Grafana의 Prometheus를 사용하여 애플리케이션 라우팅 추가 항목에서 ingress-nginx 컨트롤러 메트릭 모니터링(미리 보기)
애플리케이션 라우팅 추가 항목의 ingress-nginx 컨트롤러는 애플리케이션의 성능과 사용량을 분석하는 데 도움이 될 수 있는 요청, nginx 프로세스 및 컨트롤러에 대한 많은 메트릭을 노출합니다.
애플리케이션 라우팅 추가 항목은 포트 10254의 /metrics에서 Prometheus 메트릭 엔드포인트를 노출합니다.
Important
AKS 미리 보기 기능은 셀프 서비스에서 사용할 수 있습니다(옵트인 방식). 미리 보기는 "있는 그대로" 및 "사용 가능한 상태로" 제공되며 서비스 수준 계약 및 제한적 보증에서 제외됩니다. AKS 미리 보기의 일부는 고객 지원팀에서 최선을 다해 지원합니다. 따라서 이러한 기능은 프로덕션 용도로 사용할 수 없습니다. 자세한 내용은 다음 지원 문서를 참조하세요.
필수 조건
- 애플리케이션 라우팅 추가 항목이 설정된 AKS(Azure Kubernetes Service) 클러스터.
- Prometheus용 Azure Monitor 관리형 서비스와 같은 Prometheus 인스턴스.
- Azure Managed Grafana와 같은 Grafana 인스턴스.
메트릭 엔드포인트 유효성 검사
메트릭이 수집되고 있는지 확인하려면 ingress-nginx 컨트롤러 Pod 중 하나로 포트 전달을 설정할 수 있습니다.
kubectl get pods -n app-routing-system
NAME READY STATUS RESTARTS AGE
external-dns-667d54c44b-jmsxm 1/1 Running 0 4d6h
nginx-657bb8cdcf-qllmx 1/1 Running 0 4d6h
nginx-657bb8cdcf-wgcr7 1/1 Running 0 4d6h
이제 nginx Pod 중 하나의 포트 10254에 로컬 포트를 전달합니다.
kubectl port-forward nginx-657bb8cdcf-qllmx -n app-routing-system :10254
Forwarding from 127.0.0.1:43307 -> 10254
Forwarding from [::1]:43307 -> 10254
로컬 포트(이 경우 43307)를 기록하고 브라우저에서 http://localhost:43307/metrics를 엽니다. ingress-nginx 컨트롤러 메트릭이 로드되는 것을 볼 수 있습니다.
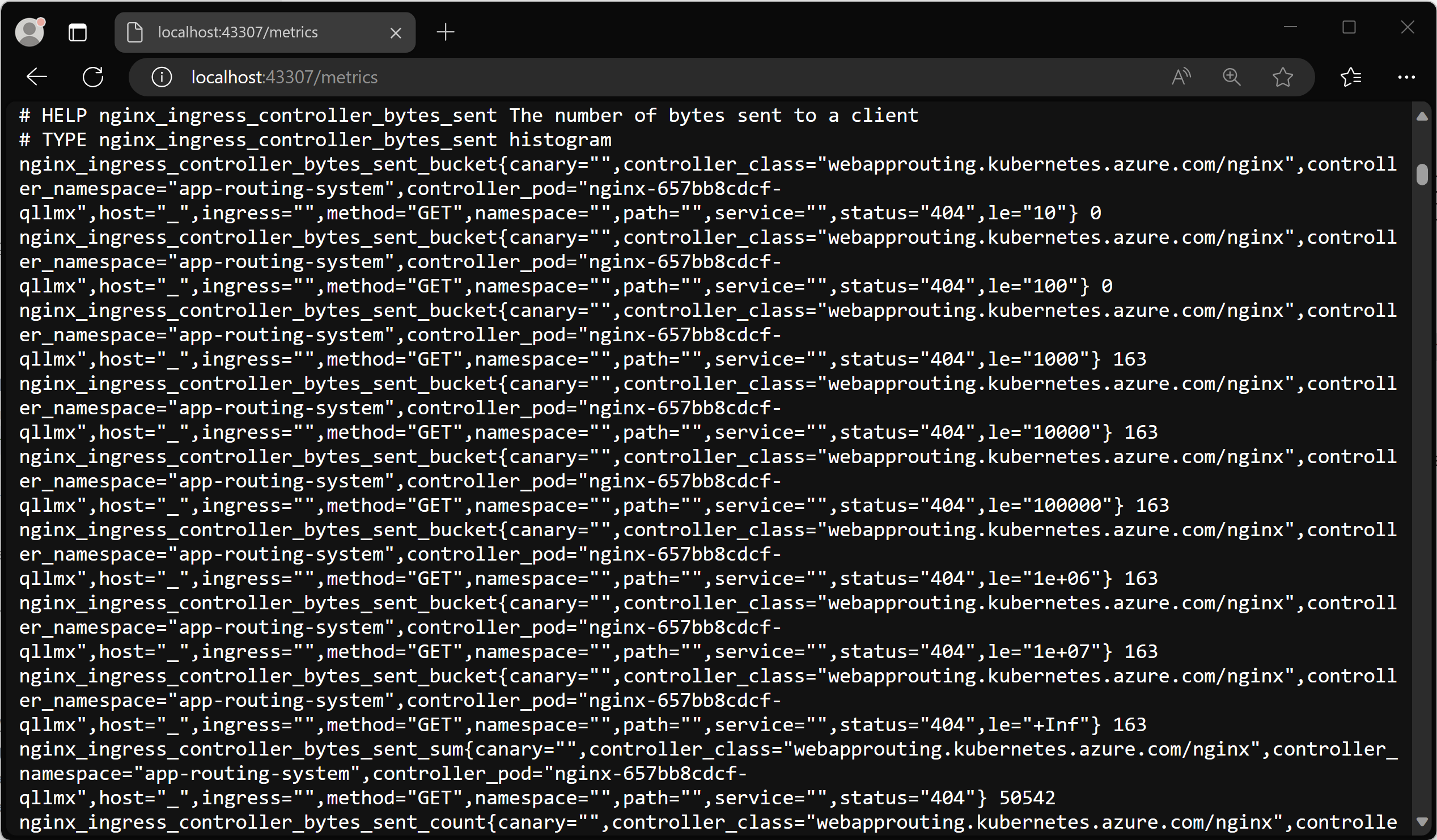
이제 port-forward 프로세스를 종료하여 전달을 닫을 수 있습니다.
Container Insights를 사용하여 Prometheus 및 Azure Managed Grafana에 대한 Azure Monitor 관리 서비스 구성
Prometheus용 Azure Monitor 관리되는 서비스는 PromQL, Grafana 대시보드 및 Prometheus 경고와 같은 업계 표준 기능을 지원하는 완전 관리형 Prometheus 호환 서비스입니다. 이 서비스를 사용하려면 Prometheus에 데이터를 보내는 Azure Monitor 에이전트용 메트릭 추가 기능을 구성해야 합니다. 클러스터가 추가 기능으로 구성되지 않은 경우 이 문서에 따라 AKS(Azure Kubernetes Service) 클러스터를 구성하여 Prometheus용 Azure Monitor 관리형 서비스로 데이터를 보내고 수집된 메트릭을 Azure Managed Grafana 인스턴스로 보낼 수 있습니다.
Pod 주석 기반 스크랩핑 사용
클러스터가 Azure Monitor 에이전트로 업데이트되면 ingress-nginx Pod에 추가되는 Pod 주석을 기반으로 스크래핑을 사용하도록 에이전트를 구성해야 합니다. 이 설정을 설정하는 한 가지 방법은 kube-system 네임스페이스의 ama-metrics-settings-configmap ConfigMap에 있습니다.
주의
그러면 kube-system의 기존 ama-metrics-settings-configmap ConfigMap이 대체됩니다. 이미 구성이 있는 경우 백업을 수행하거나 이 구성과 병합할 수 있습니다.
기존 ama-metrics-settings-config ConfigMap이 있는 경우 kubectl get configmap ama-metrics-settings-configmap -n kube-system -o yaml > ama-metrics-settings-configmap-backup.yaml을 실행하여 백업할 수 있습니다.
다음 구성에서는 모든 네임스페이스를 스크래핑하도록 podannotationnamespaceregex 매개 변수를 .*로 설정합니다.
kubectl apply -f - <<EOF
kind: ConfigMap
apiVersion: v1
metadata:
name: ama-metrics-settings-configmap
namespace: kube-system
data:
schema-version:
#string.used by agent to parse config. supported versions are {v1}. Configs with other schema versions will be rejected by the agent.
v1
config-version:
#string.used by customer to keep track of this config file's version in their source control/repository (max allowed 10 chars, other chars will be truncated)
ver1
prometheus-collector-settings: |-
cluster_alias = ""
default-scrape-settings-enabled: |-
kubelet = true
coredns = false
cadvisor = true
kubeproxy = false
apiserver = false
kubestate = true
nodeexporter = true
windowsexporter = false
windowskubeproxy = false
kappiebasic = true
prometheuscollectorhealth = false
# Regex for which namespaces to scrape through pod annotation based scraping.
# This is none by default. Use '.*' to scrape all namespaces of annotated pods.
pod-annotation-based-scraping: |-
podannotationnamespaceregex = ".*"
default-targets-metrics-keep-list: |-
kubelet = ""
coredns = ""
cadvisor = ""
kubeproxy = ""
apiserver = ""
kubestate = ""
nodeexporter = ""
windowsexporter = ""
windowskubeproxy = ""
podannotations = ""
kappiebasic = ""
minimalingestionprofile = true
default-targets-scrape-interval-settings: |-
kubelet = "30s"
coredns = "30s"
cadvisor = "30s"
kubeproxy = "30s"
apiserver = "30s"
kubestate = "30s"
nodeexporter = "30s"
windowsexporter = "30s"
windowskubeproxy = "30s"
kappiebasic = "30s"
prometheuscollectorhealth = "30s"
podannotations = "30s"
debug-mode: |-
enabled = false
EOF
몇 분 후에 kube-system 네임스페이스의 ama-metrics Pod가 다시 시작되고 새 구성을 선택해야 합니다.
Azure Managed Grafana에서 메트릭 시각화 검토
이제 Prometheus용 Azure Monitor 관리 서비스와 Azure Managed Grafana를 구성했으므로 Managed Grafana 인스턴스에 액세스해야 합니다.
Grafana 인스턴스로 다운로드하여 가져올 수 있는 두 개의 공식 ingress-nginx 대시보드 대시보드가 있습니다.
- Ingress-nginx 컨트롤러 대시보드
- 요청 처리 성능 대시보드
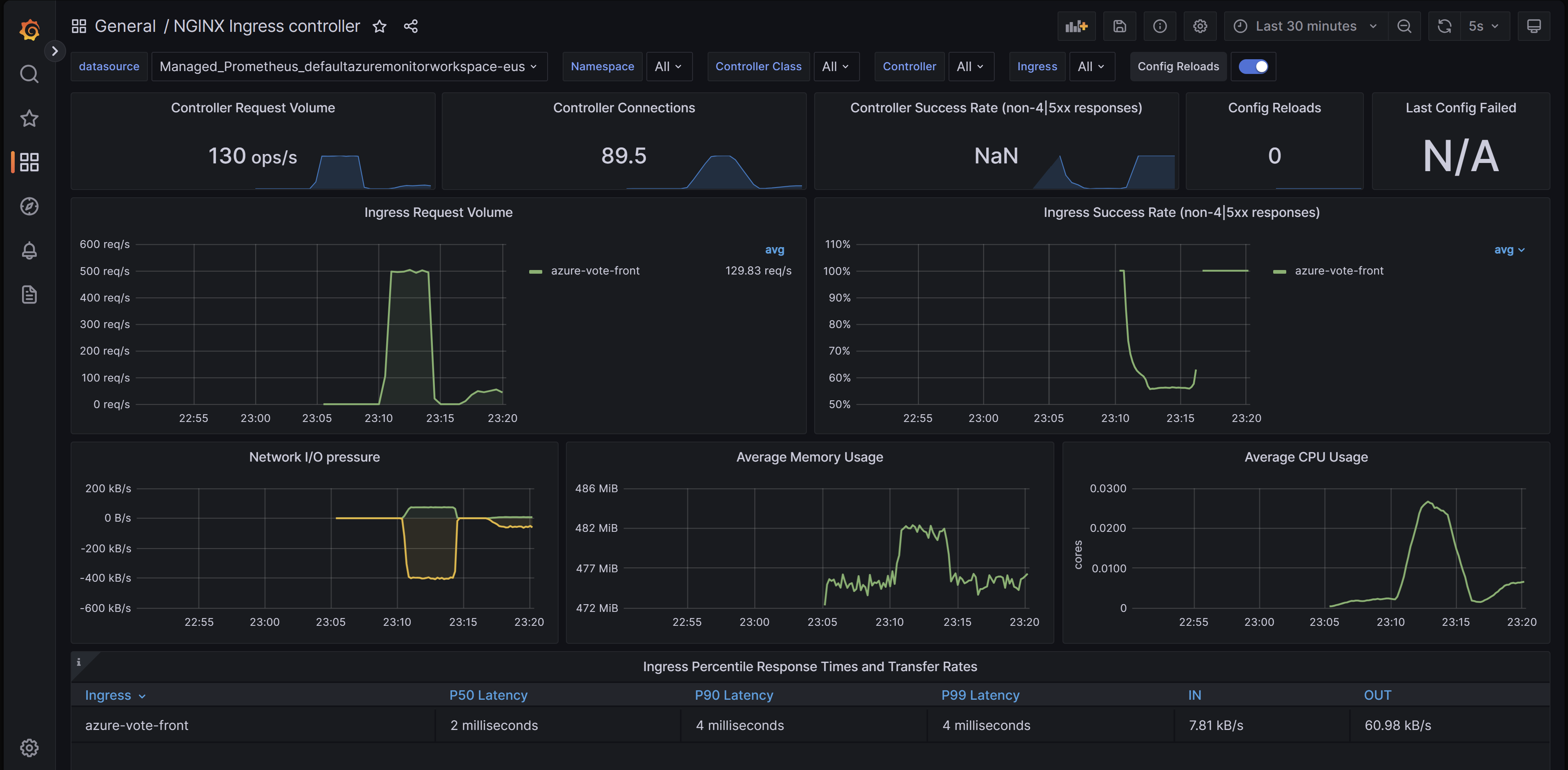
Ingress-nginx 컨트롤러 대시보드
이 대시보드는 요청 볼륨, 연결, 성공률, 구성 다시 로드 및 동기화를 벗어난 구성의 가시성을 제공합니다. 또한 이를 사용하여 수신 컨트롤러의 네트워크 IO 압력, 메모리 및 CPU 사용을 볼 수 있습니다. 마지막으로, 수신의 P50, P95 및 P99 백분위수 응답 시간과 처리량도 표시됩니다.
GitHub에서 이 대시보드를 다운로드할 수 있습니다.
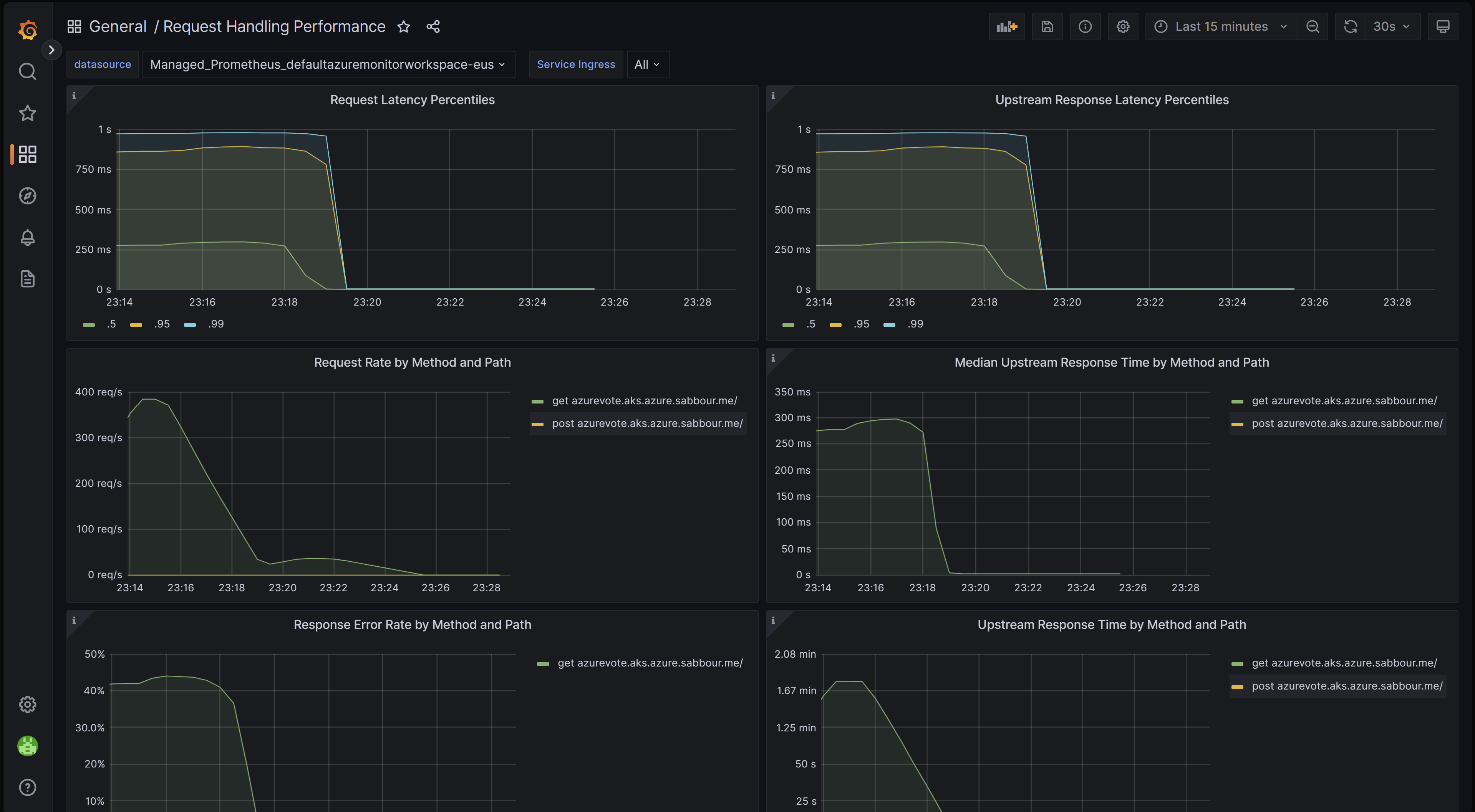
요청 처리 성능 대시보드
이 대시보드를 사용하면 수신 컨트롤러가 트래픽을 전달하는 애플리케이션의 엔드포인트인 다양한 수신 업스트림 대상의 요청 처리 성능을 확인할 수 있습니다. 총 요청 및 업스트림 응답 시간의 P50, P95 및 P99 백분위수를 표시합니다. 요청 오류 및 대기 시간의 집계도 볼 수 있습니다. 이 대시보드를 사용하여 애플리케이션의 성능 및 확장성을 검토하고 개선합니다.
GitHub에서 이 대시보드를 다운로드할 수 있습니다.
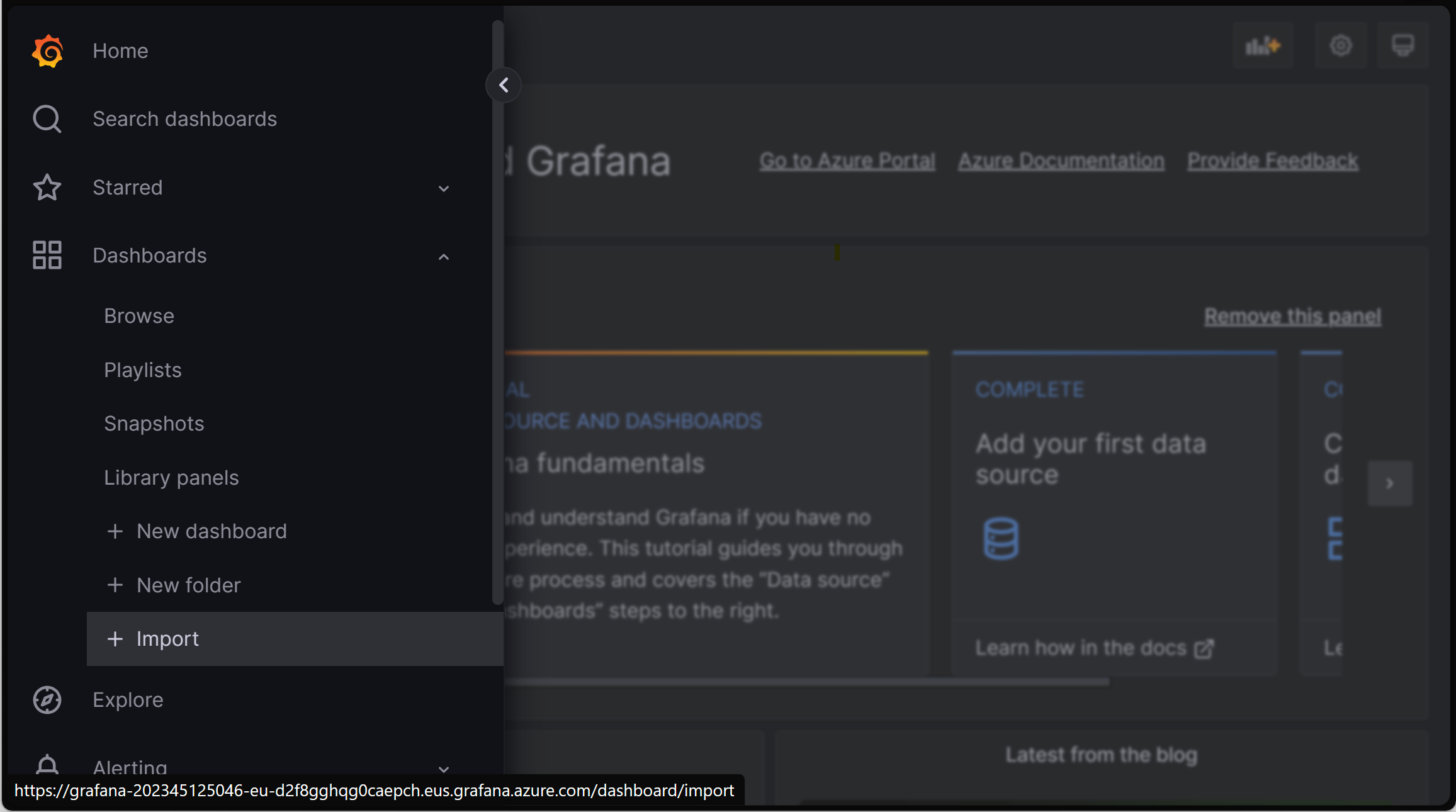
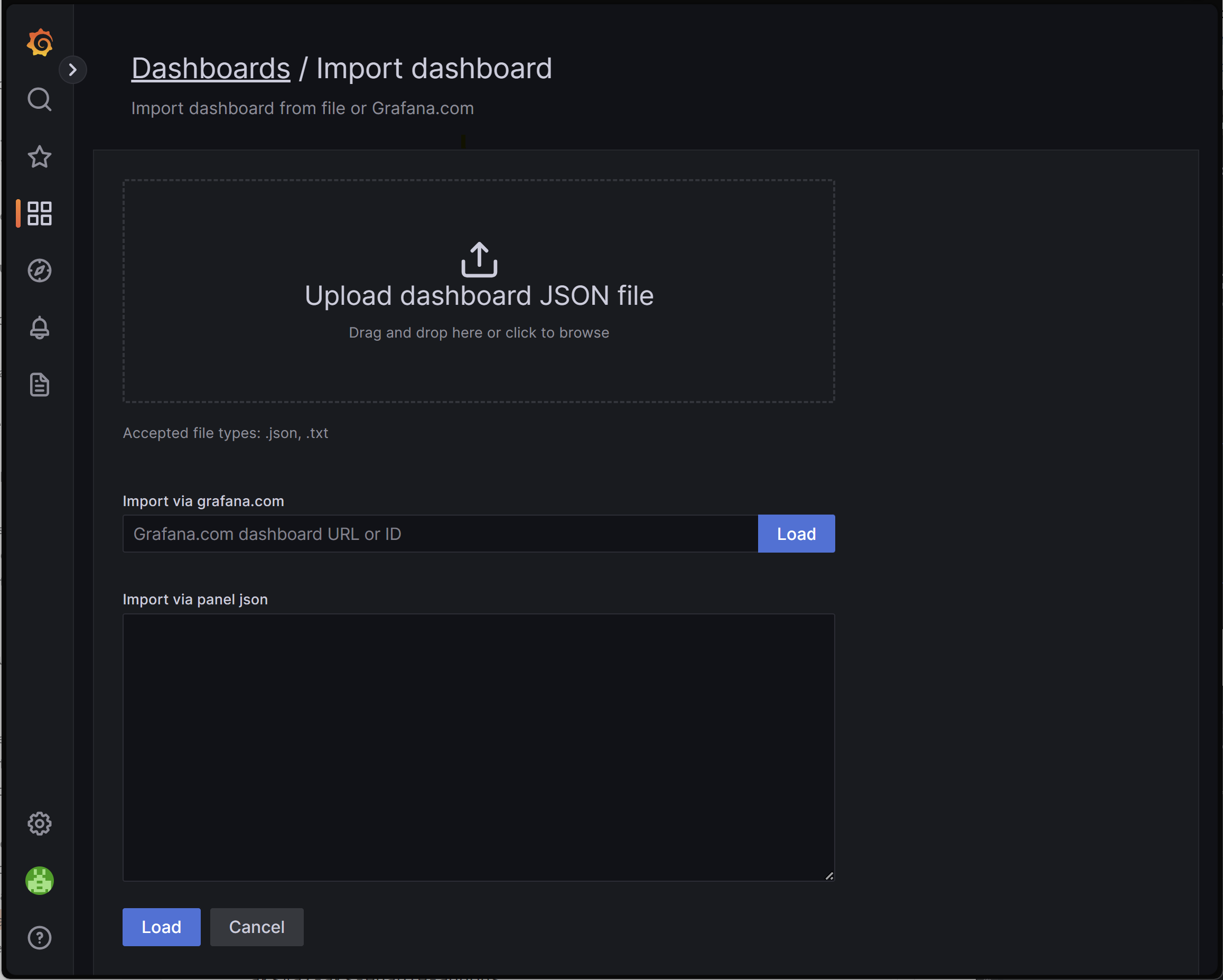
대시보드 가져오기
Grafana 대시보드를 가져오려면 왼쪽 메뉴를 확장하고 대시보드에서 가져오기를 클릭합니다.
그런 다음, 원하는 대시보드 파일을 업로드하고 로드를 클릭합니다.
다음 단계
- KEDA(Kubernetes Event Driven Autoscaler)를 사용하여 Prometheus로 스크래핑된 수신 메트릭을 사용하여 워크로드 크기를 조정할 수 있습니다. KEDA와 AKS 통합에 대해 자세히 알아봅니다.
- Azure Load Testing을 통해 부하 테스트를 만들고 실행하여 워크로드 성능을 테스트하고 애플리케이션의 확장성을 최적화합니다.

Azure Kubernetes Service