適切なコンピューティング先を選択する
Azure Machine Learning では、"コンピューティング先" とは、その場所でジョブが実行される物理または仮想コンピューターです。
使用可能なコンピューティングの種類について
Azure Machine Learning では、実験、トレーニング、デプロイのために複数の種類のコンピューティングがサポートされています。 複数の種類のコンピューティングを用意することで、ニーズに適した種類のコンピューティング先を選択できます。
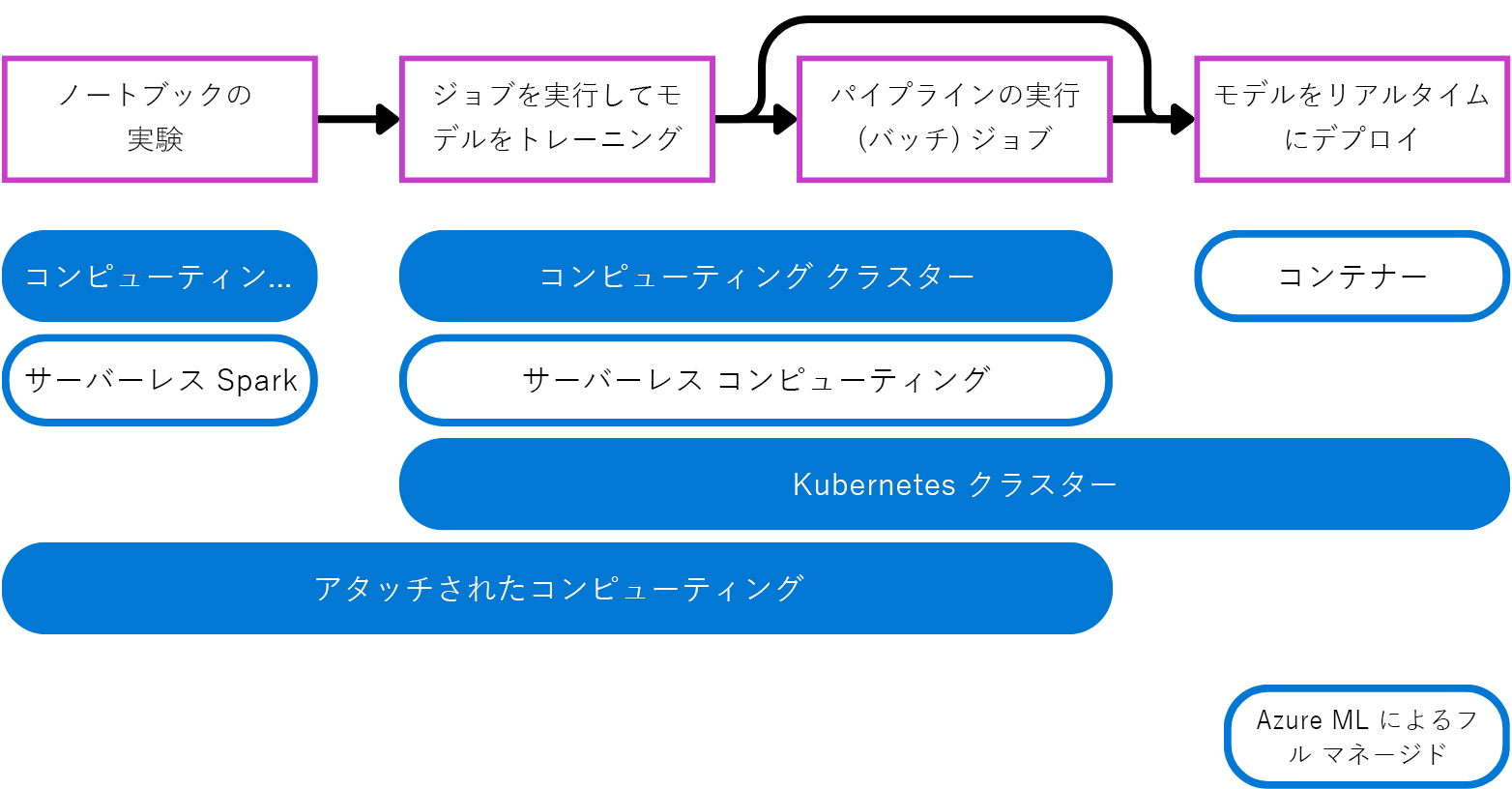
- コンピューティング インスタンス: 仮想マシンと同様に動作し、主にノートブックを実行するのに使用されます。 これは、"実験" に最適です。
- コンピューティング クラスター: 需要に合わせて自動的にスケールアップまたはスケールダウンする仮想マシンのマルチノード クラスターです。 大量のデータを処理する必要があるスクリプトを実行するのに適したコスト効率の高い方法。 クラスターを使用すれば、並列処理によってワークロードを分散し、スクリプトの実行にかかる時間を短縮することもできます。
- Kubernetes クラスター: Kubernetes テクノロジに基づくクラスター。コンピューティングの構成と管理方法をより細かく制御できます。 クラウド コンピューティング用のセルフマネージド Azure Kubernetes (AKS) クラスター、またはオンプレミス ワークロード用の Arc Kubernetes クラスターをアタッチできます。
- アタッチ型コンピューティング:Azure 仮想マシンや Azure Databricks クラスターなどの既存のコンピューティングをワークスペースにアタッチできます。
- サーバーレス コンピューティング: トレーニング ジョブに使用できるフル マネージドのオンデマンド コンピューティング。
Note
Azure Machine Learning には、独自のコンピューティングを作成して管理するオプションや、Azure Machine Learning によるフル マネージドのコンピューティングを使用するオプションが用意されています。
どの種類のコンピューティングをいつ使用しますか?
一般に、コンピューティング先を操作する際に採用できるベスト プラクティスがいくつかあります。 適切な種類のコンピューティングを選択する方法を理解するために、いくつかの例が用意されています。 どの種類のコンピューティングを使用するかは、毎回ご自分の特定の状況によって異なることに注意してください。
実験用のコンピューティング先を選択する
あなたはデータ科学者であり、新しい機械学習モデルを開発するように依頼されたとします。 実験できるトレーニング データの小さなサブセットが存在するとします。
実験と開発中は Jupyter Notebook で作業する方がいいと考えています。 ノートブック エクスペリエンスは、継続的に実行されているコンピューティングから最も恩恵を受けます。
多くのデータ科学者は、ローカル デバイスでのノートブックの実行に精通しています。 Azure Machine Learning で管理されるクラウドの代替手段は、コンピューティング インスタンスです。 または、Spark の分散コンピューティング能力を利用する場合は、Spark サーバーレス コンピューティングを選択して、ノートブックで Spark コードを実行することもできます。
運用環境のコンピューティング先を選択する
実験の後、Python スクリプトを実行してモデルをトレーニングすることで、運用環境に備えることができます。 スクリプトを使用すれば、時間の経過に伴ってモデルを継続的に再トレーニングするタイミングを、容易に自動化してスケジュールすることができます。 (パイプライン) ジョブとしてスクリプトを実行できます。
運用環境に移行する場合は、コンピューティング先で大量のデータを処理する準備を整える必要があります。 使用するデータが多いほど、機械学習モデルは精度が向上する可能性があります。
スクリプトを使用してモデルをトレーニングする場合は、オンデマンドのコンピューティング先が必要です。 コンピューティング クラスターは、スクリプトを実行する必要があるときに自動的にスケールアップされ、スクリプトの実行が完了するとスケールダウンされます。 作成して管理する必要のない代替手段が必要な場合は、Azure Machine Learning のサーバーレス コンピューティングを使用できます。
デプロイのコンピューティング先を選択する
モデルを使用して予測を生成するときに必要なコンピューティングのタイプは、バッチ予測とリアルタイム予測のどちらを使用するかによって異なります。
バッチ予測の場合は、Azure Machine Learning でパイプライン ジョブを実行できます。 コンピューティング クラスターや Azure Machine Learning のサーバーレス コンピューティングなどのコンピューティング先は、オンデマンドでスケーラブルなパイプライン ジョブに適しています。
リアルタイム予測が必要な場合は、継続的に実行されているコンピューティングのタイプが必要です。 そのため、リアルタイム デプロイは、より軽量な (したがってコスト効率の高い) コンピューティングのメリットを得られるのです。 Containers は、リアルタイムデプロイに適しています。 マネージド オンライン エンドポイントにモデルをデプロイする場合、Azure Machine Learning によって、モデルを実行するための Containers が作成および管理されます。 または、Kubernetes クラスターをアタッチして、リアルタイム予測の生成に必要なコンピューティングを管理することもできます。