Azure Data Factory 및 Azure Synapse Analytics의 Parquet 형식
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
Parquet 파일을 구문 분석하거나 데이터를 Parquet 형식으로 쓰려면 이 문서의 내용을 따르세요.
Parquet 형식은 다음 커넥터에 대해 지원됩니다.
- Amazon S3
- Amazon S3 호환 스토리지
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure 파일
- 파일 시스템
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
사용 가능한 모든 커넥터에 대해 지원되는 기능 목록은 커넥터 개요 문서를 참조하세요.
자체 호스팅 통합 런타임 사용
Important
자체 호스팅 Integration Runtime에 권한을 부여한 복사(예: 온-프레미스 및 클라우드 데이터 저장소 간)의 경우 Parquet 파일을 있는 그대로 복사하지 않으면 IR 머신에 64비트 JRE(Java Runtime Environment) 8 또는 OpenJDK를 설치해야 합니다. 자세한 내용은 다음 단락을 참조하세요.
자체 호스팅 IR에서 Parquet 파일 serialization/deserialization을 사용하여 실행되는 복사의 경우 서비스는 먼저 JRE에 대한 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) 레지스트리를 검사하고, 없는 경우 OpenJDK에 대한 JAVA_HOME 시스템 변수를 검사하여 Java 런타임을 찾습니다.
- JRE 사용: 64비트 IR에는 64비트 JRE가 필요합니다. 여기서 찾을 수 있습니다.
- OpenJDK 사용: IR 버전 3.13부터 지원됩니다. OpenJDK의 다른 모든 필수 어셈블리와 함께 jvm.dll을 자체 호스팅 IR 컴퓨터에 패키지하고 그에 따라 컴퓨터 환경 변수 JAVA_HOME을 설정한 다음 자체 호스팅 IR을 다시 시작하여 즉시 적용합니다.
팁
자체 호스팅 Integration Runtime을 사용하여 데이터를 Parquet 형식으로 또는 그 반대로 복사하고 “java를 호출할 때 오류가 발생함, 메시지: java.lang.OutOfMemoryError:Java heap space”라는 오류가 발생하는 경우 JVM의 최소/최대 힙 크기를 조정하도록 자체 호스팅 IR을 호스트하는 머신에서 _JAVA_OPTIONS 환경 변수를 추가하여 그러한 복사 기능을 강화한 다음, 파이프라인을 다시 실행할 수 있습니다.
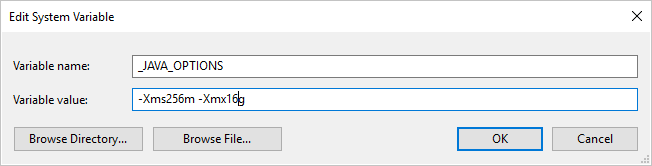
예: 변수 _JAVA_OPTIONS를 -Xms256m -Xmx16g 값으로 설정합니다. 플래그 Xms는 JVM(Java Virtual Machine)의 초기 메모리 할당 풀을 지정하고, Xmx는 최대 메모리 할당 풀을 지정합니다. 즉, JVM은 Xms의 메모리 양으로 시작하고 최대 Xmx의 메모리 양을 사용할 수 있음을 의미합니다. 기본적으로 서비스는 최소 64MB 및 최대 1G를 사용합니다.
데이터 세트 속성
데이터 세트 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트 문서를 참조하세요. 이 섹션에는 Parquet 데이터 세트에서 지원하는 속성의 목록을 제공합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 type 속성을 Parquet로 설정해야 합니다. | 예 |
| location | 파일의 위치 설정입니다. 각 파일 기반 커넥터에는 location의 고유한 위치 형식 및 지원되는 속성이 있습니다. 자세한 내용은 커넥터 문서 -> 데이터 세트 속성 섹션을 참조하세요. |
예 |
| compressionCodec | Parquet 파일에 쓸 때 사용할 압축 코덱입니다. Parquet 파일에서 읽을 때 데이터 팩터리는 파일 메타데이터를 기반으로 압축 코덱을 자동으로 결정합니다. 지원되는 형식은 없음, gzip, snappy(기본값) 및 lzo입니다. 현재 복사 작업은 Parquet 파일을 읽고 쓸 때 LZO를 지원하지 않습니다. |
아니요 |
참고 항목
Parquet 파일에서는 열 이름에 공백이 지원되지 않습니다.
다음은 Azure Blob Storage에 대한 Parquet 데이터 세트의 예입니다.
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
복사 작업 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 문서를 참조하세요. 이 섹션에서는 Parquet 원본 및 싱크에서 지원하는 속성 목록을 제공합니다.
Parquet을 원본으로
복사 작업 *source* 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 원본의 type 속성은 ParquetSource로 설정해야 합니다. | 예 |
| storeSettings | 데이터 저장소에서 데이터를 읽는 방법에 대한 속성 그룹입니다. 각 파일 기반 커넥터에는 storeSettings 아래에 고유의 지원되는 읽기 설정이 있습니다. 자세한 내용은 커넥터 문서 -> 복사 작업 속성 섹션을 참조하세요. |
아니요 |
Parquet을 싱크로
복사 작업 *sink* 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 싱크의 type 속성은 ParquetSink로 설정해야 합니다. | 예 |
| formatSettings | 속성 그룹입니다. 아래의 Parquet 쓰기 설정 표를 참조하세요. | 아니요 |
| storeSettings | 데이터 저장소에 데이터를 쓰는 방법에 대한 속성 그룹입니다. 각 파일 기반 커넥터에는 storeSettings 아래에 고유의 지원되는 쓰기 설정이 있습니다. 자세한 내용은 커넥터 문서 -> 복사 작업 속성 섹션을 참조하세요. |
아니요 |
formatSettings에서 지원되는 Parquet 쓰기 설정:
| 속성 | 설명 | 필수 |
|---|---|---|
| type | formatSettings의 type을 ParquetWriteSettings로 설정해야 합니다. | 예 |
| maxRowsPerFile | 폴더에 데이터를 쓸 때 여러 파일에 쓰도록 선택하고 파일당 최대 행 수를 지정할 수 있습니다. | 아니요 |
| fileNamePrefix | maxRowsPerFile이 구성된 경우 적용할 수 있습니다.여러 파일에 데이터를 쓸 때 파일 이름 접두사를 지정합니다. 이 패턴은 <fileNamePrefix>_00000.<fileExtension>입니다. 지정하지 않으면 파일 이름 접두사가 자동으로 생성됩니다. 원본이 파일 기반 저장소 또는 파티션 옵션 사용 데이터 저장소인 경우에는 이 속성이 적용되지 않습니다. |
아니요 |
매핑 데이터 흐름 속성
매핑 데이터 흐름에서는 Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 및 SFTP 같은 데이터 저장소에서 parquet 형식을 읽고 쓸 수 있으며 Amazon S3에서 parquet 형식을 읽을 수 있습니다.
원본 속성
다음 표에서는 parquet 원본에서 지원하는 속성을 나열합니다. 이러한 속성은 원본 옵션 탭에서 편집할 수 있습니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 형식 | 형식은 parquet여야 합니다. |
예 | parquet |
format |
| 와일드 카드 경로 | 와일드 카드 경로와 일치하는 모든 파일이 처리됩니다. 데이터 세트에 설정된 폴더 및 파일 경로를 재정의합니다. | 아니요 | String[] | wildcardPaths |
| 파티션 루트 경로 | 분할된 파일 데이터의 경우 분할된 폴더를 열로 읽기 위해 파티션 루트 경로를 입력할 수 있습니다. | 아니요 | 문자열 | partitionRootPath |
| 파일 목록 | 원본이 처리할 파일을 나열하는 문자 파일을 가리키고 있는지 여부. | 아니요 | true 또는 false |
fileList |
| 파일 이름을 저장할 열 | 원본 파일 이름 및 경로를 사용하여 새 열을 만듭니다. | 아니요 | 문자열 | rowUrlColumn |
| 완료 후 | 처리 후 파일을 삭제하거나 이동합니다. 컨테이너 루트에서 파일 경로가 시작됩니다. | 아니요 | 삭제: true 또는 false 이동: [<from>, <to>] |
purgeFiles moveFiles |
| 마지막으로 수정한 시간으로 필터링 | 마지막으로 수정된 시간에 따라 파일을 필터링하도록 선택합니다. | 아니요 | 타임스탬프 | modifiedAfter modifiedBefore |
| 파일을 찾을 수 없음 허용 | true이면 파일이 없는 경우 오류가 throw되지 않습니다. | 아니요 | true 또는 false |
ignoreNoFilesFound |
원본 예
아래 그림은 매핑 데이터 흐름에서 parquet 원본 구성의 예입니다.
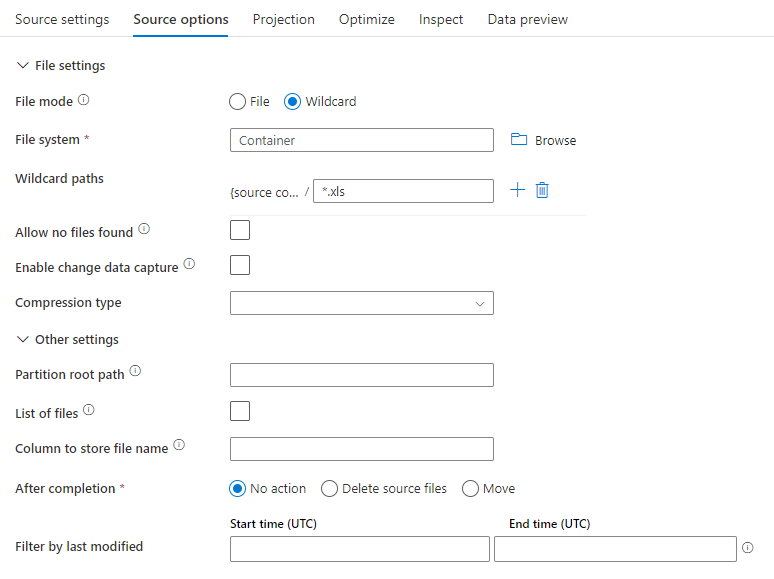
연결된 데이터 흐름 스크립트는 다음과 같습니다.
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
싱크 속성
다음 표에서는 parquet 싱크에서 지원하는 속성을 나열합니다. 이러한 속성은 설정 탭에서 편집할 수 있습니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 형식 | 형식은 parquet여야 합니다. |
예 | parquet |
format |
| 폴더 지우기 | 쓰기 전에 대상 폴더를 지운 경우 | 아니요 | true 또는 false |
truncate |
| 파일 이름 옵션 | 작성된 데이터의 명명 형식입니다. 기본적으로 파티션당 파일 하나이고 형식은 part-#####-tid-<guid>입니다. |
아니요 | 패턴: String 파티션당: String[] 열의 데이터로: String 단일 파일로 출력: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
싱크 예
아래 그림은 매핑 데이터 흐름에서 parquet 싱크 구성의 예입니다.
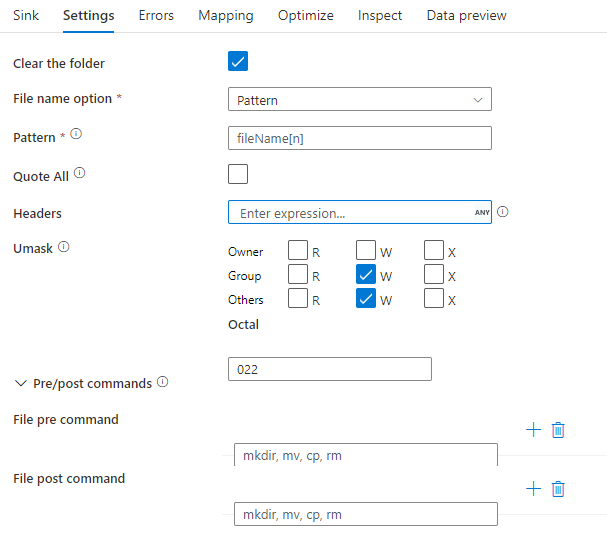
연결된 데이터 흐름 스크립트는 다음과 같습니다.
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
데이터 형식 지원
Parquet 복합 데이터 형식(예: MAP, LIST, STRUCT)은 현재 복사 작업이 아니라 데이터 흐름에서만 지원됩니다. 데이터 흐름에서 복합 형식을 사용하려면 데이터 세트에 파일 스키마를 가져오지 마세요. 데이터 세트에서 스키마를 비워두다가 원본 변환에서 프로젝션을 가져옵니다.