ソリューション アーキテクチャを調べる
作業を始める前に、アーキテクチャを調べてすべての要件を理解しましょう。 モデルを運用環境に導入するには、ソリューションをスケーリングし、他のチームと連携する必要があります。 データ サイエンティスト、データ エンジニア、インフラストラクチャ チームと共に、次のアプローチを使用することにしました。
- すべてのデータは Azure Blob Storage に格納され、データ エンジニアによって管理されることになります。
- インフラストラクチャ チームでは、Azure Machine Learning ワークスペースなどの必要な Azure リソースを作成します。
- データ サイエンティストは、内部ループ (モデルの開発とトレーニング) に焦点を当てます。
- 機械学習エンジニアは、トレーニング済みのモデルを取得し、外部ループにデプロイします。
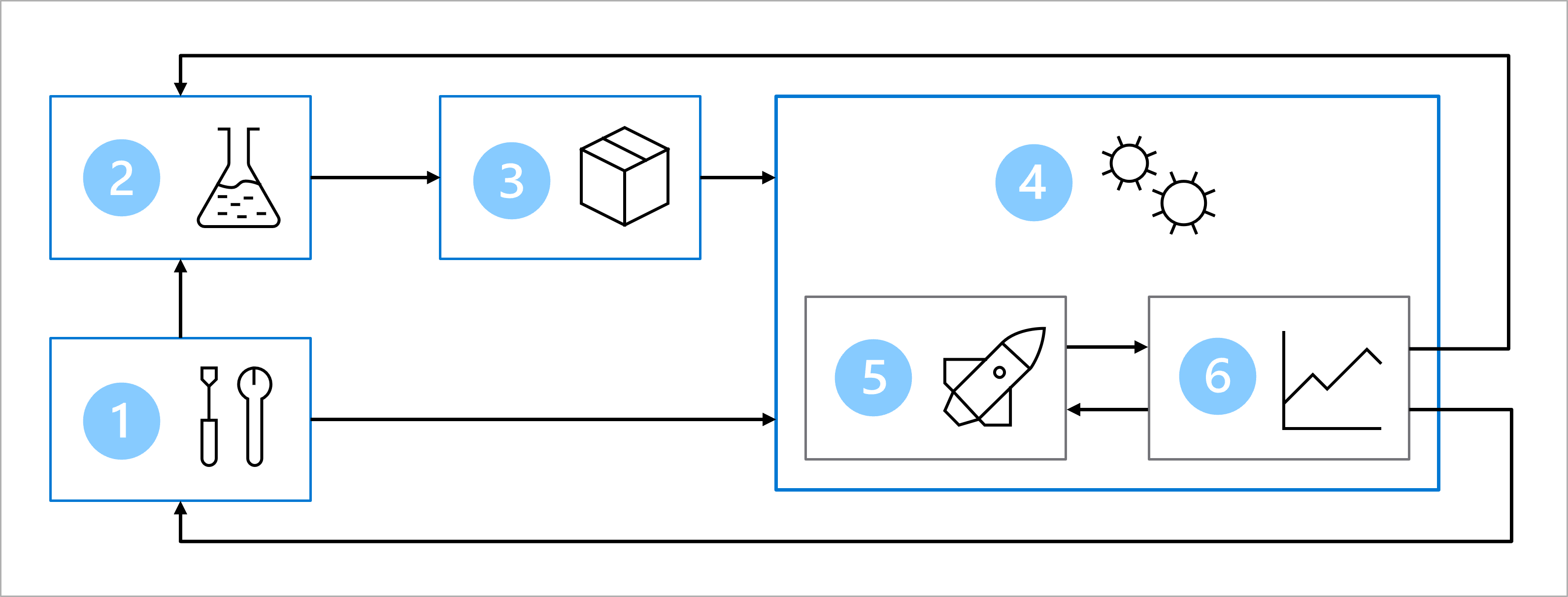
より大規模なチームと共に、機械学習運用 (MLOps) を実現するためのアーキテクチャを設計しました。
Note
この図は、MLOps アーキテクチャを簡略化したものです。 より詳細なアーキテクチャを表示するには、MLOps (v2) ソリューション アクセラレータのさまざまなユース ケースをご確認ください。
MLOps アーキテクチャの主な目標は、堅牢で再現可能なソリューションを作成することです。 これを実現するために、アーキテクチャに次のものが含まれます。
- セットアップ: ソリューションに必要なすべての Azure リソースを作成します。
- モデル開発 (内部ループ): モデルをトレーニングおよび評価するためのデータを探して処理します。
- 継続的インテグレーション: モデルをパッケージ化して登録します。
- モデル デプロイ (外部ループ): モデルをデプロイします。
- 継続的デプロイ: モデルをテストし、運用環境にレベル上げします。
- 監視: モデルとエンドポイントのパフォーマンスを監視します。
プロジェクトのこの時点で、Azure Machine Learning ワークスペースが作成され、データが Azure Blob Storage に格納され、データ サイエンス チームがモデルをトレーニングしました。
モデルを運用環境にデプロイすることで、内部ループとモデル開発から外部ループに移行したいと考えています。 そのため、データ サイエンス チームの出力を Azure Machine Learning の堅牢で再現可能なパイプラインに変換する必要があります。
確実にすべてのコードをスクリプトとして格納し、Azure Machine Learning ジョブとしてスクリプトを実行することで、モデルのトレーニングを自動化し、今後、モデルを再トレーニングすることが容易になります。
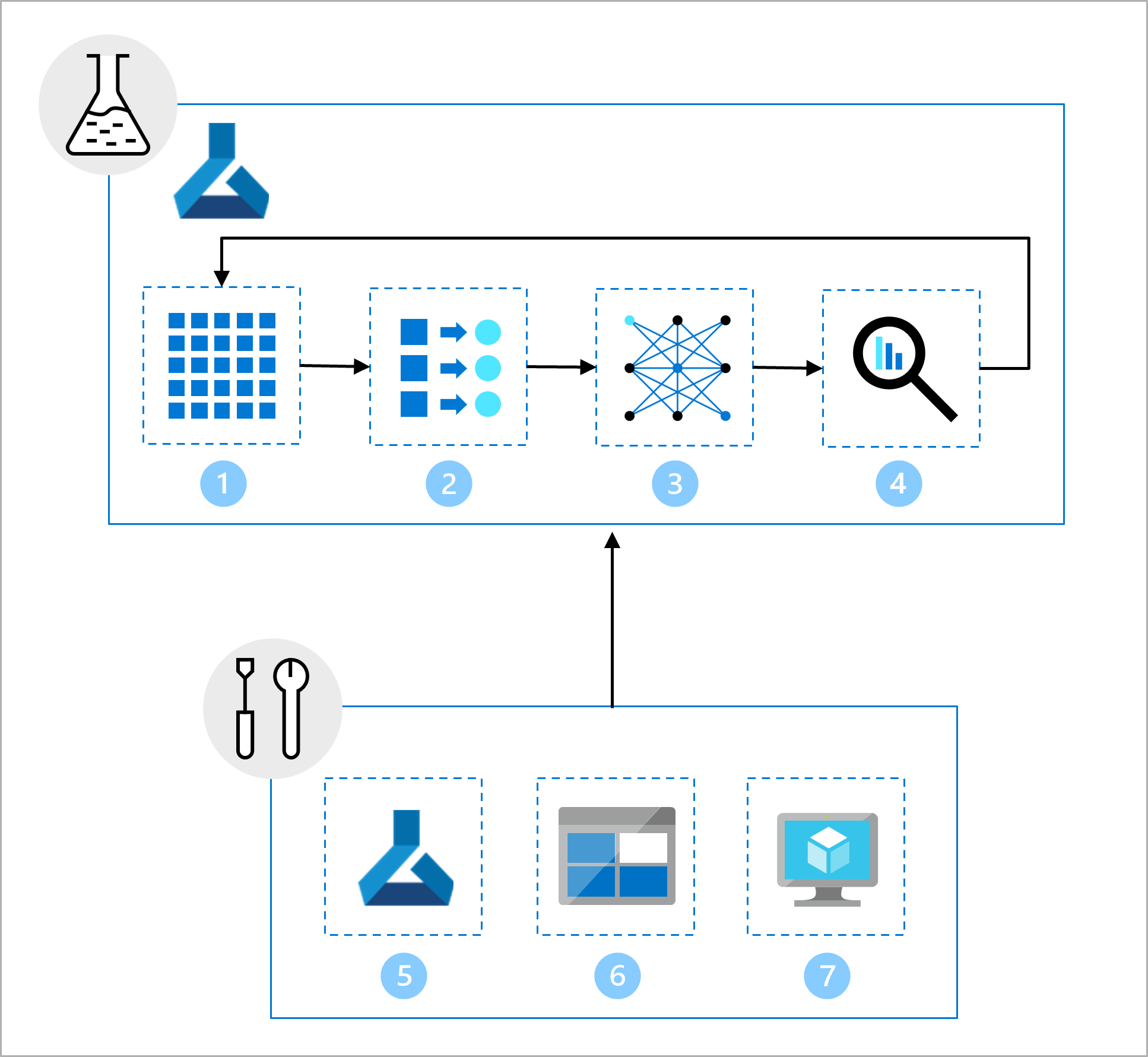
データ サイエンス チームはモデル開発に取り組んできました。 次のタスクを含む Jupyter Notebook が提供されます。
- データを読み取って探索します。
- 特徴エンジニアリングを実行する。
- モデルをトレーニングする。
- モデルを評価します。
セットアップの一環として、インフラストラクチャ チームは以下を作成しました。
- 探索と実験のためにデータ サイエンス チームが使用できる Azure Machine Learning 開発 (dev) ワークスペース。
- ワークスペース内のデータ資産。データを含む Azure Blob Storage 内のフォルダーを指します。
- Notebook とスクリプトを実行するために必要なコンピューティング リソース。
MLOps に向けた最初のタスクは、モデル開発を簡単に自動化できるように、データ サイエンティストからの作業を変換することです。 データ サイエンス チームが Jupyter Notebook で作業していたのに対し、あなたはスクリプトを使用し、Azure Machine Learning ジョブを使って実行する必要があります。 ジョブの入力は、Azure Machine Learning ワークスペースに接続された、Azure Blob Storage 上に存在するデータを指すインフラストラクチャ チームによって作成されたデータ資産になります。