Linux 기반 HDInsight에서 Apache Hadoop YARN 애플리케이션 로그에 액세스
Azure HDInsight의 Apache Hadoop 클러스터에서 Apache Hadoop YARN(Yet Another Resource Negotiator) 애플리케이션의 로그에 액세스하는 방법에 대해 알아봅니다.
Apache YARN이란?
YARN은 여러 프로그래밍 모델(예: Apache Hadoop MapReduce)을 지원하여 리소스 관리를 애플리케이션 예약/모니터링과 분리합니다. YARN은 ResourceManager(RM), 작업자 노드별 노드 관리자(NM) 및 애플리케이션별 애플리케이션 마스터(AM)를 사용합니다. 애플리케이션별 AM은 애플리케이션을 실행하기 위한 리소스(CPU, 메모리, 디스크, 네트워크)를 RM과 협상합니다. RM은 NM과 협력하여 이러한 리소스를 부여하며, 이 리소스는 컨테이너는로 부여됩니다. AM은 RM에 의해 부여받은 컨테이너의 진행률 추적합니다. 애플리케이션의 특성에 따라 애플리케이션에 여러 컨테이너가 필요할 수 있습니다.
각 애플리케이션은 여러 애플리케이션 시도로 구성될 수 있습니다. 애플리케이션이 실패할 경우 새 시도로 다시 시도할 수 있습니다. 각 시도는 하나의 컨테이너에서 실행됩니다. 어떤 의미에서 컨테이너는 YARN 애플리케이션에서 수행되는 작업의 기본 단위에 대한 컨텍스트를 제공합니다. 컨테이너의 컨텍스트 내에서 수행되는 모든 작업은 컨테이너가 주어진 단일 작업자 노드에서 수행됩니다. 자세한 내용은 Hadoop: YARN 애플리케이션 작성또는 Apache Hadoop YARN을 참조하세요.
클러스터를 확장하여 더 많은 처리량을 지원하도록 하려면 자동 크기 조정을 사용하거나 몇 가지 언어를 사용하여 수동으로 클러스터를 확장할 수 있습니다.
YARN Timeline Server
Apache Hadoop YARN Timeline Server는 완료된 애플리케이션에 대한 일반 정보를 제공합니다.
YARN Timeline Server는 다음과 같은 형식의 데이터를 포함합니다.
- 애플리케이션의 고유한 식별자인 애플리케이션 ID
- 애플리케이션을 시작한 사용자
- 애플리케이션을 완료하려고 시도한 횟수
- 지정된 애플리케이션 시도에 사용된 컨테이너
YARN 애플리케이션 및 로그
애플리케이션 로그(및 연관된 컨테이너 로그)는 문제가 있는 Hadoop 애플리케이션을 디버깅하는 데 매우 중요합니다. YARN은 애플리케이션 로그를 수집, 집계 및 저장하기 위한 유용한 프레임워크를 제공하는 로그 집계를 제공합니다.
로그 집계 기능을 사용하면 애플리케이션 로그에 좀 더 확실하게 액세스할 수 있습니다. 이 기능은 작업자 노드의 모든 컨테이너에서 로그를 집계한 후 작업자 노드당 하나의 집계된 로그 파일로 저장합니다. 로그는 애플리케이션이 완료된 후 기본 파일 시스템에 저장됩니다. 애플리케이션은 수백 수천 개의 컨테이너를 사용할 수 있지만 단일 작업자 노드에서 실행되는 모든 컨테이너에 대한 로그는 항상 단일 파일로 집계됩니다. 따라서 애플리케이션에서 사용하는 작업자 노드당 하나의 로그만 있습니다. 로그 집계는 HDInsight 클러스터 버전 3.0 이상에서 기본적으로 사용됩니다. 집계된 로그는 클러스터에 대한 기본 스토리지에 있습니다. 다음 경로는 로그에 대한 HDFS 경로입니다.
/app-logs/<user>/logs/<applicationId>
경로에서 user는 애플리케이션을 시작한 사용자의 이름입니다. applicationId는 YARN RM에서 애플리케이션에 할당한 고유 식별자입니다.
집계된 로그는 컨테이너별로 인덱싱된 이진 형식인 TFile로 작성되므로 직접 읽을 수 없습니다. 관심 있는 애플리케이션 또는 컨테이너에 대한 이러한 로그를 일반 텍스트로 보려면 YARN ResourceManager 로그 또는 CLI 도구를 사용합니다.
ESP 클러스터의 YARN 로그
Ambari의 사용자 지정 mapred-site에 두 가지 구성을 추가해야 합니다.
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net로 이동합니다. 여기서CLUSTERNAME은 클러스터의 이름입니다.Ambari UI에서 MapReduce2>구성>고급>사용자 지정 매핑 사이트로 이동합니다.
다음 속성 집합 중 하나를 추가합니다.
설정 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*설정 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>변경 내용을 저장하고 영향을 받는 모든 서비스를 다시 시작합니다.
YARN CLI 도구
ssh command 명령을 사용하여 클러스터에 연결합니다. CLUSTERNAME을 클러스터 이름으로 바꿔서 아래 명령을 편집하고 다음 명령을 입력합니다.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net다음 명령을 사용하여 현재 Yarn 애플리케이션을 실행 중인 모든 애플리케이션 ID를 나열합니다.
yarn top로그를 다운로드할
APPLICATIONID열의 애플리케이션 ID를 확인합니다.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC Server이러한 로그를 다음 명령 중 하나를 실행하여 일반 텍스트로 볼 수 있습니다.
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>이러한 명령을 실행할 때 <applicationId>, <user-who-started-the-application>, <containerId> 및 <worker-node-address> 정보를 지정합니다.
기타 샘플 명령
다음 명령을 사용하여 모든 애플리케이션 마스터에 대한 YARN 컨테이너 로그를 다운로드합니다. 이 단계에서는
amlogs.txt라는 텍스트 형식의 로그 파일이 만들어집니다.yarn logs -applicationId <application_id> -am ALL > amlogs.txt다음 명령을 사용하여 최신 애플리케이션 마스터에 대한 YARN 컨테이너 로그만 다운로드합니다.
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txt다음 명령을 사용하여 처음 두 개의 애플리케이션 마스터에 대한 YARN 컨테이너 로그를 다운로드합니다.
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txt다음 명령을 사용하여 모든 YARN 컨테이너 로그를 다운로드합니다.
yarn logs -applicationId <application_id> > logs.txt다음 명령을 사용하여 특정 컨테이너에 대한 yarn 컨테이너 로그를 다운로드합니다.
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
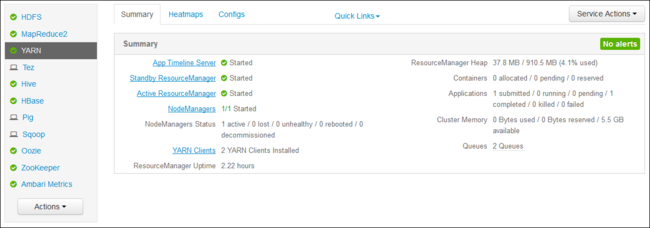
YARN ResourceManager UI
YARN ResourceManager UI는 클러스터 헤드 노드에서 실행됩니다. Ambari 웹 UI를 통해 액세스됩니다. 다음 단계를 사용하여 YARN 로그를 봅니다.
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net으로 이동합니다. CLUSTERNAME은 HDInsight 클러스터 이름을 바꿉니다.왼쪽에 있는 서비스 목록에서 YARN을 선택합니다.
빠른 링크 드롭다운에서 클러스터 헤드 노드 중 하나를 선택한 다음
ResourceManager Log를 선택합니다.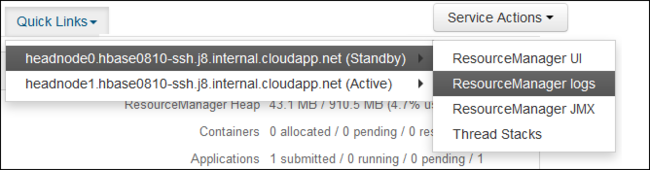
YARN 로그에 대한 링크 목록이 표시됩니다.