Data Science ツールキット - ロジスティック回帰カスタム モデル サービス
ロジスティック回帰カスタム モデル サービスを使用すると、ロジスティック回帰モデル ("logit モデル" とも呼ばれます) を作成して、複数のシグナルの組み合わせに基づいてクリックまたは変換の可能性を予測できます。 その後、ロジスティック回帰モデルは、明細サービス - ALI (アーカイブ) を使用して、明細に関連付けることができます。
注:
このオファリングは現在クローズド ベータ版であり、限られたクライアント セットで利用できます。 高度な広告ツールセットと、ビジネスに適用される可能性のあるユース ケースの詳細については、アカウント担当者にお問い合わせください。
ロジスティック回帰の数式は次のとおりです。
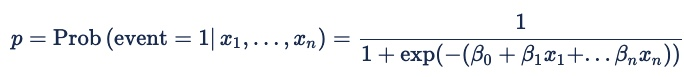
オンライン広告の場合、イベントはクリック、ピクセル火災、または別のオンライン アクションです。 確率は、予測変数 x 1 から xn の両方と、入札要求の特徴を表す暗黙的な変数セットの両方で条件付きです。 ベータ係数は、モデルが異なる予測変数に割り当てる重みです。
このイベント発生確率を期待値に変換するには、確率にイベントの値 (クリック予測の eCPC 目標) を乗算し、推定に加算オフセットを追加し、最小/最大の期待値制限を適用して、誤予測の影響を軽減します。
イベントが発生する確率からインプレッションの期待値を導き出す数式は次のとおりです。
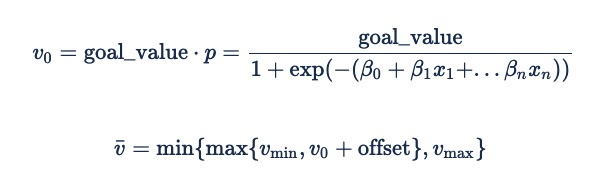
通常、オフセットは になります 0。 ただし、負の値は、パフォーマンスの低いインベントリの配信を犠牲にしてパフォーマンスを確保するためのセキュリティ要因として役立つ場合があります。 これにより、広告主は、入札が非常に少なく、固定料金が発生する可能性がある代わりに、入札が行われなくなります。
ロジスティック回帰カスタム モデルのしくみの詳細については、「 ロジスティック回帰モデル」を参照してください。
REST API
新しいロジスティック回帰モデルを追加する
POST https://api.appnexus.com/custom-model-logit
(template JSON)
ロジスティック回帰モデルを変更する
PUT https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
(template JSON)
ロジスティック回帰モデルを削除する
DELETE https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
すべてのロジスティック回帰モデルを表示する
GET https://api.appnexus.com/custom-model-logit
特定のロジスティック回帰モデルを表示する
GET https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
JSON フィールド
一般
| フィールド | 種類 | 説明 |
|---|---|---|
id |
int | ロジスティック回帰カスタム モデルの ID。 既定値: 自動生成された数値 必須: PUT/ DELETE クエリ文字列 |
name |
string | モデルの名前。 |
beta0 |
浮動小数点数 | ロジスティック回帰式で 0 係数をβします。 |
max |
浮動小数点数 | 予想される値の数式の最大値。 |
min |
浮動小数点数 | 予想される値の数式の最小値。 |
offset |
浮動小数点数 | 予想される値の数式のオフセット。 |
scale |
浮動小数点数 | 予想される値の数式でスケーリングします。 |
predictors |
配列 | 予測変数の配列。 詳細については 、以下の「予測変数」 を参照してください。 |
予測
| フィールド | 種類 | 説明 |
|---|---|---|
predictor_type |
scalar_descriptor, custom_model_descriptor, freq_rec_descriptor, segment_descriptor, categorical_descriptor |
|
keys |
||
hash_seed |
||
default_value |
||
hash_table_size_log |
||
coefficients |
ハッシュ記述子
このエンドポイントは、事前ハッシュテーブルを送信することです。 bucket_index0 と bucket_index1では、長い 64 ビットごとに、キーとして長い値を生成するハッシュ アルゴリズムをサポートします。 現時点では、1 つのハッシュ アルゴリズムのみをサポートしています。 MurmurHash3_x64_128これは、2 つの 64 ビット整数を作成しますが、ハッシュの下位 64 ビットのみを使用します。
の bucket_index0 値は常に より (2 ^ hash_table_size_log) 小さくする必要があります。または拒否されます。
現時点では、 の bucket_index1 値は無視されます。これは将来の拡張に使用されるためです。 に値が送信される bucket_index1場合は、 である 0必要があります。 パラメーターは省略可能です。
ハッシュ テーブル キー
ハッシュ テーブル キーごとに、uint32 値が必要です。 これらの値は、たとえば、ドメイン文字列値ではなく、システム domain_idから参照している各オブジェクトの ID である必要があります。 これらの uint32 キーはバイト配列 (リトル エンディアン) に変換され、ハッシュされます。
Python の例
hash_bucket = (mmh3.hash64(bytes, seed)[ 0 ]) % table_size
| フィールド | 種類 | 説明 |
|---|---|---|
type |
||
keys |
この一覧の 1 から 5 個の記述子の配列: | |
hashed_seeds |
関数に Murmurhash3_x64_128 渡されるときに使用されるシードは、最初のシードのみが現在使用されています。配列は、複数のシードを必要とする将来の計画されたハッシュ関数用です |
|
hash_id |
既存のハッシュ テーブル ID | |
default_value |
ハッシュ テーブルに一致するものが見つからない場合に記述子によって返される値 | |
hash_table_size_log |
テーブルのキーの最大値のログ。 より 2^hash_table_size_log 大きい値は拒否されます。 hash_table_size_logの最大値は 64 です (バケットなし) |
ハッシュ記述子の例
{
"type": "hashed",
"keys": [
],
"hash_seeds": [42, 42, 42, 42, 42, 42],
"hash_id": ,
"default_value": 0,
"hash_table_size_log": 20
}
ルックアップ テーブル (LUT) 記述子
| フィールド | 種類 | 説明 |
|---|---|---|
type |
||
feature_keyword |
||
default_value |
||
initial_range_log |
||
bucket_count_log_per_range |
LUT 記述子の例
{
"type": "lookup",
"default_value": 0.1,
"features": [
{
"type": "categorical_descriptor",
"feature_keyword": "advertiser_id"
},
{
"type": "scalar_descriptor",
"feature_keyword": "user_age",
"default_value": 0
}
],
"coefficients": [
{'weight': 1.1, 'key': [1, 1]},
{'weight': 1.3, 'key': [2, 2]},
{'weight': 1.2, 'key': [3, 3]},
]
}
カテゴリ記述子
これは完全に一致するものを見つけているのでdefault_valueinitial_range_log、 パラメーターと bucket_count_log_per_range パラメーターは必要ありません。
欠損値
の -1 キー値は、欠落している機能のプレースホルダーとして使用できます。たとえば、販売者からドメインが報告されない場合などです。 それ以外の場合、LUT またはハッシュ モデルの既定値が使用されます。これは、その機能値に一致するものが見つからないためです。
| フィールド | 種類 | 説明 |
|---|---|---|
type |
||
feature_keyword |
- country- region- city- dma- postal_code- user_day- user_hour- os_family- os_extended- browser- language- user_gender- domain- ip_address- position- placement- placement_group- publisher- seller_member_id- supply_type- device_type- device_model- carrier- mobile_app- mobile_app_instance- mobile_app_bundle- appnexus_intended_audience- seller_intended_audience- spend_protection- user_group_id- advertiser_id- brand_category- creative- inventory_url_id- media_type |
|
default_value |
||
object_type |
Advertiser、 li - ne_itemcampaign (分割されていませんか? |
|
object_id |
参照先広告主の ID、 |
カテゴリ記述子の例
{
"type": "categorical_descriptor",
"feature_keyword": "city"
}
頻度記述子とレジェンシー記述子
| フィールド | 種類 | 説明 |
|---|---|---|
type |
||
feature_keyword |
frequency_lifefrequency_dailyrecency |
|
default_value |
||
object_type |
Advertiser、 line_itemcampaign (分割されていませんか? |
|
object_id |
参照先広告主の ID、 | |
default_value |
一致するものが見つからない場合に記述子によって返される値 | |
initial_range_log |
ログ バケット、初期範囲に使用されます | |
bucket_count_log_per_range |
ログ バケットに使用される、範囲あたりのバケット数 |
頻度記述子とレジェンシー記述子の例
{
"type": "frequency_recency_descriptor",
"feature_keyword": 'frequency_life',
"object_type": 'advertiser',
"object_id": 1,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
スカラー記述子
| フィールド | 種類 | 説明 |
|---|---|---|
type |
||
feature_keyword |
- appnexus_audited- cookie_age- estimated_average_price- estimated_clearing_price- predicted_iab_view_rate- predicted_video_completion_rate- self_audited- size- creative_size- spend_protection- uniform- user_age注: サイズ記述子は、モデル内の文字列 ("300x250"など) として表されますが、入札者のスカラーに変換されます。 どのサイズもシステムで技術的に有効であるため、この機能はカテゴリ的特徴ではなくスカラーとして扱われます。 |
|
default_value |
一致するものが見つからない場合に記述子によって返される値 | |
initial_range_log |
ログ バケット、初期範囲に使用されます | |
bucket_count_log_per_range |
ログ バケット、範囲あたりのバケット数に使用されます |
スカラー記述子の例
{
"type": "scalar_descriptor",
"feature_keyword": "cookie_age",
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
セグメント記述子
| フィールド | 種類 | 説明 |
|---|---|---|
type |
||
feature_keyword |
segment_valuesegment_agesegment_presence |
|
segment_id |
参照されるセグメントの ID | |
default_value |
一致するものが見つからない場合に記述子によって返される値 | |
initial_range_log |
ログ バケット、初期範囲に使用されます | |
bucket_count_log_per_range |
ログ バケット、範囲あたりのバケット数に使用されます |
セグメント記述子の例
{
"type": "segment_descriptor",
"feature_keyword": "segment_age",
"segment_id": 2,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}