ソリューション アーキテクチャを調べる
行おうとしていることの目的を理解するため、機械学習操作 (MLOps) のアーキテクチャを変更しましょう。
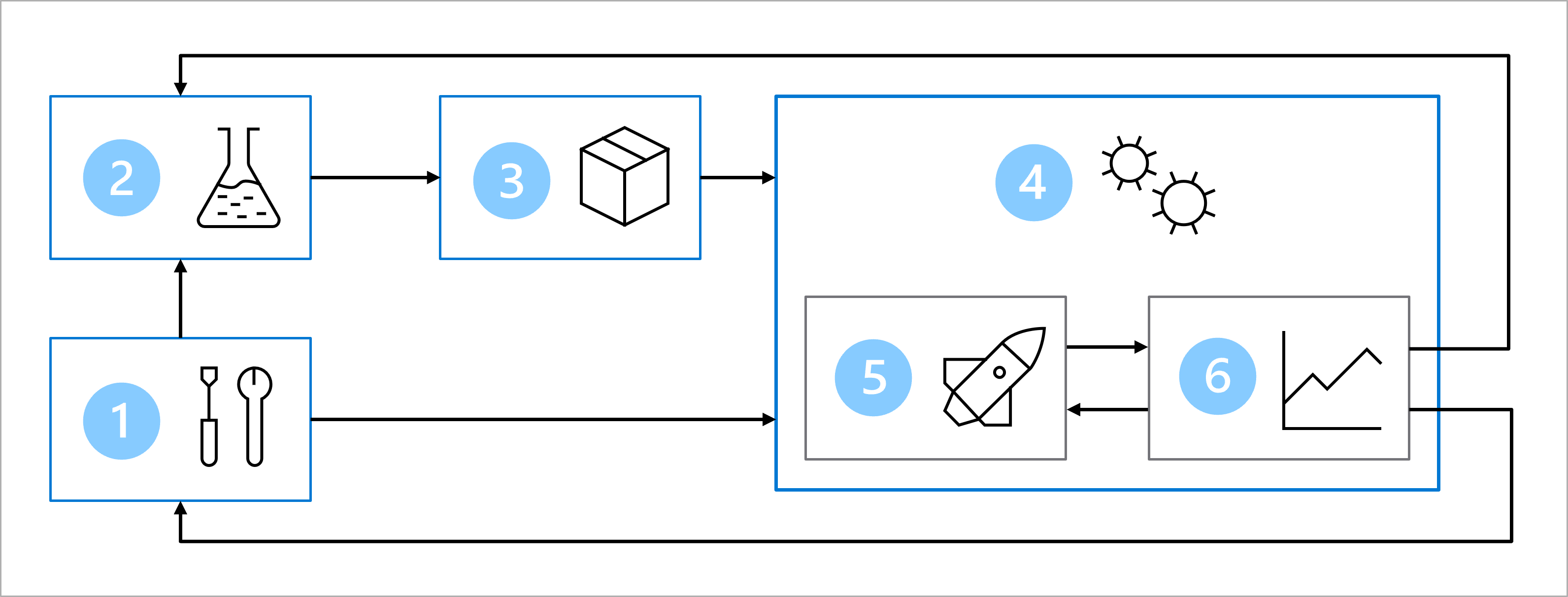
あなたは、データ サイエンスとソフトウェア開発のチームと共に、糖尿病分類モデルをトレーニング、テスト、デプロイするために次のアーキテクチャに同意したとします。
Note
この図は、MLOps アーキテクチャを簡略化したものです。 より詳細なアーキテクチャを表示するには、MLOps (v2) ソリューション アクセラレータのさまざまなユース ケースをご確認ください。
アーキテクチャには次のものが含まれます。
- セットアップ: ソリューションに必要なすべての Azure リソースを作成します。
- モデル開発 (内部ループ): モデルをトレーニングおよび評価するためのデータを探して処理します。
- 継続的インテグレーション: モデルをパッケージ化して登録します。
- モデル デプロイ (外部ループ): モデルをデプロイします。
- 継続的デプロイ: モデルをテストし、運用環境にレベル上げします。
- 監視: モデルとエンドポイントのパフォーマンスを監視します。
データ サイエンス チームは、モデルの開発を担当します。 ソフトウェア開発チームは、デプロイされたモデルと、患者が糖尿病にかかっているかどうかを評価するために開業医が使う Web アプリの統合を担当します。 あなたは、モデルの開発からモデルのデプロイにモデルを取得する責任があります。
あなたは、データ サイエンス チームが、モデルのトレーニングに使われるスクリプトに対する変更を継続的に提案するものと期待しています。 トレーニング スクリプトが変更されるたびに、あなたはモデルを再トレーニングし、既存のエンドポイントにモデルを再デプロイする必要があります。
あなたは、データ サイエンス チームが、運用環境への準備ができたコードに触れることなく、実験できるようにすることを考えています。 また、新しいコードまたは更新されたコードに、合意された品質チェックが自動的に行われるようにすることも望んでいます。 あなたは、モデルをトレーニングするためのコードを検証した後、更新されたトレーニング スクリプトを使って新しいモデルをトレーニングし、それをデプロイします。
変更を追跡し、運用コードを更新する前にコードを検証するには、ブランチを操作する "必要" があります。 あなたとデータ サイエンス チームは、変更を行う必要があるたびに、チームが機能ブランチを作成し、コードのコピーを作成して、コピーを変更することに同意しました。
データ科学者は誰でも、機能ブランチを作成してそこで作業できます。 コードを更新し、そのコードを新しい運用コードにしたい場合は、pull request を作成する必要があります。 pull request で、他のユーザーは、提案されている変更の内容を見ることができ、変更を確認して議論する機会が得られます。
pull request が作成されるたびに、コードが機能するかどうか、およびコードの品質が組織の標準に達していることが、自動的にチェックされる必要があります。 コードが品質チェックに合格した後は、データ科学者のリーダーが変更を確認し、更新を承認する必要があり、その後で pull request をマージし、それに応じてメイン ブランチのコードを更新することができます。
重要
メイン ブランチに変更をプッシュすることは、誰にも許可してはなりません。 コード (特に運用コード) を保護するため、承認される必要のある pull request を通じてのみメイン ブランチを更新できるように、強制する必要があります。