I/O の問題による SQL Server のパフォーマンス低下のトラブルシューティング
適用対象: SQL Server
この記事では、SQL Server のパフォーマンスが低下する原因となる I/O の問題と、問題のトラブルシューティング方法に関するガイダンスを提供します。
低速な I/O パフォーマンスを定義する
パフォーマンス モニター カウンターは、I/O パフォーマンスの低下を判断するために使用されます。 これらのカウンターは、クロック時間の観点から、I/O サブシステムが各 I/O 要求を平均してサービスする速度を測定します。 Windows の I/O 待機時間を測定する特定の パフォーマンス モニター カウンターは Avg Disk sec/ Read、、 Avg. Disk sec/Write、および Avg. Disk sec/Transfer (読み取りと書き込みの両方の累積) です。
SQL Server では、同じように動作します。 一般的に、SQL Server がクロック時間 (ミリ秒) で測定された I/O ボトルネックを報告するかどうかを確認します。 SQL Server は、 などの WriteFile()ReadFile()WriteFileGather()Win32 関数を呼び出すことによって、OS への I/O 要求をReadFileScatter()行います。 I/O 要求を投稿すると、SQL Server は要求を回し、 待機の種類を使用して要求の期間を報告します。 SQL Server では、待機の種類を使用して、製品内のさまざまな場所で I/O 待機を示します。 I/O 関連の待機は次のとおりです。
- / PAGEIOLATCH_SHPAGEIOLATCH_EX
- WRITELOG
- IO_COMPLETION
- ASYNC_IO_COMPLETION
- BACKUPIO
これらの待機が一貫して 10 から 15 ミリ秒を超える場合、I/O はボトルネックと見なされます。
注:
コンテキストと観点を提供するために、SQL Server のトラブルシューティングの世界では、Microsoft CSS では、I/O 要求が 1 秒を超え、転送あたり最大 15 秒かかるケースが観察されています。このような I/O システムでは最適化が必要です。 逆に、Microsoft CSS では、スループットが 1 ミリ秒/転送未満のシステムが見られました。 今日の SSD/NVMe テクノロジでは、アドバタイズされたスループット レートは転送あたり数十マイクロ秒です。 したがって、10 から 15 ミリ秒/転送の数値は、Windows と SQL Server エンジニア間の長年の集合的なエクスペリエンスに基づいて選択した非常におおよそのしきい値です。 通常、数値がこのおおよそのしきい値を超えると、SQL Server ユーザーはワークロードの待機時間が表示され、レポートが開始されます。 最終的には、I/O サブシステムの予想スループットは、製造元、モデル、構成、ワークロード、および他の複数の要因によって定義されます。
方法論
この記事の最後の フローチャート では、SQL Server で I/O の問題が遅い場合に Microsoft CSS が使用する手法について説明します。 網羅的または排他的なアプローチではありませんが、問題を分離して解決するのに役立ちます。
次の 2 つのオプションのいずれかを選択して、問題を解決できます。
オプション 1: Azure Data Studio を使用してノートブックで手順を直接実行する
注:
このノートブックを開く前に、Azure Data Studio がローカル コンピューターにインストールされていることを確認してください。 インストールするには、 Azure Data Studio のインストール方法に関するページを参照してください。
オプション 2: 手順を手動で実行する
手法については、次の手順で説明します。
手順 1: SQL Server のレポートの I/O が遅いですか?
SQL Server では、いくつかの方法で I/O 待機時間が報告される場合があります。
- I/O 待機の種類
- DMV
sys.dm_io_virtual_file_stats - エラー ログまたはアプリケーション イベント ログ
I/O 待機の種類
SQL Server 待機の種類によって報告される I/O 待機時間があるかどうかを判断します。 PAGEIOLATCH_*値、WRITELOG、およびASYNC_IO_COMPLETION他のあまり一般的でない待機の種類の値は、通常、I/O 要求あたり 10 から 15 ミリ秒未満に留まる必要があります。 これらの値が一貫して大きい場合は、I/O パフォーマンスの問題が存在し、さらに調査する必要があります。 次のクエリは、システムでこの診断情報を収集するのに役立ちます。
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
sys.dm_io_virtual_file_statsのファイル統計
SQL Server で報告されたデータベース ファイル レベルの待機時間を表示するには、次のクエリを実行します。
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
列と LatencyAssessment 列をAvgLatency見て、待機時間の詳細を理解します。
エラー ログまたはアプリケーション イベント ログで報告されたエラー 833
場合によっては、エラー ログにエラー 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) が表示されることがあります。 次の PowerShell コマンドを実行して、システム上の SQL Server エラー ログを確認できます。
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
また、このエラーの詳細については、「 MSSQLSERVER_833 」セクションを参照してください。
手順 2: Perfmon カウンターは I/O 待機時間を示していますか?
SQL Server で I/O 待機時間が報告される場合は、「OS カウンター」を参照してください。 待機時間カウンター Avg Disk Sec/Transferを調べることで、I/O の問題があるかどうかを判断できます。 次のコード スニペットは、PowerShell を使用してこの情報を収集する 1 つの方法を示しています。 "_total" のすべてのディスク ボリューム上のカウンターを収集します。 特定のドライブ ボリューム ("D:"など) に変更します。 データベース ファイルをホストするボリュームを検索するには、SQL Server で次のクエリを実行します。
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
選択したボリュームのメトリックを収集 Avg Disk Sec/Transfer します。
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
このカウンターの値が一貫して 10 から 15 ミリ秒を超える場合は、問題をさらに確認する必要があります。 ほとんどの場合、スパイクはカウントされませんが、スパイクの期間を再確認してください。 スパイクが 1 分以上続いた場合は、スパイクよりも高い値になります。
パフォーマンス モニター カウンターで待機時間が報告されないが、SQL Server で報告される場合、問題は SQL Server とパーティション マネージャー (つまりフィルター ドライバー) の間にあります。 パーティション マネージャーは、OS が Perfmon カウンターを収集する I/O レイヤーです。 待機時間に対処するには、フィルター ドライバーの適切な除外を確認し、フィルター ドライバーの問題を解決します。 フィルター ドライバーは、 ウイルス対策ソフトウェア、 バックアップ ソリューション、 暗号化、 圧縮などのプログラムで使用されます。 このコマンドを使用すると、システム上のフィルター ドライバーと、アタッチするボリュームを一覧表示できます。 次に、 割り当てられたフィルター高度 に関する記事でドライバー名とソフトウェア ベンダーを検索できます。
fltmc instances
詳細については、「 SQL Server を実行しているコンピューターで実行するウイルス対策ソフトウェアを選択する方法」を参照してください。
暗号化ファイル システム (EFS) とファイル システムの圧縮は、非同期 I/O が同期的になり、そのため低速になるため、使用しないでください。 詳細については、「 非同期ディスク I/O が Windows で同期として表示される 」の記事を参照してください。
手順 3: I/O サブシステムは容量を超えて圧倒されていますか?
SQL Server と OS で I/O サブシステムが低速であることが示されている場合は、システムが容量を超えて圧倒される原因であるかどうかを確認します。 容量を確認するには、I/O カウンター Disk Bytes/Sec、、 Disk Read Bytes/Sec、または Disk Write Bytes/Secを参照してください。 SAN (またはその他の I/O サブシステム) に予想されるスループット仕様については、システム管理者またはハードウェア ベンダーに確認してください。 たとえば、2 GB/秒の HBA カードまたは SAN スイッチの 2 GB/秒の専用ポートを介して、200 MB/秒以下の I/O をプッシュできます。 ハードウェアの製造元によって定義された予想スループット容量によって、ここからの進め方が定義されます。
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
手順 4: SQL Server は大量の I/O アクティビティを推進していますか?
I/O サブシステムが容量を超えて圧倒される場合は、特定のインスタンスについて (最も一般的な原因) と Page Writes/Sec (あまり一般的ではない) を調べることでBuffer Manager: Page Reads/Sec、SQL Server が原因であるかどうかを調べる。 SQL Server がメインの I/O ドライバーであり、I/O ボリュームがシステムで処理できる量を超えている場合は、アプリケーション開発チームまたはアプリケーション ベンダーと協力して、次のことを行います。
- クエリの調整(インデックスの改善、統計の更新、クエリの書き換え、データベースの再設計など)。
- 最大サーバー メモリを増やすか、システムに RAM を追加します。 RAM が増えるほど、ディスクから頻繁に再読み取りすることなく、より多くのデータまたはインデックス ページがキャッシュされるため、I/O アクティビティが減少します。 メモリを増やすと、 を減ら
Lazy Writes/secすこともできます。これは、使用可能な限られたメモリにデータベース ページを格納する必要が頻繁にある場合に、Lazy Writer フラッシュによって駆動されます。 - ページ書き込みが大量の I/O アクティビティのソースである場合は、回復間隔の構成要求を満たすために必要な大量のページ フラッシュが原因であるかどうかを調べます
Buffer Manager: Checkpoint pages/sec。 間接チェックポイントを使用して、時間の経過と同時に I/O を均等にするか、ハードウェア I/O スループットを向上させることができます。
原因
一般に、次の問題は、SQL Server クエリで I/O 待機時間が発生する大まかな理由です。
ハードウェアの問題:
SAN 構成の誤り (スイッチ、ケーブル、HBA、ストレージ)
I/O 容量を超えました (バックエンド ストレージだけでなく、SAN ネットワーク全体で不均衡)
ドライバーまたはファームウェアの問題
ハードウェア ベンダーやシステム管理者は、この段階で関与する必要があります。
クエリの問題: SQL Server は、I/O 要求でディスク ボリュームを飽和状態にし、I/O サブシステムを容量を超えてプッシュしているため、I/O 転送レートが高くなります。 この場合、ソリューションは、多数の論理読み取り (または書き込み) を引き起こしているクエリを見つけ、ディスク I/O を使用する適切なインデックスを最小限に抑えるようにクエリを調整することが、これを行う最初の手順です。 また、最適なプランを選択するのに十分な情報がクエリ オプティマイザーに提供されるため、統計は更新したままにします。 また、データベースの設計とクエリの設計が正しくないと、I/O の問題が増加する可能性があります。 そのため、クエリやテーブルを再設計すると、I/O の改善に役立つ場合があります。
フィルター ドライバー: ファイル システム フィルター ドライバーが大量の I/O トラフィックを処理する場合、SQL Server I/O 応答に重大な影響を与える可能性があります。 I/O パフォーマンスへの影響を防ぐために、ウイルス対策スキャンからの適切なファイル除外とソフトウェア ベンダーによる適切なフィルター ドライバー設計をお勧めします。
その他のアプリケーション: SQL Server を使用する同じコンピューター上の別のアプリケーションでは、過剰な読み取りまたは書き込み要求で I/O パスを飽和させることができます。 この状況により、I/O サブシステムが容量制限を超えてプッシュされ、SQL Server の I/O 速度が低下する可能性があります。 アプリケーションを特定して調整するか、別の場所に移動して I/O スタックへの影響を排除します。
手法のグラフィカル表現
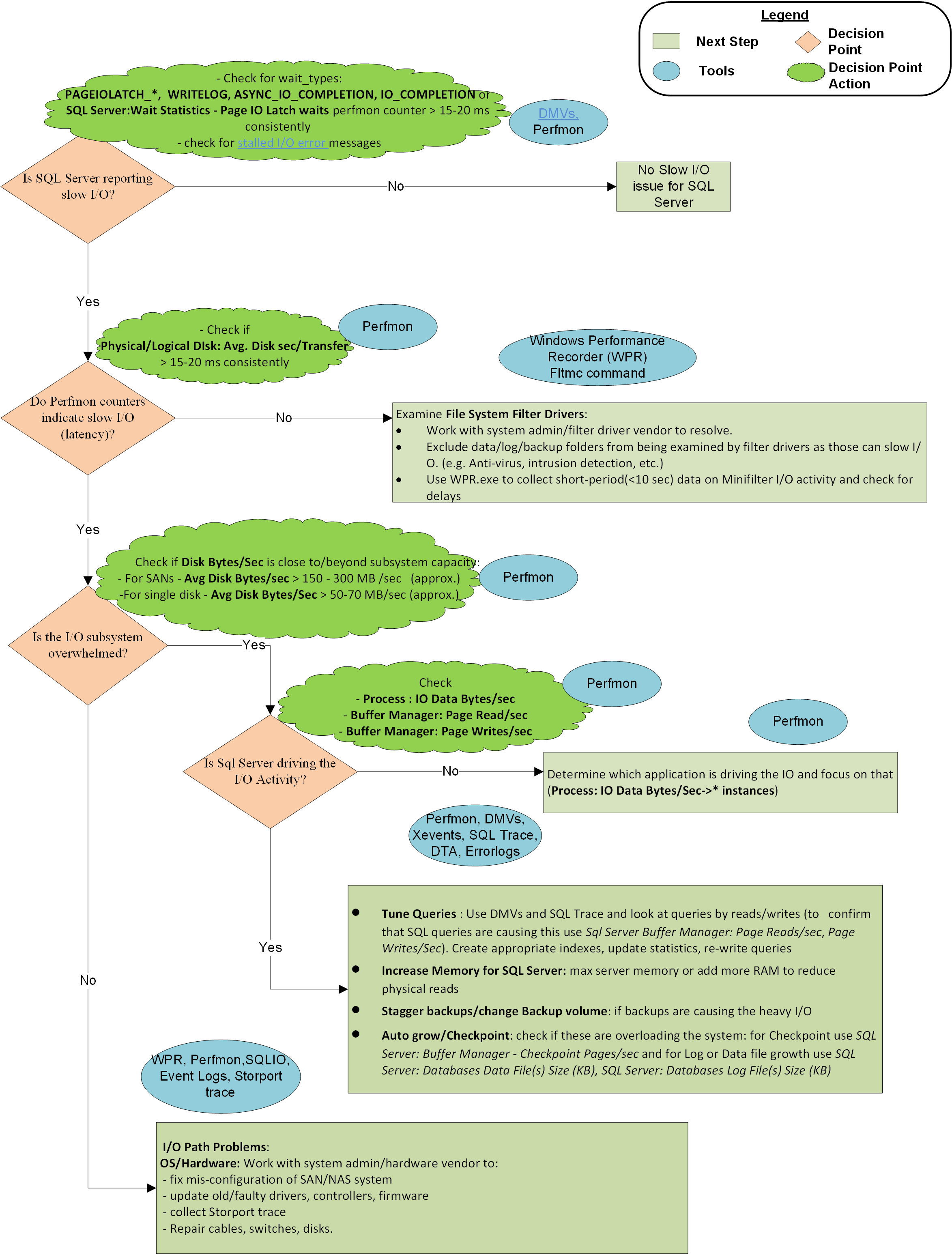
I/O 関連の待機の種類に関する情報
ディスク I/O の問題が報告されたときに SQL Server で観察される一般的な待機の種類の説明を次に示します。
PAGEIOLATCH_EX
I/O 要求のデータまたはインデックス ページ (バッファー) のラッチでタスクが待機しているときに発生します。 ラッチ要求は排他モードです。 排他的モードは、バッファーがディスクに書き込まれるときに使用されます。 長い待ち時間は、ディスク サブシステムに関する問題を示している可能性があります。
PAGEIOLATCH_SH
I/O 要求のデータまたはインデックス ページ (バッファー) のラッチでタスクが待機しているときに発生します。 ラッチ要求は共有モードです。 共有モードは、バッファーがディスクから読み取られているときに使用されます。 長い待ち時間は、ディスク サブシステムに関する問題を示している可能性があります。
PAGEIOLATCH_UP
タスクが I/O 要求のバッファーのラッチを待機しているときに発生します。 ラッチ要求は更新モードです。 長い待ち時間は、ディスク サブシステムに関する問題を示している可能性があります。
WRITELOG
タスクがトランザクション ログフラッシュの完了を待機しているときに発生します。 フラッシュは、ログ マネージャーが一時的な内容をディスクに書き込むと発生します。 ログフラッシュを引き起こす一般的な操作は、トランザクションのコミットとチェックポイントです。
待ち時間が長い場合の一般的な WRITELOG 理由は次のとおりです。
トランザクション ログ ディスクの待機時間: これは待機の最も一般的な原因
WRITELOGです。 一般に、データ ファイルとログ ファイルは別々のボリュームに保持することをお勧めします。 トランザクション ログ書き込みは、データ ファイルからのデータの読み取りまたは書き込みがランダムである間のシーケンシャル書き込みです。 1 つのドライブ ボリューム (特に従来の回転ディスク ドライブ) にデータ ファイルとログ ファイルを混在すると、ディスク ヘッドの移動が過剰になります。VDF が多すぎる: 仮想ログ ファイル (VDF) が多すぎると、待機が発生する可能性があります
WRITELOG。 VDF が多すぎると、長い復旧など、他の種類の問題が発生する可能性があります。小さなトランザクションが多すぎる: 大きなトランザクションがブロックされる可能性がある一方で、小さなトランザクションが多すぎると別の問題が発生する可能性があります。 トランザクションを明示的に開始しない場合、挿入、削除、または更新によってトランザクションが発生します (この自動トランザクションと呼びます)。 ループで 1,000 個の挿入を行うと、1,000 個のトランザクションが生成されます。 この例の各トランザクションをコミットする必要があります。その結果、トランザクション ログがフラッシュされ、トランザクション フラッシュが 1,000 になります。 可能であれば、個々の更新、削除、または挿入を大きなトランザクションにグループ化して、トランザクション ログのフラッシュを減らし、 パフォーマンスを向上させます。 この操作により、待機が少なくなる
WRITELOG可能性があります。スケジュールの問題により、ログ ライター スレッドが十分に高速にスケジュールされません。SQL Server 2016 より前は、1 つのログ ライター スレッドですべてのログ書き込みが実行されました。 スレッドのスケジューリングに問題が発生した場合 (CPU 使用率が高いなど)、ログ ライター スレッドとログ フラッシュの両方が遅延する可能性があります。 SQL Server 2016 では、ログ書き込みスループットを向上させるために、最大 4 つのログ ライター スレッドが追加されました。 「SQL 2016 - 実行速度が速い:複数のログ ライター ワーカー」を参照してください。 SQL Server 2019 では、最大 8 つのログ ライター スレッドが追加され、スループットがさらに向上しました。 また、SQL Server 2019 では、各通常のワーカー スレッドは、ログ ライター スレッドに投稿するのではなく、直接ログ書き込みを行うことができます。 これらの機能強化により、
WRITELOG問題のスケジュール設定によって待機がトリガーされることはほとんどありません。
ASYNC_IO_COMPLETION
次の I/O アクティビティの一部が発生したときに発生します。
- 一括挿入プロバイダー ("一括挿入") では、I/O を実行するときにこの待機の種類が使用されます。
- LogShipping で元に戻すファイルを読み取り、ログ配布用の非同期 I/O を指示します。
- データ バックアップ中にデータ ファイルから実際のデータを読み取る。
IO_COMPLETION
I/O 操作の完了を待っている間に発生します。 通常、この待機の種類には、データ ページ (バッファー) に関連しない I/O が含まれます。 たとえば、次のような情報が含まれます。
- スピル中のディスクとの間の並べ替え/ハッシュ結果の読み取りと書き込み ( tempdb ストレージのパフォーマンスの確認)。
- ディスクへの一括スプールの読み取りと書き込み ( tempdb ストレージの確認)。
- トランザクション ログからのログ ブロックの読み取り (ログをディスクから読み取る操作中など)。
- データベースがまだ設定されていない場合のディスクからのページの読み取り。
- データベース スナップショットへのページのコピー (コピーオンライト)。
- データベース ファイルとファイルの圧縮解除を閉じます。
BACKUPIO
バックアップ タスクがデータを待機している場合、またはバッファーがデータを格納するのを待っているときに発生します。 タスクがテープマウントを待機している場合を除き、この種類は一般的ではありません。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示