ゲーム開発用の CPUSets
はじめに
ユニバーサル Windows プラットフォーム (UWP) は、幅広いコンシューマー向け電子デバイスの中核をなしています。 そのため、ゲームから組み込みアプリ、サーバーで実行されているエンタープライズ ソフトウェアまで、あらゆる種類のアプリケーションのニーズに対応するための汎用 API が必要です。 API によって提供される適切な情報を活用することで、ゲームが任意のハードウェアで最高の状態で実行されるようにすることができます。
CPUSets API
CPUSets API では、スケジュールするスレッドに使用できる CPU セットを制御できます。 スレッドをスケジュールする場所を制御するには、次の 2 つの関数を使用できます。
- SetProcessDefaultCpuSets – この関数を使用して、新しいスレッドが特定の CPU セットに割り当てられない場合に実行できる CPU セットを指定できます。
- SetThreadSelectedCpuSets – この関数を使用すると、特定のスレッドが実行できる CPU セットを制限できます。
SetProcessDefaultCpuSets 関数を使用しない場合、新しく作成されたスレッドは、プロセスで使用可能な任意の CPU セットでスケジュールできます。 このセクションでは、CPUSets API の基本について説明します。
GetSystemCpuSetInformation
情報の収集に使用される最初の API は、 GetSystemCpuSetInformation 関数です。 この関数は、タイトル コードによって提供 SYSTEM_CPU_SET_INFORMATION オブジェクトの配列に情報を設定します。 宛先のメモリはゲーム コードによって割り当てる必要があります。サイズは、 GetSystemCpuSetInformation 自体を呼び出すことによって決定されます。 これには、次の例に示すように、 GetSystemCpuSetInformation を 2 回呼び出す必要があります。
unsigned long size;
HANDLE curProc = GetCurrentProcess();
GetSystemCpuSetInformation(nullptr, 0, &size, curProc, 0);
std::unique_ptr<uint8_t[]> buffer(new uint8_t[size]);
PSYSTEM_CPU_SET_INFORMATION cpuSets = reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(buffer.get());
GetSystemCpuSetInformation(cpuSets, size, &size, curProc, 0);
返される SYSTEM_CPU_SET_INFORMATION の各インスタンスには、CPU セットとも呼ばれる 1 つの一意の処理装置に関する情報が含まれています。 これは必ずしも、ハードウェアの一意の物理的な部分を表すという意味ではありません。 ハイパースレッディングを利用する CPU では、1 つの物理処理コアで複数の論理コアが実行されます。 同じ物理コア上に存在する異なる論理コアで複数のスレッドをスケジュールすると、ハードウェア レベルのリソースの最適化が可能になり、それ以外の場合はカーネル レベルで追加の作業を行う必要があります。 同じ物理コア上の個別の論理コアでスケジュールされた 2 つのスレッドは CPU 時間を共有する必要がありますが、同じ論理コアにスケジュールされている場合よりも効率的に実行されます。
SYSTEM_CPU_SET_INFORMATION
GetSystemCpuSetInformation から返されるこのデータ構造の各インスタンスの情報には、スレッドがスケジュールされる一意の処理単位に関する情報が含まれています。 ターゲット デバイスの可能な範囲を考えると、 SYSTEM_CPU_SET_INFORMATION データ構造内の多くの情報がゲーム開発に適用されない場合があります。 表 1 に、ゲーム開発に役立つデータ メンバーについて説明します。
表 1 ゲーム開発に役立つデータ メンバー。
| メンバー名 | データの種類 | 説明 |
|---|---|---|
| Type | CPU_SET_INFORMATION_TYPE | 構造体内の情報の種類。 この値が CpuSetInformation でない場合は、無視する必要があります。 |
| Id | unsigned long | 指定した CPU セットの ID。 これは、 SetThreadSelectedCpuSets などの CPU セット関数で使用する必要がある ID です。 |
| グループ | 符号なしショート | CPU セットの "プロセッサ グループ" を指定します。 プロセッサ グループを使用すると、PC は 64 個を超える論理コアを持ち、システムの実行中に CPU をホット スワップできます。 複数のグループを持つサーバーではない PC が表示されるのは珍しいことです。 大規模なサーバーまたはサーバー ファームで実行するアプリケーションを作成する場合を除き、ほとんどのコンシューマー PC にはプロセッサ グループが 1 つしかないため、1 つのグループで CPU セットを使用することをお勧めします。 この構造体の他のすべての値は、Group に対して相対的です。 |
| LogicalProcessorIndex | 符号なし文字 | CPU セットのグループ相対インデックス |
| CoreIndex | 符号なし文字 | CPU セットが配置されている物理 CPU コアのグループ相対インデックス |
| LastLevelCacheIndex | 符号なし文字 | この CPU セットに関連付けられている最後のキャッシュの相対インデックスをグループ化します。 これは、システムが NUMA ノード (通常は L2 または L3 キャッシュ) を使用しない限り、最も低速なキャッシュです。 |
他のデータ メンバーは、コンシューマー PC やその他のコンシューマー デバイスの CPU を記述する可能性が低く、役に立つ可能性が低い情報を提供します。 返されるデータによって提供される情報を使用して、さまざまな方法でスレッドを整理できます。 このホワイト ペーパーの「 ゲーム開発の概要 」セクションでは、このデータを活用してスレッドの割り当てを最適化するいくつかの方法について詳しく説明します。
さまざまな種類のハードウェアで実行されている UWP アプリケーションから収集される情報の種類の例を次に示します。
表 2 Microsoft Lumia 950 で実行されている UWP アプリから返される情報。 これは、複数の最後のレベルのキャッシュを持つシステムの例です。 Lumia 950 は、デュアル コア Arm Cortex A57 とクワッド コア Arm Cortex A53 CPU を含む Qualcomm 808 Snapdragon プロセスを備えています。
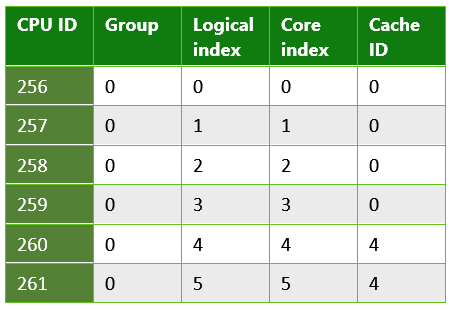
表 3. 一般的な PC で実行されている UWP アプリから返される情報。 これは、ハイパースレッディングを使用するシステムの例です。各物理コアには、スレッドをスケジュールできる 2 つの論理コアがあります。 この場合、システムには Intel Xenon CPU E5-2620 が含まれていました。
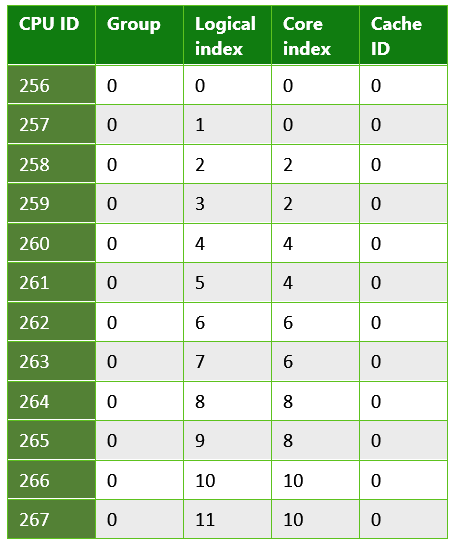
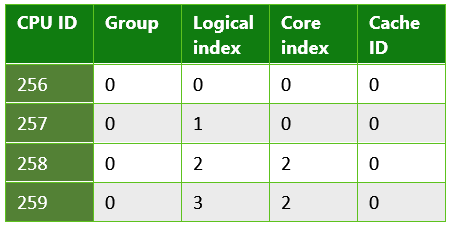
表 4. Pro 4 Microsoft Surfaceクアッド コアで実行されている UWP アプリから返される情報。 このシステムには Intel Core i5-6300 CPU がありました。
SetThreadSelectedCpuSets
CPU セットに関する情報が使用可能になったので、それを使用してスレッドを整理できます。 CreateThread で作成されたスレッドのハンドルは、スレッドをスケジュールできる CPU セットの ID の配列と共に、この関数に渡されます。 その使用方法の 1 つの例を次のコードで示します。
HANDLE audioHandle = CreateThread(nullptr, 0, AudioThread, nullptr, 0, nullptr);
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::vector<DWORD> cores;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
cores.push_back( info->CpuSet.Id );
}
ptr += info->Size;
size += info->Size;
}
if ( cores.size() >= 2 ) {
SetThreadSelectedCpuSets(audioHandle, cores.data(), 2);
}
この例では、 AudioThread として宣言された関数に基づいてスレッドが作成されます。 このスレッドは、2 つの CPU セットのいずれかでスケジュールできます。 CPU セットのスレッド所有権は排他的ではありません。 特定の CPU セットにロックされずに作成されたスレッドは、 AudioThread から時間がかかる場合があります。 同様に、作成された他のスレッドも、後でこれらの CPU セットの一方または両方にロックされる可能性があります。
SetProcessDefaultCpuSets
SetThreadSelectedCpuSets の逆は、SetProcessDefaultCpuSets です。 スレッドを作成するときに、特定の CPU セットにロックする必要はありません。 これらのスレッドを特定の CPU セット (レンダリング スレッドやオーディオ スレッドで使用されるスレッドなど) で実行しない場合は、この関数を使用して、これらのスレッドのスケジュールを許可するコアを指定できます。
ゲーム開発に関する考慮事項
これまでに説明したように、CPUSets API は、スレッドのスケジュール設定に関して多くの情報と柔軟性を提供します。 このデータの用途を見つけようとするボトムアップ アプローチを採用する代わりに、一般的なシナリオに対応するためにデータを使用する方法を見つけるトップダウン アプローチを使用する方が効果的です。
タイム クリティカルなスレッドとハイパースレッディングの操作
このメソッドは、ゲームに、比較的少ない CPU 時間を必要とする他のワーカー スレッドと共にリアルタイムで実行する必要があるスレッドがいくつかある場合に有効です。 一部のタスク (継続的なバックグラウンド ミュージックなど) は、最適なゲーム エクスペリエンスを実現するために中断することなく実行する必要があります。 オーディオ スレッドの 1 フレームの不足でも、ポップやグリッチが発生する可能性があるため、フレームごとに必要な CPU 時間を受け取る必要があります。
SetThreadSelectedCpuSets SetProcessDefaultCpuSets と組み合わせて使用すると重いスレッドがワーカー スレッドによって中断されないようにすることができます。 SetThreadSelectedCpuSets を使用して、負荷の高いスレッドを特定の CPU セットに割り当てることができます。 SetProcessDefaultCpuSets を使用して、作成された未割り当てスレッドが他の CPU セットに配置されるようにすることができます。 ハイパースレッディングを利用する CPU の場合は、同じ物理コア上の論理コアを考慮することも重要です。 ワーカー スレッドは、リアルタイムの応答性で実行するスレッドと同じ物理コアを共有する論理コアで実行を許可しないでください。 次のコードは、PC がハイパースレッディングを使用しているかどうかを判断する方法を示しています。
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::set<DWORD> cores;
std::vector<DWORD> processors;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
processors.push_back( info->CpuSet.Id );
cores.insert( info->CpuSet.CoreIndex );
}
ptr += info->Size;
size += info->Size;
}
bool hyperthreaded = processors.size() != cores.size();
システムがハイパースレッディングを利用する場合は、既定の CPU セットのセットに、リアルタイム スレッドと同じ物理コア上の論理コアが含まれていないことが重要です。 システムがハイパースレッディングでない場合は、既定の CPU セットにオーディオ スレッドを実行している CPU セットと同じコアが含まれていないことを確認する必要があります。
物理コアに基づいてスレッドを整理する例については、「 追加リソース 」セクションにリンクされている GitHub リポジトリで入手できる CPUSets サンプルを参照してください。
最後のレベルのキャッシュを使用したキャッシュコヒーレンスのコストの削減
キャッシュの一貫性は、キャッシュされたメモリが、同じデータに対して動作する複数のハードウェア リソースで同じであるという概念です。 スレッドが異なるコアでスケジュールされているが、同じデータで動作する場合は、異なるキャッシュ内のそのデータの個別のコピーで動作している可能性があります。 正しい結果を得るには、これらのキャッシュを互いに一貫性を保つ必要があります。 複数のキャッシュ間の一貫性を維持することは比較的コストがかかりますが、マルチコア システムを動作させるために必要です。 さらに、クライアント コードの制御が完全に外れている。基になるシステムは個別に動作し、コア間の共有メモリ リソースにアクセスしてキャッシュを最新の状態に保ちます。
ゲームに、特に大量のデータを共有する複数のスレッドがある場合は、最後のレベルのキャッシュを共有する CPU セットでスケジュールされるようにすることで、キャッシュの一貫性のコストを最小限に抑えることができます。 最後のレベルのキャッシュは、NUMA ノードを使用しないシステム上のコアで使用できる最も低速なキャッシュです。 ゲーム PC で NUMA ノードを利用することは非常にまれです。 コアが最後のレベルのキャッシュを共有しない場合、一貫性を維持するには、より高いレベルのメモリ リソースにアクセスする必要があります。そのため、メモリ リソースは低速になります。 キャッシュと物理コアを共有する CPU セットを分離するために 2 つのスレッドをロックすると、特定のフレームで 50% を超える時間を必要としない場合に、個別の物理コアでスケジュールするよりもパフォーマンスがさらに向上する可能性があります。
このコード例では、頻繁に通信するスレッドが最後のレベルのキャッシュを共有できるかどうかを判断する方法を示します。
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation(nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data(new uint8_t[retsize]);
if (!GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(data.get()),
retsize, &retsize, GetCurrentProcess(), 0))
{
// Error!
}
bool sharedcache = false;
std::map<unsigned char, std::vector<const SYSTEM_CPU_SET_INFORMATION*>> cachemap;
uint8_t const * ptr = data.get();
for(DWORD size = 0; size < retsize;)
{
auto cpuset = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>(ptr);
if (cpuset->Type == CpuSetInformation)
{
if (cachemap.find(cpuset->CpuSet.LastLevelCacheIndex) == cachemap.end())
{
std::pair<unsigned char, std::vector<const SYSTEM_CPU_SET_INFORMATION*>> newvalue;
newvalue.first = cpuset->CpuSet.LastLevelCacheIndex;
newvalue.second.push_back(cpuset);
cachemap.insert(newvalue);
}
else
{
sharedcache = true;
cachemap[cpuset->CpuSet.LastLevelCacheIndex].push_back(cpuset);
}
}
ptr += cpuset->Size;
size += cpuset->Size;
}
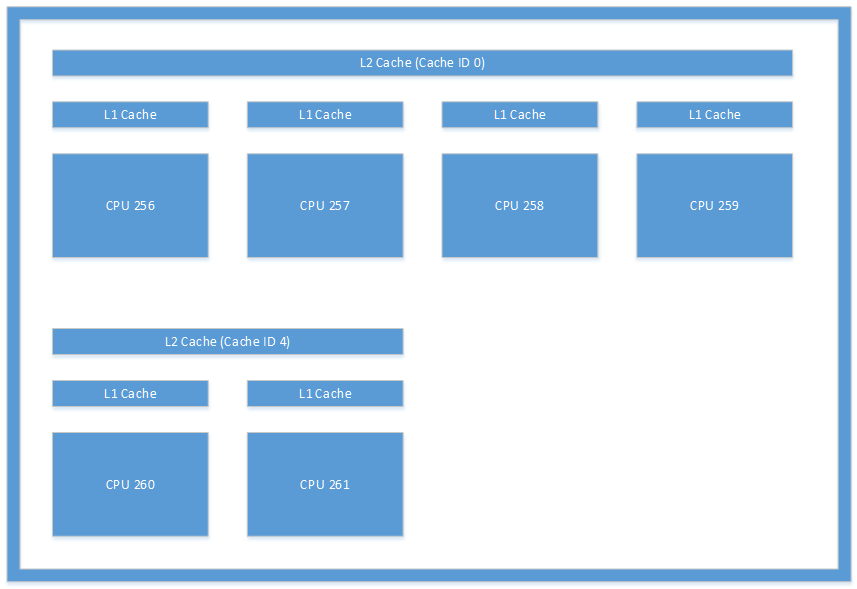
図 1 に示すキャッシュ レイアウトは、システムから表示されるレイアウトの種類の例です。 この図は、Microsoft Lumia 950 で見つかったキャッシュの図です。 CPU 256 と CPU 260 の間で発生するスレッド間通信では、システムが L2 キャッシュのコヒーレントを維持する必要があるため、大幅なオーバーヘッドが発生します。
図 1. Microsoft Lumia 950 デバイスで見つかったキャッシュ アーキテクチャ。
まとめ
UWP 開発に使用できる CPUSets API は、膨大な量の情報を提供し、マルチスレッド オプションを制御します。 Windows 開発用の以前のマルチスレッド API と比較して複雑さが増しましたが、柔軟性が向上すると、最終的には、さまざまなコンシューマー PC やその他のハードウェア ターゲットでパフォーマンスが向上します。