可用性機能です。 自動フェールオーバー グループを使うと、データベースを別のリージョンにレプリケートする方法と、フェールオーバーの開始方法を管理できます。 自動フェールオーバー グループに割り当てられる名前は、*.database.windows.net ドメイン内で一意である必要があります。
自動フェールオーバー グループには、複数のデータベースを含めることができます。 プライマリとセカンダリの両方のデータベース サイズは同じです。
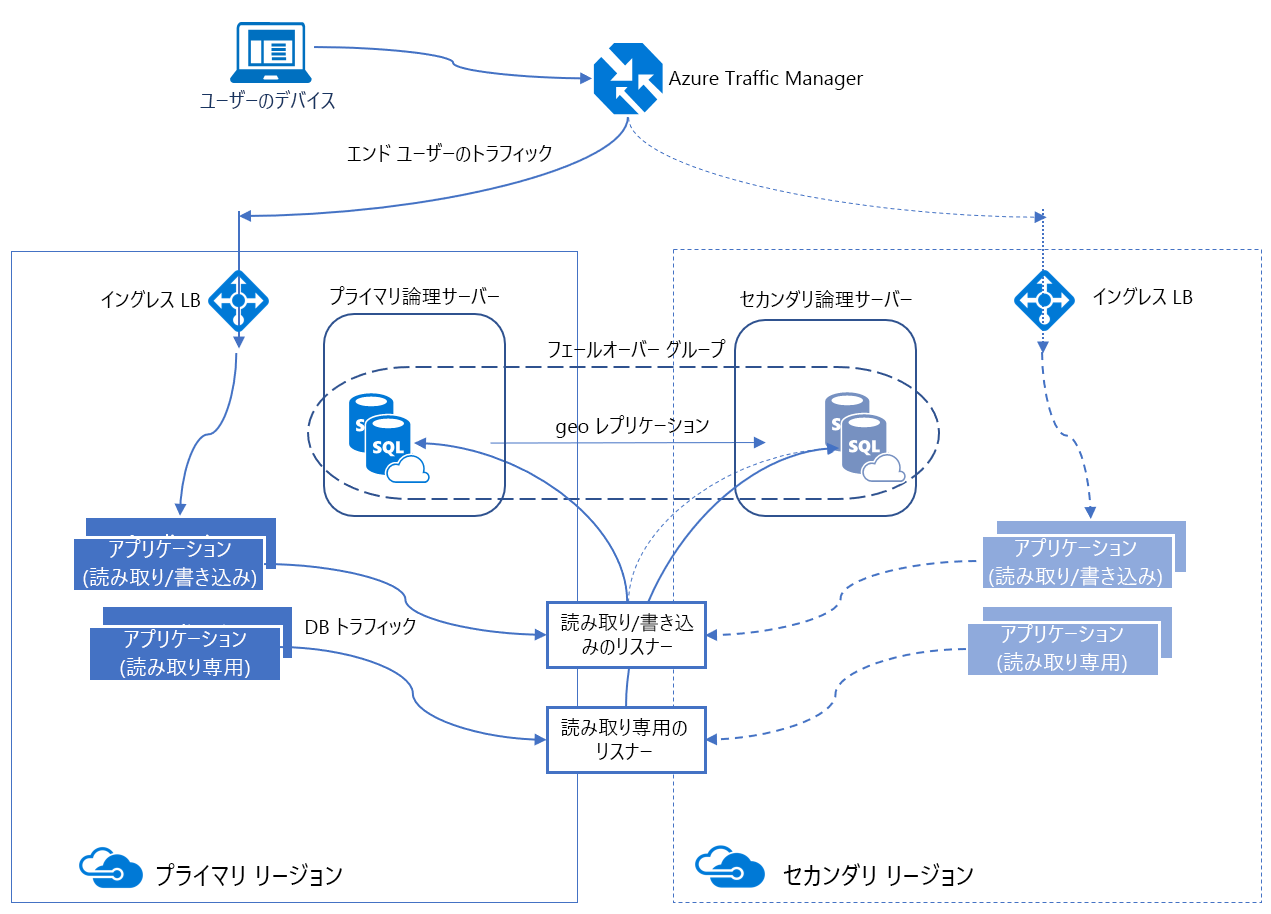
自動フェールオーバー グループは、リスナーと呼ばれる AG に似た機能を提供します。これにより、読み取りおよび書き込みアクティビティと読み取り専用アクティビティの両方が可能になります。 リスナーには、読み取りおよび書き込みトラフィック用と読み取り専用トラフィック用の 2 種類があります。 フェールオーバーの舞台裏で DNS が更新されるため、クライアントは抽象化されたリスナー名を指すことができ、他に何も知る必要はありません。 読み取りおよび書き込みコピーを含むデータベース サーバーがプライマリであり、プライマリからトランザクションを受信しているサーバーがセカンダリです。
自動フェールオーバー グループには 2 つの異なるポリシーがあります。
| ポリシー タイプ | 説明 |
|---|---|
| 自動 | 障害が検出されると、システムは既定でフェールオーバーを自動的にトリガーします。 ただし、必要に応じて、自動フェールオーバーを無効にすることができます。 |
| 読み取り専用 | フェールオーバー中は、セカンダリがダウンしたとき新しいプライマリのパフォーマンスを維持するために、エンジンによって既定で読み取り専用リスナーが無効にされます。 ただし、この動作を変更して、フェールオーバー後に両方の種類のトラフィックを許可することもできます。 |
フェールオーバーは、自動フェールオーバーが有効になっている場合でも手動で開始できるプロセスです。 ただし、フェールオーバーの種類によって、データ損失が発生するかどうかに影響する可能性があります。 たとえば、計画外のフェールオーバーが強制的に実行され、セカンダリ データベースがプライマリ データベースと完全に同期していない場合、データ損失が発生する可能性があります。
GracePeriodWithDataLossHours には、Azure がフェールオーバーを開始するまでの待機時間を指定します。既定値 1 時間に設定されています。 回復ポイントの目標 (RPO) が厳格で、データ損失を許容できない場合は、この値を高く設定できます。 これは、Azure がフェールオーバーを開始するまでの待機時間が長くなることを意味しますが、セカンダリ データベースがプライマリと完全に同期するための時間が長くなるため、データ損失を削減できる可能性があります。
Note
セカンダリ データベースは、シード処理というプロセスを通じて自動的に作成されますが、データベースのサイズによっては時間がかかる場合があります。 そのため、ネットワーク速度などの要因を考慮して、事前に計画することが重要です。
Azure SQL Database の高可用性とディザスター リカバリーの詳細については、「Azure SQL Database の高可用性とディザスター リカバリーのチェックリスト」を参照してください。