Always On可用性グループでのログ送信キューのトラブルシューティング
この記事では、ログ送信キューに関連する問題の解決策について説明します。
ログ送信キューとは
プライマリ レプリカ上の可用性グループ データベース (、UPDATE、 DELETEなどINSERT) に加えられた変更は、トランザクション ログに書き込まれ、可用性グループのセカンダリ レプリカに送信されます。
ログ送信キューは、セカンダリ レプリカに送信されていないプライマリ データベースのログ ファイル内のログ レコードの数を定義します。
ログ送信キューの症状と影響
ログ送信キューには、脆弱なすべてのデータが格納されます
突然の障害でプライマリ レプリカが失われ、これらの変更がまだ到着していないセカンダリ レプリカにフェールオーバーした場合、それらの変更はデータベースの新しいプライマリ レプリカ コピーには表示されません。 これにより、データベースとログの完全バックアップの実行時に保存される変更は除外されます。
ログ送信キューの増加により、トランザクション ログ ファイルの増加が発生する
可用性グループで定義されているデータベースの場合、Microsoft SQL Serverは、セカンダリ レプリカにまだ配信されていないトランザクション ログ内のすべてのトランザクションをプライマリ レプリカに保持する必要があります。 ログ送信キューは、通常のログ切り捨てイベント中 (データベース ログ バックアップ中など) に切り捨てることができない、プライマリ レプリカでログに記録された変更の量を表します。 大きく増大するログ送信キューは、データベース ログ ファイルをホストするドライブ上の空き領域を使い果たす可能性があります。また、構成されている最大トランザクション ログ ファイル サイズを超える可能性があります。 詳細については、「 トランザクション ログが大きい場合のエラー 9002」を参照してください。
さまざまな診断機能レポート可用性グループ ログ送信キュー
SQL Server Management StudioのAlways On ダッシュボードは、ログ送信キューに関するレポートを表示します。 可用性グループが異常であると報告される場合があります。
ログ送信キューのチェック方法
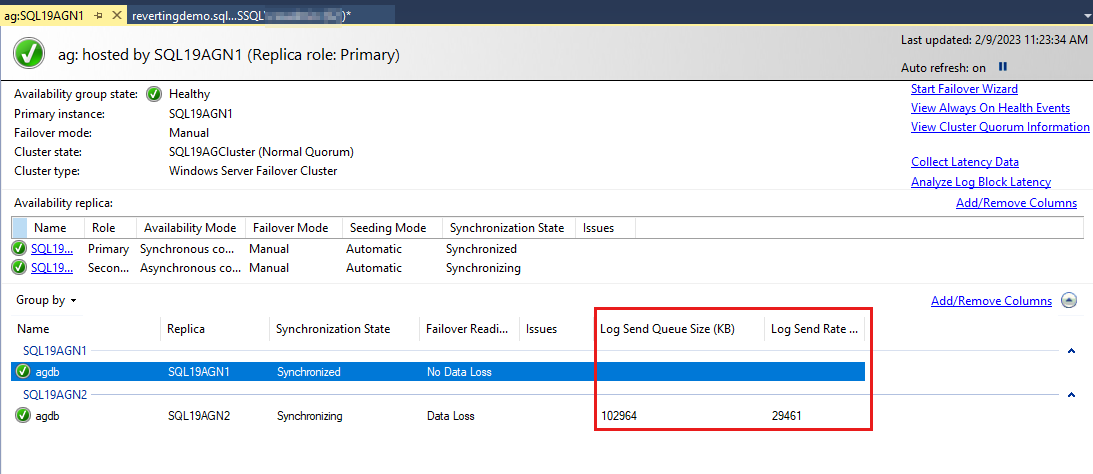
ログ送信キューは、データベースごとの測定値です。 この値をチェックするには、プライマリ レプリカのAlways On ダッシュボードを使用するか、プライマリレプリカまたはセカンダリ レプリカのsys.dm_hadr_database_replica_states動的管理ビュー (DMV) を使用します。 パフォーマンス モニター カウンターは、セカンダリ レプリカに対するログ送信キューのチェックに使用されます。
次のいくつかのセクションでは、可用性グループ データベース ログ送信キューをアクティブに監視する方法について説明します。
クエリ sys.dm_hadr_database_replica_state
DMV は sys.dm_hadr_database_replica_states 、各可用性グループ データベースの行を報告します。 そのレポートの 1 つの列は です log_send_queue_size。 この値は、ログ送信キューのサイズ (KB) です。 次のクエリなどのクエリを設定して、ログ送信キューのサイズの傾向を監視できます。 クエリはプライマリ レプリカで実行されます。 述語を is_local=0 使用して、セカンダリ レプリカのデータを報告します。ここで log_send_queue_size と log_send_rate が関連します。
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
出力の外観を次に示します。

ダッシュボードでログ送信キュー Always On確認する
ログ送信キューを確認するには、次の手順に従います。
SSMS オブジェクト エクスプローラーの可用性グループを右クリックして、SQL Server Management Studio (SSMS) でAlways On ダッシュボードを開きます。
[ ダッシュボードの表示] を選択します。
可用性グループ データベースは最後に一覧表示され、データベースに関していくつかのデータが報告されます。 ログ送信キューサイズ (KB) とログ送信速度 (KB/秒) は既定では一覧表示されませんが、次の手順のスクリーンショットに示すように、このビューに追加できます。
これらの列を追加するには、可用性グループ データベース列ヘッダーを右クリックし、使用可能な列の一覧から選択します。
ログ送信キューサイズを追加するには、次のスクリーンショットで赤で強調表示されているヘッダーを右クリックします。
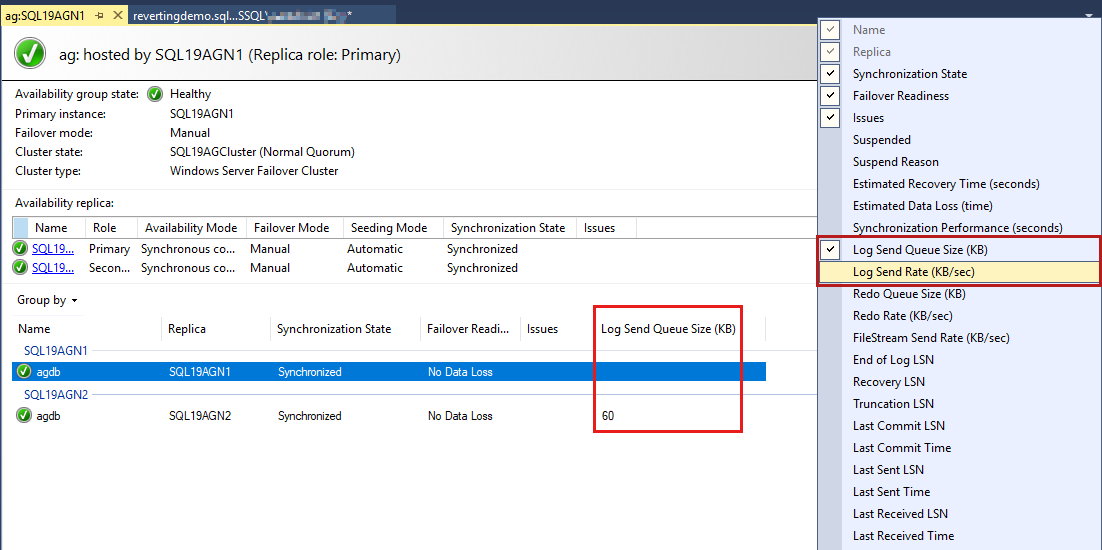
既定では、Always On ダッシュボードでは、このデータが 60 秒ごとに自動更新されます。


パフォーマンス モニターのログ送信キューを確認する
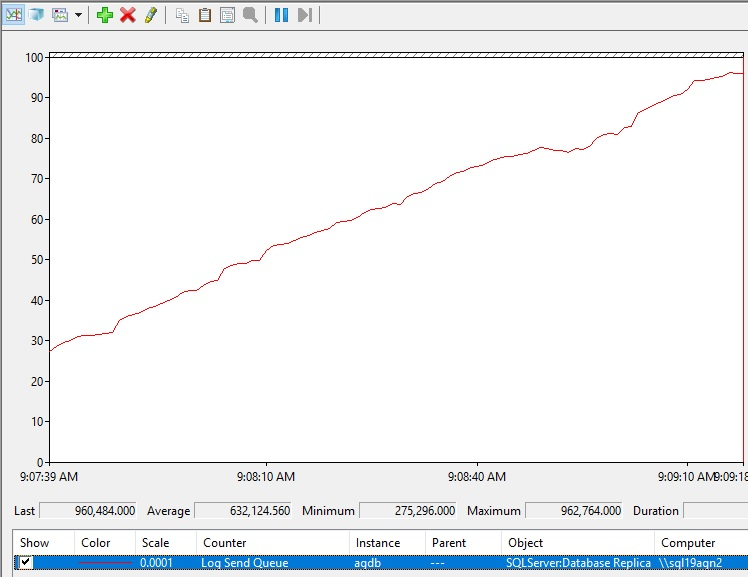
ログ送信キューは、各セカンダリ レプリカ データベースに固有です。 そのため、可用性グループ データベースのログ送信キューを確認するには、次の手順に従います。
セカンダリ レプリカでパフォーマンス モニターを開きます。
[ 追加 (カウンター)] ボタンを選択します。
[ 使用可能なカウンター] で、 SQLServer:Database Replica カウンターと Log Send Queue カウンターを 選択します。
[インスタンス] リスト ボックスで、ログ送信キューにチェックする可用性グループ データベースを選択します。
[ 追加] を選択し 、[OK] を選択します。
ログ送信キューの増加は次のようになります。

ログ送信キュー値の解釈
このセクションでは、ログ送信キュー サイズの値を解釈する方法について説明します。
ログ送信キューが正しくないのはいつですか? 許容されるログ送信キューの量
ログ送信キューが値 0 を報告している場合は、そのレポートの時点でログ送信キューが発生していないと仮定する場合があります。 ただし、運用環境がビジー状態の場合は、正常な AlwaysOn 環境であっても、ログ送信キューが 0 以外の値を頻繁に報告することを想定する必要があります。 一般的な運用環境では、この値が 0 から 0 以外の値の間で変動することを想定する必要があります。
ログ送信キューが時間の経過と同時に増加している場合は、さらなる調査が必要です。 この追加のアクティビティは、何かが変更されたことを示します。 ログ送信キューが急激に増加する場合は、トラブルシューティングに次の測定値が役立ちます。
- ログ送信速度 (KB/秒) (AlwaysOn ダッシュボード)
- sys.dm_hadr_database_replica_states (DMV)
- データベース レプリカ::Mirrored Transactions/sec (パフォーマンス モニター)
ログ送信レートとミラー化されたトランザクション/秒のベースライン レートを取得する
正常な AlwaysOn パフォーマンスの間は、ビジー状態の可用性グループ データベースの ログ送信速度 と ミラー化されたトランザクション/秒 の値を監視します。 一般的に忙しい営業時間の間、彼らはどのように見えますか? 大規模なトランザクションによってシステムのトランザクション スループットが高くなると、メンテナンス期間中はどのように表示されますか? ログ送信キューの増加を観察すると、これらの値を比較して、何が変更されたかを判断できます。 ワークロードが通常よりも大きくなる可能性があります。 ログ送信速度が通常よりも低い場合は、理由を特定するためにさらに調査が必要になる場合があります。
ワークロード ボリュームが重要
大規模なワークロード (100 万行に対するステートメント、1 テラバイト テーブルでのインデックスの再構築、数百万行を挿入している ETL バッチなど UPDATE ) がある場合は、すぐにまたは時間の経過と同時にログ送信キューの増加が予想されます。 これは、可用性グループ データベースで多数の変更が突然行われた場合に予想されます。
ログ送信キューを診断する方法
特定の可用性グループ データベースのログ送信キューを特定した後、次のセクションで説明するように、問題の根本原因として考えられるいくつかの異なるチェックする必要があります。
重要
意味のある待機の種類の出力の場合は、次の条件を監視するときに、前のセクションで説明した方法のいずれかを使用して、ログ送信キューの増加をチェックします。
システムがビジーすぎる
プライマリ レプリカのワークロードがシステムの CPU をオーバーロードしているかどうかを確認します。 ログ送信キューが増える場合は、DMV に対してクエリを sys.dm_os_schedulers 実行し、 を監視します high runnable_tasks_count。 この数は、その時点で実行された未処理のタスクを示します。
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
次の表は、結果のサンプルです。 値の runnable_tasks_count 増加は、多数のタスクが CPU 時間を待機していることを示します。
| scheduler_address | scheduler_id | cpu_id | status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | オフラインで表示 | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBLE ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBLE ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBLE ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBLE ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBLE ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBLE ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | 表示 | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBLE ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBLE ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBLE ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBLE ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBLE ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBLE ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBLE ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBLE ONLINE | 104 | 16 | 116 | 103 |
解決策: 高い runnable_task_countを検出した場合は、システムのワークロードを減らすか、システムで使用できる CPU の数を増やします。
ネットワーク待機時間
この状態は、セカンダリ レプリカがプライマリ レプリカから物理的にリモートである場合に特に一般的です。 マルチサイト可用性グループを使用すると、ディザスター リカバリーとレポートのために、複数のサイトにビジネス データのコピーを展開できます。 これにより、リモートの場所にある運用データのコピーでほぼリアルタイムの変更を使用できるようになります。
セカンダリ レプリカがプライマリ レプリカから遠く離れた場所でホストされている場合、ネットワーク待機時間と、プライマリ レプリカ データベースで生成されるのと同じくらい高速にリモート セカンダリに変更を送信できないことが原因で、ログ送信キューが発生する可能性があります。
重要
SQL Serverは、1 つの接続を使用して、プライマリからセカンダリ レプリカへの変更を同期します。 そのため、セカンダリ レプリカがリモートの場合、パイプの幅は、SQL Serverが送信できるデータの量には影響しません。 代わりに、この量は、パイプ内のネットワーク待機時間 (接続速度) により異なります。
ネットワーク待機時間のテスト
フロー制御設定がネットワーク待機時間に影響するかどうかを確認する
Microsoft SQL Server可用性グループでは、フロー制御ゲートを使用して、すべての可用性レプリカでネットワーク リソース、メモリ、その他のリソースが過剰に消費されないようにします。 これらのフロー制御ゲートは、可用性レプリカの同期正常性状態には影響しません。 ただし、RPO など、可用性データベースの全体的なパフォーマンスに影響を与える可能性があります。
以降のバージョンのSQL Serverは、フロー制御が入力されるしきい値を変更します。 これは、フロー制御がログ送信キューなどの症状に与える影響を軽減するのに役立ちます。 フロー制御とフロー制御しきい値の変更履歴の詳細については、「 フロー制御ゲート」を参照してください。
パフォーマンス モニターを使用してプライマリ レプリカ上のデータをキャプチャすることで、フロー制御を監視できます。 データベース フロー制御を監視するには、 SQLServer:Database Replica カウンターを追加し、[ データベース フロー制御の遅延 ] カウンターと [ データベース フロー制御/秒 ] カウンターを選択します。 [インスタンス] ダイアログ ボックスで、データベース フロー制御にチェックする可用性グループ データベースを選択します。 可用性レプリカフロー制御を検出して監視するには、 SQLServer:Availability Replica カウンターを追加し、 フロー制御時間 (ミリ秒) カウンターと フロー制御/秒 カウンターを選択します。
輻輳 Windows 再起動がネットワーク待機時間に影響するかどうかを確認する
[ 輻輳 Windows 再起動 TCP ] 設定を True に設定すると、ログ送信キューの原因となるネットワーク パフォーマンスの問題をトリガーできます。 これは、Windows Server 2016の既定の設定でした。 ログ送信キューが監視される可用性グループ レプリカをホストする Windows サーバーでは、 輻輳ウィンドウの再起動 が False に設定されていることを確認します。
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart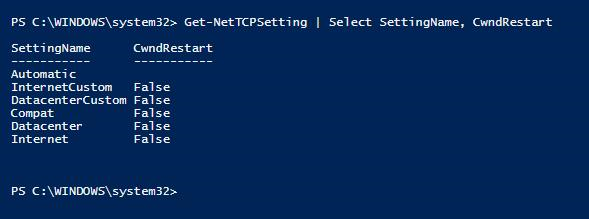
TCP 輻輳 Windows 再起動プロパティを False に設定する方法の詳細については、「Set-NetTCPSetting (NetTCPIP)」を参照してください。
同期プロセスの詳細については、「Always On可用性グループのパフォーマンスを監視する」も参照してください。 この記事では、いくつかの主要なメトリックを計算する方法についても説明し、一般的なパフォーマンストラブルシューティングシナリオの一部へのリンクを示します。
ping を使用して待機時間のサンプルを取得する
node1 (プライマリ レプリカ) のコマンド ラインで、node2 (セカンダリ レプリカ) に ping を実行します。
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101ms独立したツールを使用してプライマリからセカンダリへのネットワーク スループットをテストする
NTttcp などのツールを使用して、1 つの接続を使用してプライマリ レプリカとセカンダリ レプリカ間のネットワーク スループットを個別に検出します。 ネットワーク待機時間は、ログ送信キューの一般的な原因です。 次の手順では、NTttcp などの独立したツールを使用してネットワーク スループットを測定する方法を示します。
重要
SQL Serverは、1 つの接続を使用して、プライマリ レプリカからセカンダリ レプリカに変更を送信します。 次のセクションでは、スループットを正確に比較するために、(SQL Serverと同じ方法で) 1 つの接続を使用するように NTttcp を構成して実行します。
NTttcp は Github - microsoft/ntttcp からダウンロードできます。
NTttcp を実行するには、次の手順に従います。
ツールをダウンロードして、プライマリおよびセカンダリ SQL Server ベースのサーバーにコピーします。
セカンダリ レプリカ サーバーで、管理者特権のコマンド プロンプト ウィンドウを開き、ディレクトリを NTttcp ツール フォルダーに変更し、次のコマンドを実行します。
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60注:
このコマンドでは、
<secondaryipaddress>セカンダリ レプリカ サーバーの実際の IP アドレスのプレースホルダーです。プライマリ レプリカ サーバーで、管理者特権のコマンド プロンプト ウィンドウを開き、ディレクトリを NTttcp ツール フォルダーに変更し、セカンダリ レプリカ サーバーの実際の IP アドレスをもう一度指定して次のコマンドを実行します。
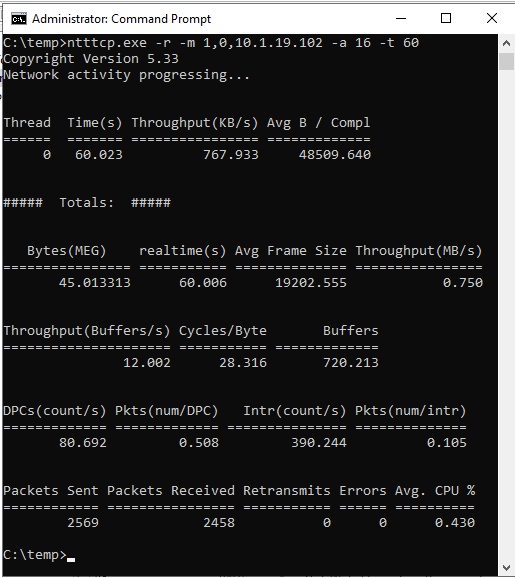
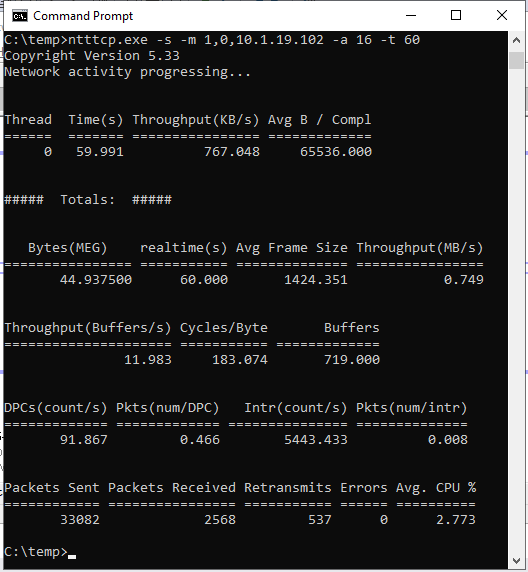
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60次のスクリーンショットは、セカンダリ レプリカとプライマリ レプリカで実行されている NTttcp を示しています。 ネットワーク待機時間のため、ツールは 739 KB/秒のデータのみを送信できます。 これは、SQL Serverが送信できることを期待できることです。
セカンダリ レプリカの NTttcp
プライマリ レプリカ上の NTttcp
パフォーマンス モニター カウンターを確認する
NTttcp が報告する内容を確認します。 大規模なトランザクションは、プライマリ レプリカ上のSQL Serverで実行されます。 プライマリ レプリカでパフォーマンス モニターを開始した後、ネットワーク インターフェイス::Bytes Sent/sec カウンターを追加します。 このカウンターは、プライマリ レプリカが約 777 KB/秒のデータを送信できることを確認します。 これは、NTttcp テストによって報告される 739 KB/秒の値に似ています。

また、プライマリ レプリカの SQL Server::D atabases::Log Bytes Flushed/sec の値を、セカンダリ レプリカ上の同じデータベースの SQL Server::D atabase Replica::Log Bytes Received/sec と比較すると便利です。 平均して、"agdb" データベースに作成された変更の量は約 20 MB/秒です。 ただし、セカンダリ レプリカは平均で 5.4 MB の変更のみを受信しています。 これにより、セカンダリ レプリカにまだ送信されていないデータベース トランザクション ログの未解決の変更のプライマリ レプリカでログ送信キューが作成されます。
"agdb" データベースのプライマリ レプリカ ログ バイトフラッシュ/秒

データベース agdb のセカンダリ レプリカ ログ の受信バイト数/秒
