2 つのサーバーで顕著なパフォーマンスの違いが見られるクエリに関するトラブルシューティング
適用対象: SQL Server
この記事では、あるサーバーでクエリの実行速度が別のサーバーよりも遅くなるパフォーマンスの問題のトラブルシューティング手順について説明します。
現象
SQL Server がインストールされている 2 つのサーバーがあるとします。 SQL Server インスタンスの 1 つに、他の SQL Server インスタンス内のデータベースのコピーが含まれています。 両方のサーバー上のデータベースに対してクエリを実行すると、一方のサーバーでもう一方のサーバーよりも実行速度が低下します。
次の手順は、この問題のトラブルシューティングに役立ちます。
手順 1: 複数のクエリで一般的な問題であるかどうかを判断する
次の 2 つの方法のいずれかを使用して、2 つのサーバー上の 2 つ以上のクエリのパフォーマンスを比較します。
両方のサーバーでクエリを手動でテストします。
- 次のようなクエリに優先順位を付けてテストするために、いくつかのクエリを選択します。
- 一方のサーバーでは、もう一方のサーバーよりも大幅に高速です。
- ユーザー/アプリケーションにとって重要です。
- 頻繁に実行されるか、必要に応じて問題を再現するように設計されています。
- データをキャプチャするのに十分な時間 (たとえば、5 ミリ秒のクエリではなく、10 秒のクエリを選択する)。
- 2 つのサーバーでクエリを実行します。
- クエリごとに 2 台のサーバーの経過時間 (期間) を比較します。
- 次のようなクエリに優先順位を付けてテストするために、いくつかのクエリを選択します。
SQL Nexus を使用してパフォーマンス データを分析します。
- PSSDiag/SQLdiag または SQL LogScout 2 つのサーバー上のクエリのデータを収集します。
- 収集したデータ ファイルを SQL Nexus と共にインポートし、2 つのサーバーからのクエリを比較します。 詳細については、「 2 つのログ コレクション間のパフォーマンス比較 (低速と高速など)を参照してください。
シナリオ 1: 2 つのサーバーで実行されるクエリが 1 つだけ異なる
1 つのクエリの実行が異なる場合、問題は環境ではなく個々のクエリに固有である可能性が高くなります。 この場合は、「 手順 2: データの収集」に進み、パフォーマンスの問題の種類を特定します。
シナリオ 2: 2 台のサーバーで複数のクエリの実行が異なる
一方のサーバーで複数のクエリの実行速度が他のサーバーよりも遅い場合、最も可能性の高い原因は、サーバー環境またはデータ環境の違いです。 Diagnose 環境の違いに移動し 2 つのサーバー間の比較が有効かどうかを確認します。
手順 2: データを収集し、パフォーマンスの問題の種類を特定する
経過時間、CPU 時間、論理読み取りを収集する
両方のサーバーでクエリの経過時間と CPU 時間を収集するには、状況に最も適した次のいずれかの方法を使用します。
現在実行中のステートメントについては、sys.dm_exec_requestsのtotal_elapsed_time列とcpu_time列を確認します。 次のクエリを実行してデータを取得します。
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;クエリの過去の実行については、sys.dm_exec_query_statsのlast_elapsed_time列とlast_worker_time列を確認します。 次のクエリを実行してデータを取得します。
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNote
avg_wait_timeに負の値が示されている場合は、パラメーター クエリです。SQL Server Management Studio (SSMS) または Azure Data Studio でオンデマンドでクエリを実行できる場合は、 SET STATISTICS TIME
ONと SET STATISTICS IOONを使用してクエリを実行します。SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFF次に、 Messages から、CPU 時間、経過時間、および次のような論理読み取りが表示されます。
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.クエリ プランを収集できる場合は、 Execution プランのプロパティからデータを確認。
Include Actual Execution Plan on でクエリを実行します。
Execution プランから左端の演算子を選択します。
Properties から、QueryTimeStats プロパティを展開します。
ElapsedTime と CpuTime を確認します。
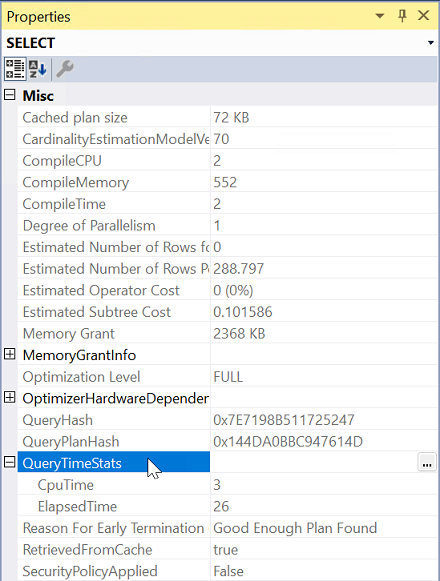
クエリの経過時間と CPU 時間を比較して、両方のサーバーの問題の種類を特定します。
型 1: CPU バインド (ランナー)
CPU 時間が経過時間に近い、等しい、またはそれより長い場合は、CPU バインド クエリとして扱うことができます。 たとえば、経過時間が 3000 ミリ秒 (ミリ秒) で、CPU 時間が 2900 ミリ秒の場合、ほとんどの経過時間が CPU に費やされます。 その後、CPU にバインドされたクエリであると言うことができます。
実行 (CPU バインド) クエリの例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
論理読み取り (キャッシュ内のデータ/インデックス ページの読み取り) は、SQL Server の CPU 使用率の要因として最も頻繁に使用されます。 CPU の使用が他のソース (T-SQL または XProcs や SQL CRL オブジェクトなどの他のコード) である while ループから取得されるシナリオが考えられます。 この表の 2 番目の例は、CPU の大部分が読み取りからのものではありません。このようなシナリオを示しています。
Note
CPU 時間が期間を超える場合は、並列クエリが実行されていることを示します。複数のスレッドが同時に CPU を使用しています。 詳細については、「 パラメーター クエリ - ランナーまたはウェイター」を参照してください。
タイプ 2: ボトルネックを待機している (待機者)
経過時間が CPU 時間を大幅に超える場合、クエリはボトルネックを待機しています。 経過時間には、CPU でクエリを実行する時間 (CPU 時間) と、リソースが解放されるのを待つ時間 (待機時間) が含まれます。 たとえば、経過時間が 2000 ミリ秒で CPU 時間が 300 ミリ秒の場合、待機時間は 1700 ミリ秒 (2000 - 300 = 1700) です。 詳細については、「 待機の種類」を参照してください。
待機クエリの例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
並列クエリ - ランナーまたはウェイター
並列クエリでは、全体的な期間よりも多くの CPU 時間が使用される場合があります。 並列処理の目的は、複数のスレッドがクエリの一部を同時に実行できるようにすることです。 1 秒のクロック時間では、8 つの並列スレッドを実行することで、クエリで 8 秒の CPU 時間を使用できます。 そのため、経過時間と CPU 時間の差に基づいて、CPU バインドまたは待機クエリを決定することが困難になります。 ただし、一般的なルールとして、上記の 2 つのセクションに記載されている原則に従ってください。 概要は次のとおりです。
- 経過時間が CPU 時間よりもはるかに長い場合は、待機者と見なします。
- CPU 時間が経過時間よりもはるかに長い場合は、ランナーと考えてください。
並列クエリの例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
手順 3: 両方のサーバーのデータを比較し、シナリオを把握し、問題のトラブルシューティングを行う
Server1 と Server2 という名前のマシンが 2 つあるとします。 また、Server1 では Server2 よりもクエリの実行速度が遅くなります。 両方のサーバーの時間を比較し、次のセクションのシナリオに最も適したアクションに従います。
シナリオ 1: Server1 のクエリで使用される CPU 時間が多く、Server1 の論理読み取りは Server2 よりも高い
Server1 の CPU 時間が Server2 よりもはるかに長く、経過時間が両方のサーバーの CPU 時間と密接に一致する場合、大きな待機やボトルネックはありません。 Server1 での CPU 時間の増加は、論理読み取りの増加が原因である可能性が最も高くなります。 論理読み取りの大幅な変更は、通常、クエリ プランの違いを示します。 例えば次が挙げられます。
| [サーバー] | 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|---|
| Server1 | 3100 | 3000 | 300000 |
| Server2 | 1100 | 1000 | 90200 |
アクション: 実行プランと環境を確認する
- 両方のサーバーでクエリの実行プランを比較します。 これを行うには、次の 2 つの方法のいずれかを使用します。
- 実行プランを視覚的に比較します。 詳細については、「実際の実行プランの表示」を参照してください。
- 実行プランを保存し、 SQL Server Management Studio プラン比較機能を使用して比較します。
- 環境を比較します。 環境が異なると、クエリ プランの違いや CPU 使用率の直接的な違いが生じる可能性があります。 環境には、サーバーのバージョン、データベースまたはサーバーの構成設定、トレース フラグ、CPU 数またはクロック速度、仮想マシンと物理マシンの比較が含まれます。 詳細については、 Diagnose クエリ プランの違い を参照してください。
シナリオ 2: クエリは Server1 では待機者ですが、Server2 では待機者ではありません
両方のサーバーのクエリの CPU 時間が似ているものの、Server1 の経過時間が Server2 よりもはるかに長い場合、Server1 のクエリはボトルネック 待つ時間が大幅に長くなります。 例えば次が挙げられます。
| [サーバー] | 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|---|
| Server1 | 4500 | 1000 | 90200 |
| Server2 | 1100 | 1000 | 90200 |
- Server1 の待機時間: 4500 - 1000 = 3500 ミリ秒
- Server2 の待機時間: 1100 - 1000 = 100 ミリ秒
アクション: Server1 で待機の種類を確認する
Server1 のボトルネックを特定して排除します。 待機の例としては、ブロック (ロック待機)、ラッチ待機、ディスク I/O 待機、ネットワーク待機、メモリ待機があります。 一般的なボトルネックの問題をトラブルシューティングするには、 Diagnose の待機またはボトルネックに進みます。
シナリオ 3: 両方のサーバーのクエリは待機者ですが、待機の種類または時刻は異なります
例えば次が挙げられます。
| [サーバー] | 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|---|
| Server1 | 8000 | 1000 | 90200 |
| Server2 | 3000 | 1000 | 90200 |
- Server1 の待機時間: 8000 - 1000 = 7000 ミリ秒
- Server2 の待機時間: 3000 - 1000 = 2000 ミリ秒
この場合、CPU 時間は両方のサーバーで似ています。これは、クエリ プランが同じ可能性があることを示します。 ボトルネックを待機しない場合、クエリは両方のサーバーで同じように実行されます。 そのため、期間の違いは、待機時間の量によって異なります。 たとえば、クエリは Server1 のロックを 7000 ミリ秒待機し、Server2 の I/O で 2000 ミリ秒待機します。
アクション: 両方のサーバーで待機の種類を確認する
各サーバーで各ボトルネックの待機に個別に対処し、両方のサーバーでの実行を高速化します。 両方のサーバーのボトルネックを排除し、パフォーマンスを同等にする必要があるため、この問題のトラブルシューティングは手間がかかります。 一般的なボトルネックの問題をトラブルシューティングするには、 Diagnose の待機またはボトルネックに進みます。
シナリオ 4: Server1 のクエリでは、Server2 よりも多くの CPU 時間が使用されますが、論理読み取りは終了しています
例えば次が挙げられます。
| [サーバー] | 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|---|
| Server1 | 3000 | 3000 | 90200 |
| Server2 | 1000 | 1000 | 90200 |
データが次の条件と一致する場合:
- Server1 の CPU 時間は、Server2 よりもはるかに長くなります。
- 経過時間は、各サーバーの CPU 時間と密接に一致します。これは、待機がないことを示します。
- 論理読み取り (通常は CPU 時間の最も高いドライバー) は、両方のサーバーで似ています。
その後、追加の CPU 時間は、他の CPU にバインドされたアクティビティから取得されます。 このシナリオは、すべてのシナリオで最もまれです。
原因: トレース、UDF、CLR 統合
この問題は、次の原因で発生する可能性があります。
- XEvents/SQL Server トレース。特に、テキスト列 (データベース名、ログイン名、クエリ テキストなど) のフィルター処理を使用します。 一方のサーバーではトレースが有効になっていて、もう一方では有効になっていない場合は、これが違いの原因である可能性があります。
- CPU バインド操作を実行するユーザー定義関数 (UDF) またはその他の T-SQL コード。 これは通常、データ サイズ、CPU クロック速度、電源プランなど、Server1 と Server2 で他の条件が異なる場合に原因になります。
- SQL Server CLR 統合 または CPU を駆動する可能性があるが、論理読み取りを実行しない可能性があるストアド プロシージャ (XP) 。 DLL の違いにより、CPU 時間が異なる可能性があります。
- CPU バインドである SQL Server 機能の違い (文字列操作コードなど)。
アクション: トレースとクエリを確認する
両方のサーバーでトレースを確認し、次のことを確認します。
- Server1 で有効になっているトレースがあるが、Server2 では有効になっていない場合。
- トレースが有効になっている場合は、トレースを無効にして、Server1 でクエリをもう一度実行します。
- 今回クエリの実行速度が速い場合は、トレースを有効に戻しますが、テキスト フィルターがある場合は削除します。
クエリで文字列操作を行う UDF を使用するか、
SELECTリスト内のデータ列に対して広範な処理を行うかどうかを確認します。クエリにループ、関数再帰、または入れ子が含まれているかどうかを確認します。
環境の違いを診断する
次の質問を確認し、2 つのサーバー間の比較が有効かどうかを判断します。
2 つの SQL Server インスタンスは同じバージョンまたはビルドですか?
そうでない場合は、違いの原因となったいくつかの修正プログラムが存在する可能性があります。 次のクエリを実行して、両方のサーバーのバージョン情報を取得します。
SELECT @@VERSION物理メモリの量は両方のサーバーで似ていますか?
一方のサーバーに 64 GB のメモリがあり、もう一方のサーバーに 256 GB のメモリがある場合は、大きな違いになります。 データ/インデックス ページとクエリ プランのキャッシュに使用できるメモリが増えるので、ハードウェア リソースの可用性に基づいてクエリを異なる方法で最適化できます。
CPU 関連のハードウェア構成は両方のサーバーで似ていますか? 例えば次が挙げられます。
CPU の数はマシンによって異なります (1 台のコンピューターでは 24 個の CPU、もう一方のコンピューターでは 96 個の CPU)。
電源プラン - バランスと高パフォーマンス。
仮想マシン (VM) と物理 (ベア メタル) マシン。
Hyper-V と VMware の違い。構成の違い。
クロック速度の違い (クロック速度が低い方とクロック速度が高い)。 たとえば、2 GHz と 3.5 GHz では違いが生じます。 サーバーのクロック速度を取得するには、次の PowerShell コマンドを実行します。
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
サーバーの CPU 速度をテストするには、次の 2 つの方法のいずれかを使用します。 同等の結果が得られない場合、問題は SQL Server の外部にあります。 これは、電源プランの違い、CPU の減少、VM ソフトウェアの問題、クロック速度の違いなどです。
両方のサーバーで次の PowerShell スクリプトを実行し、出力を比較します。
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"両方のサーバーで次の Transact-SQL コードを実行し、出力を比較します。
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
待機またはボトルネックを診断する
ボトルネックを待機しているクエリを最適化するには、待機の長さとボトルネックの場所 (待機の種類) を特定します。 待機の種類が確認されたら待機時間を短縮するか、完全に待機を排除します。
おおよその待機時間を計算するには、クエリの経過時間から CPU 時間 (ワーカー時間) を減算します。 通常、CPU 時間は実際の実行時間であり、クエリの有効期間の残りの部分は待機しています。
おおよその待機時間を計算する方法の例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 待機時間 (ミリ秒) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
ボトルネックまたは待機を特定する
待機時間の長い履歴クエリ (全体の経過時間の >20% が待機時間など) を特定するには、次のクエリを実行します。 このクエリでは、SQL Server の開始以降にキャッシュされたクエリ プランのパフォーマンス統計が使用されます。
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESC待機時間が 500 ミリ秒を超える現在実行中のクエリを特定するには、次のクエリを実行します。
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1クエリ プランを収集できる場合は、SSMS の実行プランのプロパティからWaitStats を確認します。
- Include Actual Execution Plan on を使用してクエリを実行します。
- [実行プラン]タブで、左端の演算子右クリックします。
- Propertiesを選択しWaitStatsプロパティを選択します。
- WaitTimeMs と WaitType を確認します。
PSSDiag/SQLdiag または SQL LogScout LightPerf/GeneralPerf シナリオに慣れている場合は、いずれかのシナリオを使用してパフォーマンス統計を収集し、SQL Server インスタンスで待機中のクエリを特定することを検討してください。 収集したデータ ファイルをインポートし、 SQL Nexus を使用してパフォーマンス データを分析できます。
待機の排除または削減に役立つ参照
各待機の種類の原因と解決策は異なります。 すべての待機の種類を解決する一般的な方法は 1 つもありません。 待機の種類に関する一般的な問題のトラブルシューティングと解決に関する記事を次に示します。
- ブロックの問題を理解して解決する (LCK_M_*)
- Azure SQL Database のブロックの問題の概要と解決策
- I/O の問題 (PAGEIOLATCH_*、WRITELOG、IO_COMPLETION、BACKUPIO) による SQL Server のパフォーマンス低下のトラブルシューティング
- SQL Server での最終ページ挿入PAGELATCH_EX 競合を解決する
- メモリ許可の説明と解決策 (RESOURCE_SEMAPHORE)
- 待機の種類に起因する低速クエリASYNC_NETWORK_IOトラブルシューティングする
- Always On 可用性グループを使用した高HADR_SYNC_COMMIT待機の種類のトラブルシューティング
- しくみ: CMEMTHREAD とデバッグ
- 並列処理待機を実行可能にする (CXPACKET と CXCONSUMER)
- THREADPOOL 待機
多くの待機の種類とそれらが示す内容の説明については、「待機の種類の表を参照してください。
クエリ プランの違いを診断する
クエリ プランの違いの一般的な原因を次に示します。
データ サイズまたはデータ値の違い
両方のサーバーで同じデータベースが使用されていますか。同じデータベース バックアップを使用していますか? 一方のサーバー上のデータは、もう一方のサーバーと比較して変更されていますか? データの違いにより、クエリ プランが異なる可能性があります。 たとえば、テーブル T1 (1000 行) とテーブル T2 (2,000,000 行) の結合は、テーブル T1 (100 行) とテーブル T2 (2,000,000 行) の結合とは異なります。
JOIN操作の種類と速度は大きく異なる場合があります。統計の違い
statistics一方のデータベースではなく、もう一方のデータベースで更新されていますか? 統計が異なるサンプル レート (たとえば、30% と 100% のフル スキャン) で更新されていますか? 両方の側の統計を同じサンプル レートで更新してください。
データベース互換性レベルの違い
データベースの互換性レベルが 2 つのサーバー間で異なるかどうかを確認します。 データベース互換性レベルを取得するには、次のクエリを実行します。
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'サーバーのバージョン/ビルドの違い
SQL Server のバージョンまたはビルドは、2 つのサーバー間で異なりますか? たとえば、1 つのサーバー SQL Server バージョン 2014 ともう 1 つの SQL Server バージョン 2016 ですか。 クエリ プランの選択方法が変更される可能性がある製品の変更が存在する可能性があります。 SQL Server の同じバージョンとビルドを比較してください。
SELECT ServerProperty('ProductVersion')カーディナリティ推定 (CE) バージョンの違い
レガシ カーディナリティ推定機能がデータベース レベルでアクティブ化されているかどうかを確認します。 CE の詳細については、「 Cardinality Estimation (SQL Server)」を参照してください。
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'オプティマイザー修正プログラムの有効化/無効化
クエリ オプティマイザーの修正プログラムが 1 つのサーバーで有効になっているが、もう一方のサーバーで無効になっている場合は、異なるクエリ プランを生成できます。 詳細については、「 SQL Server クエリ オプティマイザー修正プログラム トレース フラグ 4199 サービス モデルを参照してください。
クエリ オプティマイザー修正プログラムの状態を取得するには、次のクエリを実行します。
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'トレース フラグの違い
一部のトレース フラグは、クエリ プランの選択に影響します。 一方のサーバーで有効になっているトレース フラグが、もう一方のサーバーで有効になっていないかどうかを確認します。 両方のサーバーで次のクエリを実行し、結果を比較します。
-- Check at server level for trace flags DBCC TRACESTATUS (-1)ハードウェアの違い (CPU 数、メモリ サイズ)
ハードウェア情報を取得するには、次のクエリを実行します。
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoクエリ オプティマイザーによるハードウェアの違い
クエリ プランの
OptimizerHardwareDependentPropertiesを確認し、異なるプランでハードウェアの違いが重要と見なされているかどうかを確認します。WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'オプティマイザーのタイムアウト
最適化タイムアウト問題はありますか? 実行されているクエリが複雑すぎる場合、クエリ オプティマイザーはプラン オプションの評価を停止できます。 停止すると、その時点で使用可能なコストが最も低いプランが選択されます。 これは、あるサーバーと別のサーバーで任意のプランを選択したと思われるものにつながる可能性があります。
SET オプション
set オプションの中には、 SET ARITHABORT など、プランに影響を与えるものもあります。 詳細については、「 SET オプション」を参照してください。
クエリ ヒントの違い
一方のクエリでは クエリ ヒントが使用され もう 1 つのクエリでは使用されませんか? クエリ テキストを手動で確認して、クエリ ヒントの存在を確立します。
パラメーターに依存するプラン (パラメーター スニッフィングの問題)
まったく同じパラメーター値を使用してクエリをテストしていますか? そうでない場合は、そこから開始できます。 プランは、別のパラメーター値に基づいて 1 つのサーバーで以前にコンパイルされましたか? RECOMPILE クエリ ヒントを使用して 2 つのクエリをテストし、プランの再利用が行われないようにします。 詳細については、「パラメーターに依存する問題の調査と解決」を参照してください。
さまざまなデータベース オプション/スコープ構成設定
両方のサーバーで同じデータベース オプションまたはスコープ構成設定が使用されていますか? 一部のデータベース オプションは、プランの選択に影響を与える可能性があります。 たとえば、データベースの互換性、レガシ CE と既定の CE、パラメーター スニッフィングなどです。 1 つのサーバーから次のクエリを実行して、2 つのサーバーで使用されるデータベース オプションを比較します。
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.nameプラン ガイド
一方のサーバーではクエリに使用されるプラン ガイドは使用されますが、もう一方のサーバーでは使用されませんか? 次のクエリを実行して、違いを確認します。
SELECT * FROM sys.plan_guides