Apache Spark の理解を深める
Apache Spark は、クラスター内の複数の処理ノード間で作業を調整することで大規模なデータ分析を可能にする分散データ処理フレームワークです。
Spark のしくみ
Apache Spark アプリケーションは、メイン プログラム (ドライバー プログラムと呼ばれる) の SparkContext オブジェクトによって調整された、独立したプロセスのセットとしてクラスターで実行されます。 SparkContext は、Apache Hadoop YARN の実装を使用してアプリケーション間でリソースを割り当てるクラスター マネージャーに接続します。 接続されると、Spark はクラスター内のノードで Executor を取得してアプリケーション コードを実行します。
SparkContext は、クラスター ノードで main 関数と並列操作を実行し、操作の結果を収集します。 ノードは、ファイル システムとの間でデータの読み取りと書き込みを行い、変換されたデータを 耐障害性分散データセット (RDD) としてメモリ内にキャッシュします。
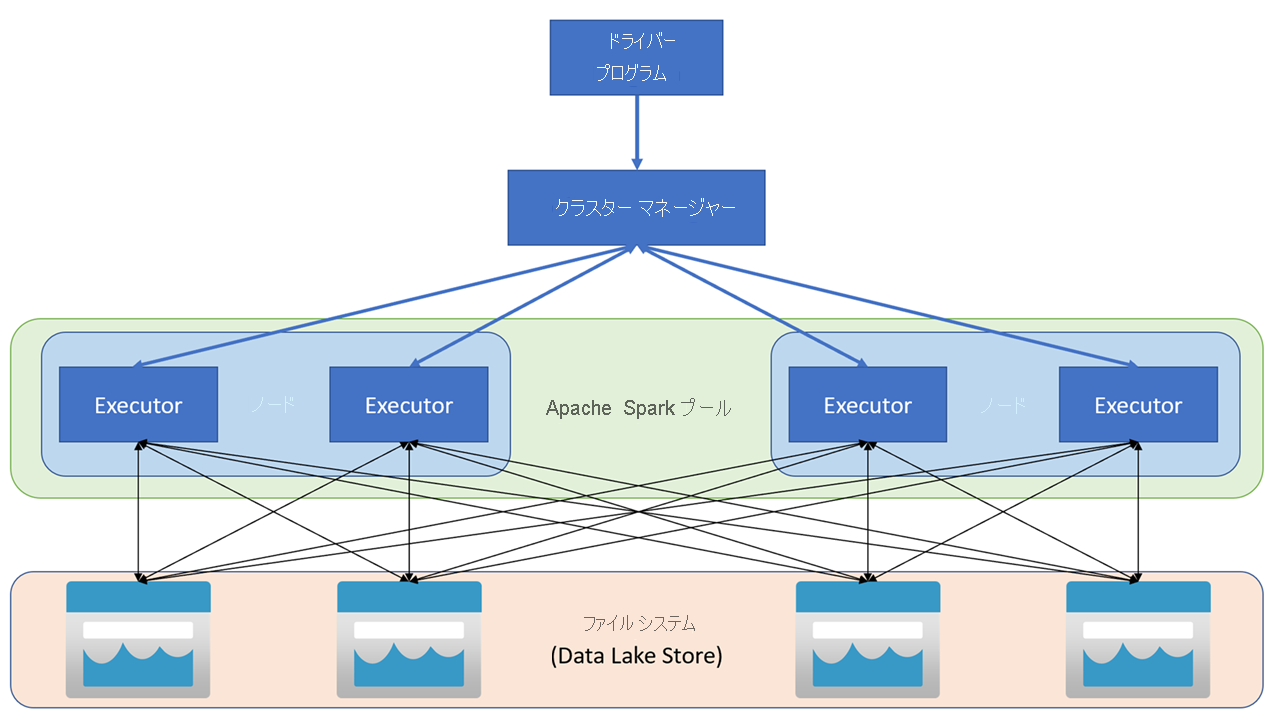
SparkContext は、アプリケーションを 有向非巡回グラフ (DAG) に変換する処理を担います。 グラフは、ノードの Executor プロセス内で実行される個々のタスクから成ります。 アプリケーションはそれぞれ独自の Executor プロセスを取得し、そのプロセスが、アプリケーション全体が終了するまで稼働し続けながら、複数のスレッドでタスクを実行します。
Azure Synapse Analytics の Spark プール
Azure Synapse Analytics では、クラスターが "Spark プール" として実装され、Spark 操作のランタイムが提供されます。 Azure portal を使用するか、Azure Synapse Studio で、Azure Synapse Analytics ワークスペースに 1 つ以上の Spark プールを作成できます。 Spark プールを定義するときに、プールの構成オプションを次のように指定できます。
- Spark プールの名前。
- ハードウェア アクセラレータ GPU 対応ノードを使用するオプションなど、プール内のノードに使用される仮想マシン (VM) のサイズ。
- プール内のノードの数、およびプール サイズが固定されているか、または個々のノードを動的にオンラインにしてクラスターを "自動スケーリング" でき、その場合に、アクティブ ノードの最小数と最大数を指定できるかどうか。
- プールで使用される "Spark ランタイム" のバージョン。これにより、Python、Java、インストールされるその他のコンポーネントなどの個々のコンポーネントのバージョンが決定されます。
ヒント
Spark プールの構成オプションの詳細については、Azure Synapse Analytics のドキュメントの「Azure Synapse Analytics での Apache Spark プールの構成」を参照してください。
Azure Synapse Analytics ワークスペース内の Spark プールは "サーバーレス" であり、オンデマンドで開始され、アイドル状態になると停止します。