Azure HDInsight의 클러스터 성능 모니터링
성능과 리소스 사용률을 최적으로 유지하려면 HDInsight 클러스터의 상태 및 성능을 모니터링해야 합니다. 모니터링도 클러스터 구성 오류 및 사용자 코드 문제를 검색하고 해결하는 데 도움이 될 수 있습니다.
다음 섹션에서는 클러스터의 부하 및 Apache Hadoop YARN 큐의 로드를 모니터링 및 최적화하고 스토리지 제한 문제를 탐지하는 방법을 설명합니다.
클러스터 부하 모니터링
Hadoop 클러스터는 클러스터의 부하가 모든 노드에 균등하게 분산될 때 최적의 성능을 제공할 수 있습니다. 이렇게 하면 처리 작업이 RAM, CPU 또는 개별 노드의 디스크 리소스에 제약되지 않고 실행됩니다.
클러스터의 노드와 노드의 로드를 대략적인 수준에서 살펴보려면 Ambari 웹 UI에 로그인한 다음, 호스트 탭을 선택합니다. 호스트는 정규화된 도메인 이름별로 나열됩니다. 각 호스트의 운영 상태는 색이 지정된 상태 표시기로 표시됩니다.
| 색 | 설명 |
|---|---|
| 빨간색 | 호스트에서 적어도 하나 이상의 마스터 구성 요소가 중단되었습니다. 마우스를 가져다 대면 영향을 받는 구성 요소 목록을 나열하는 도구 설명이 표시됩니다. |
| Orange | 호스트에서 하나 이상의 보조 구성 요소가 중단되었습니다. 마우스를 가져다 대면 영향을 받는 구성 요소 목록을 나열하는 도구 설명이 표시됩니다. |
| 노란색 | Ambari 서버가 3분 이상 호스트에서 하트비트를 수신하지 못했습니다. |
| 녹색 | 정상적인 실행 상태입니다. |
또한 각 호스트의 코어 수와 RAM 양, 디스크 사용량 및 로드 평균을 보여주는 열이 표시됩니다.
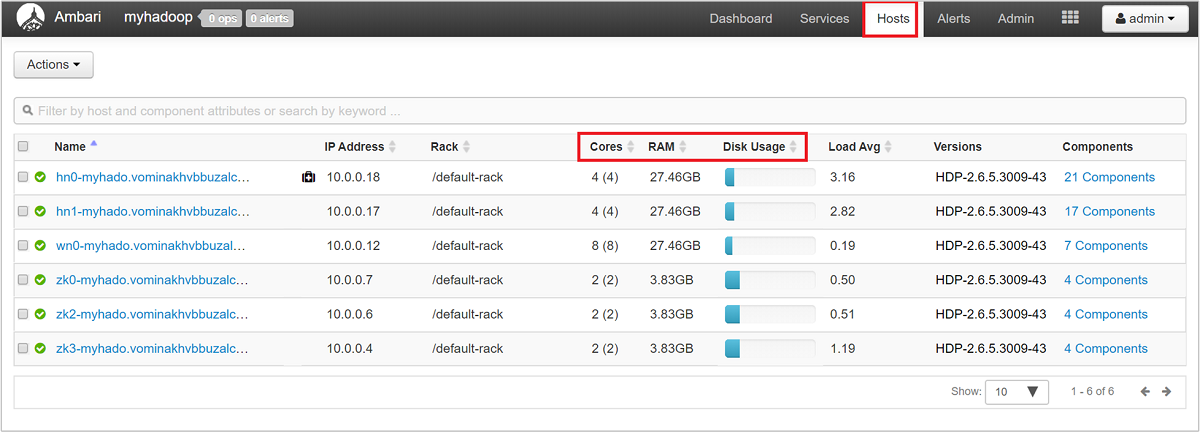
해당 호스트에서 실행되는 구성 요소와 메트릭을 자세히 살펴보려면 호스트 이름 중 하나를 선택합니다. 메트릭은 CPU 사용량, 로드, 디스크 사용량, 메모리 사용, 네트워크 사용량 및 프로세스 수에 대한 선택 가능한 타임라인으로 표시됩니다.
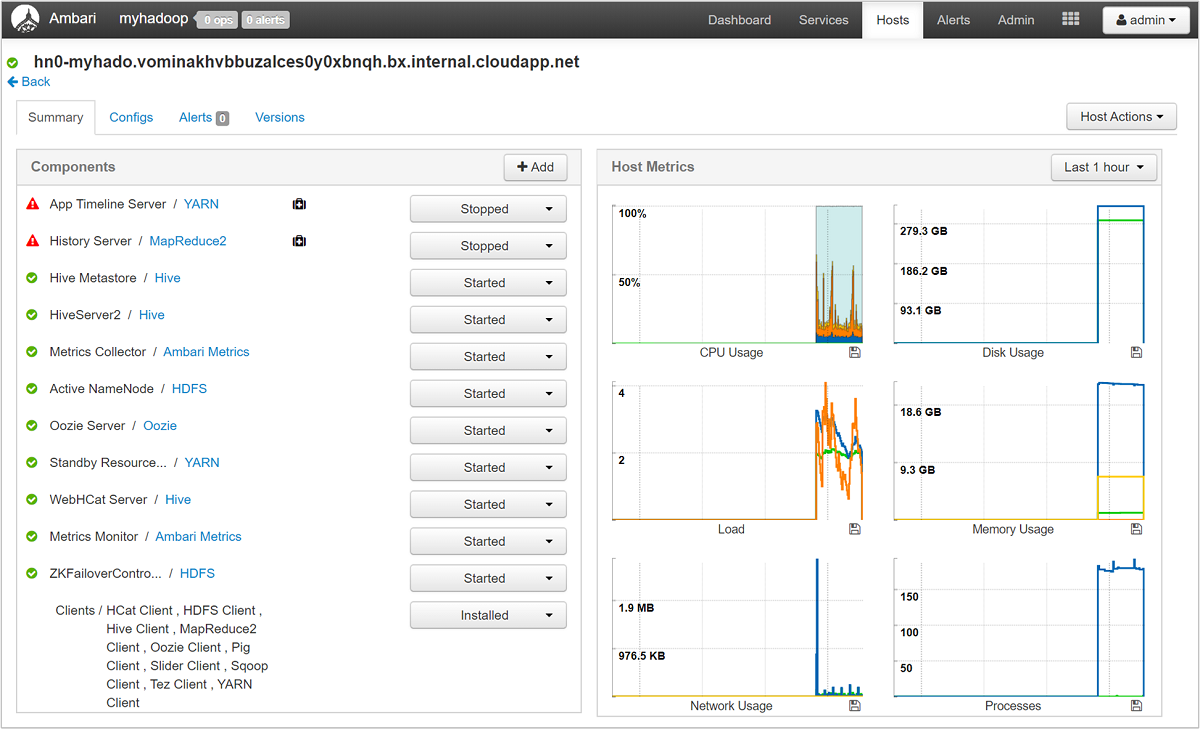
경고를 설정하고 메트릭을 보는 방법에 대한 자세한 내용은 Apache Ambari Web UI를 사용하여 HDInsight 클러스터 관리를 참조하세요.
YARN 큐 구성
Hadoop은 분산 플랫폼에서 실행되는 다양한 서비스를 갖고 있습니다. YARN(Yet Another Resource Negotiator)은 모든 부하가 클러스터 전체에 균등하게 분산되도록 이러한 서비스를 조정하고 클러스터 리소스를 할당합니다.
YARN은 JobTracker가 하는 두 가지 작업인 리소스 관리 및 일정 예약/모니터링 작업을 두 개의 디먼, 즉 글로벌 Resource Manager와 애플리케이션별 ApplicationMaster(AM)에 나눠줍니다.
Resource Manager는 순수 스케줄러로써 모든 경합 애플리케이션 간에 가용 리소스를 중재하는 일만 합니다. Resource Manager는 항상 모든 리소스를 사용하도록 보장하여 SLA, 용량 보장 등의 다양한 상수에 맞게 최적화합니다. ApplicationMaster는 Resource Manager의 리소스를 협상하고, NodeManager와 함께 작동하여 컨테이너와 컨테이너의 리소스 사용을 실행하고 모니터링합니다.
여러 테넌트가 대규모 클러스터를 공유하는 경우 클러스터의 리소스를 두고 경합이 발생합니다. CapacityScheduler는 요청을 큐에 추가하여 리소스 공유를 도와주는 플러그형 스케줄러입니다. CapacityScheduler 역시 다른 애플리케이션의 큐가 무료 리소스를 사용하도록 허용하기 전에 조직의 하위 큐 간에 리소스를 공유하도록 계층적 큐를 지원합니다.
YARN은 이러한 큐에 리소스를 할당할 수 있도록 허용하며 모든 가용 리소스의 할당 여부를 보여줍니다. 큐에 대한 정보를 보려면 Ambari 웹 UI에 로그인한 다음, 상단의 메뉴에서 YARN 큐 관리자를 선택합니다.
YARN 큐 관리자 페이지의 왼쪽에는 큐 목록과 각 큐에 할당된 용량 백분율이 표시됩니다.
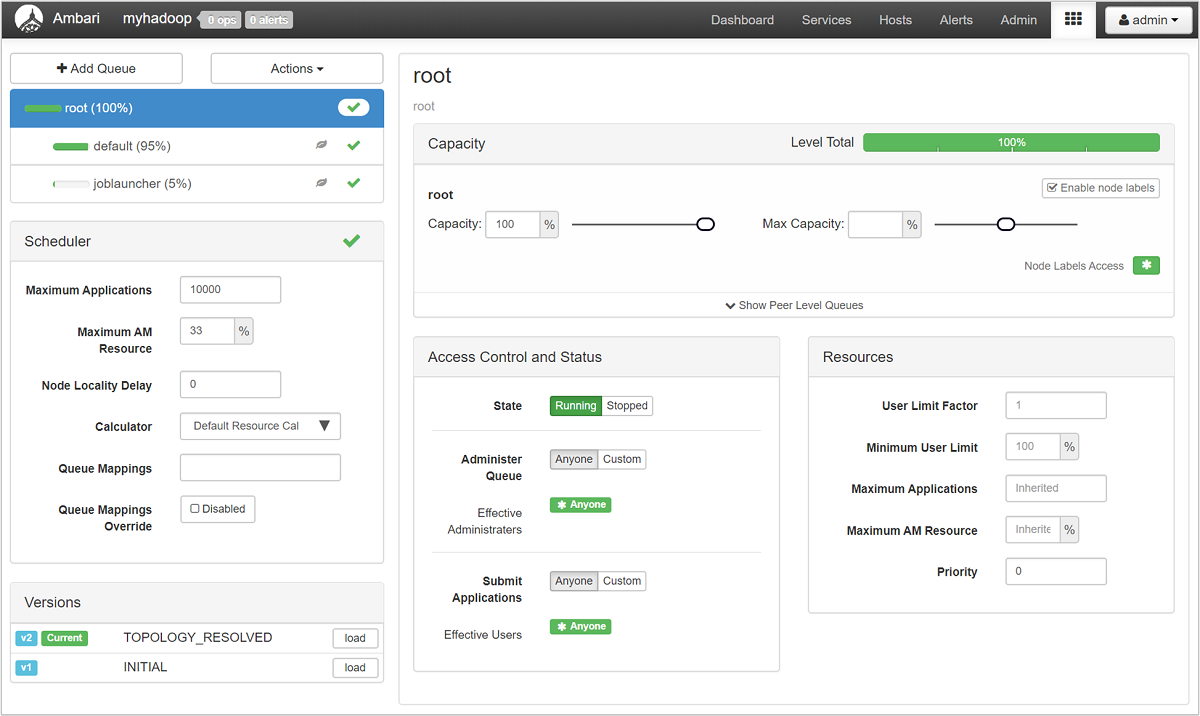
큐에 대한 세부 정보를 보려면 Ambari 대시보드의 왼쪽에 있는 목록에서 YARN 서비스를 선택합니다. 그런 다음, 빠른 연결 드롭다운 메뉴에서 활성 노드 아래의 Resource Manager UI를 선택합니다.
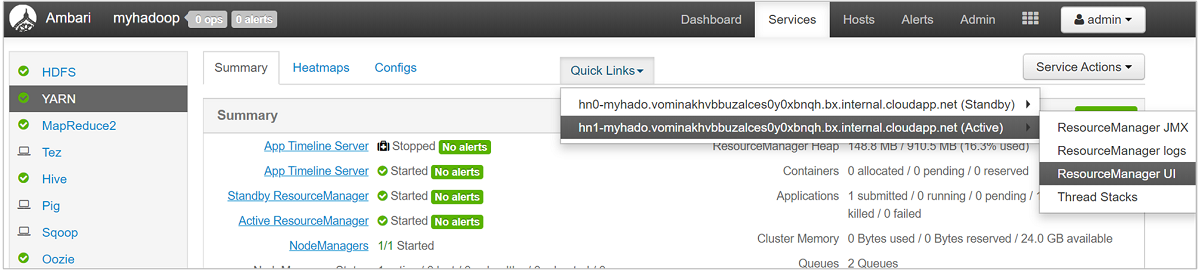
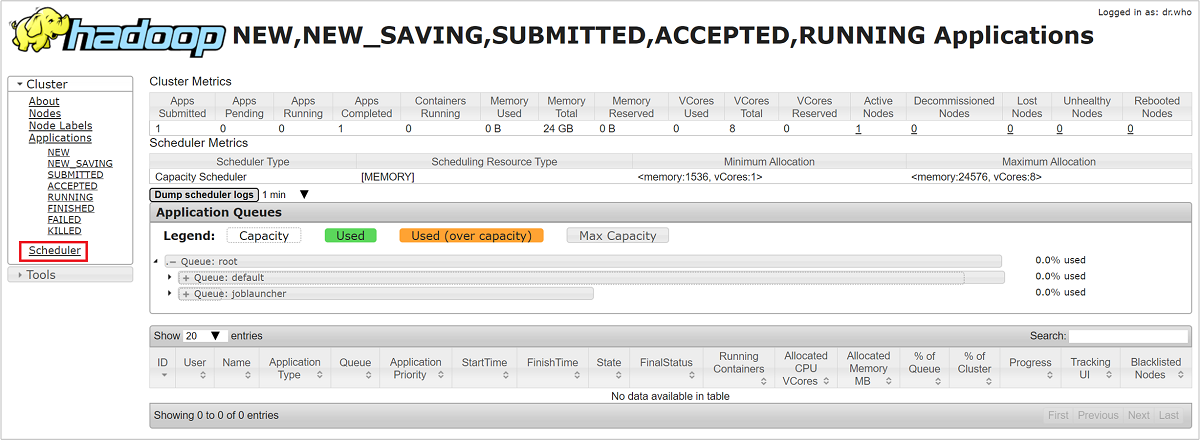
Resource Manager UI의 왼쪽 메뉴에서 스케줄러를 선택합니다. 애플리케이션 큐 아래에 큐 목록이 보입니다. 여기서 각 큐에 사용되는 용량, 작업이 큐 간에 얼마나 잘 분산되었는지 여부, 리소스가 제한된 작업이 있는지 여부를 볼 수 있습니다.
스토리지 제한
스토리지 수준에서 클러스터의 성능 병목 상태가 발생할 수 있습니다. 이러한 병목 상태의 주요 원인은 IO(입력/출력) 작업 차단이며, 작업 차단은 실행 중인 작업에서 스토리지 서비스의 처리량을 초과하는 IO를 보낼 때 발생합니다. 작업이 차단되면 현재 IO를 처리한 후 처리될 때까지 대기하는 IO 요청 큐가 생성됩니다. 이 차단은 스토리지 제한 때문에 발생하는데, 물리적 제한이 아닌 SLA(서비스 수준 계약)에 따른 스토리지 서비스의 제한에 의해 발생합니다. 이 제한은 단일 클라이언트 또는 테넌트가 서비스를 독점하지 못하게 방지하는 역할을 합니다. SLA는 Azure Storage의 IOPS(초당 IO 수)를 제한하며, 자세한 내용은 표준 스토리지 계정의 확장성 및 성능 목표를 참조하세요.
Azure Storage를 사용하는 경우 제한을 포함하여 스토리지 관련 문제 모니터링에 대한 자세한 내용은 Microsoft Azure Storage 모니터링, 진단 및 문제 해결을 참조하세요.
클러스터의 백업 저장소가 ADLS(Azure Data Lake Storage)인 경우 제한이 발생하는 주요 원인은 대역폭 제한입니다. 이 경우 작업 로그에서 제한 오류를 확인하여 제한을 파악할 수 있습니다. ADLS에 대한 내용은 다음 문서에서 해당 서비스에 대한 제한 섹션을 참조하세요.
- HDInsight의 Apache Hive 및 Azure Data Lake Storage에 대한 성능 조정 지침
- HDInsight의 MapReduce 및 Azure Data Lake Storage에 대한 성능 조정 지침
느려지는 노드 성능 문제 해결
경우에 따라 클러스터의 디스크 공간이 부족하여 느려질 수 있습니다. 다음 단계를 사용하여 조사합니다.
ssh 명령을 사용하여 각 노드에 연결합니다.
다음 명령 중 하나를 실행하여 디스크 사용량을 확인합니다.
df -h du -h --max-depth=1 / | sort -h출력을 검토하고
mnt폴더 또는 다른 폴더에 큰 파일이 있는지 확인합니다. 일반적으로usercache및appcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) 폴더에 큰 파일이 있습니다.큰 파일이 있는 경우 현재 작업으로 인해 파일이 커졌거나 이전 작업이 실패하여 이 문제가 발생했을 수 있습니다. 현재 작업으로 인해 이 동작이 발생한 것인지 확인하려면 다음 명령을 실행합니다.
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/이 명령이 특정 작업을 나타내는 경우 다음과 유사한 명령을 사용하여 해당 작업을 선택적으로 종료할 수 있습니다.
yarn application -kill -applicationId <application_id>application_id을(를) 애플리케이션 ID로 바꿉니다. 특정 작업이 나타나지 않으면 다음 단계로 이동합니다.위의 명령이 완료된 후 또는 특정 작업이 나타나지 않는 경우 다음과 유사한 명령을 실행하여 식별한 큰 파일을 삭제합니다.
rm -rf filecache usercache
디스크 공간 문제에 대한 자세한 내용은 디스크 공간 부족을 참조하세요.
참고 항목
유지하려고 하지만 디스크 공간 부족 문제를 일으킬 수 있는 큰 파일이 있는 경우 HDInsight 클러스터를 확장하고 서비스를 다시 시작해야 합니다. 이 절차를 완료하고 몇 분 정도 기다리면 스토리지가 해제되고 노드의 일반적인 성능이 복원됩니다.
다음 단계
다음 연결을 방문하여 클러스터 문제 해결 및 모니터링에 대해 자세히 알아봅니다.