장애 조치(failover) 그룹 구성 - CLI
이 문서에서는 CLI를 사용하여 Azure Arc에서 지원하는 SQL Managed Instance의 재해 복구를 구성하는 방법을 설명합니다. 계속하기 전에 Azure Arc 지원 SQL Managed Instance - 재해 복구의 정보와 사전 요구 사항을 검토하세요.
필수 조건
Azure Arc 지원 SQL Managed Instance의 두 인스턴스 간에 장애 조치(failover) 그룹을 설정하기 전에 다음 사전 요구 사항을 충족해야 합니다.
--license-type이BasePrice또는LicenseIncluded중 하나인 기본 사이트에서 프로비전된 Azure Arc 데이터 컨트롤러 및 Arc 지원 SQL 관리되는 인스턴스.- 다음 측면에서 기본 사이트와 구성이 동일한 보조 사이트에서 프로비전된 Azure Arc 데이터 컨트롤러 및 Arc 지원 SQL 관리되는 인스턴스.
- CPU
- 메모리
- 스토리지
- 서비스 계층
- 데이터 정렬
- 기타 인스턴스 설정
- 보조 사이트의 인스턴스에는
DisasterRecovery로--license-type이 필요합니다. 이 인스턴스는 사용자 개체 없는 새 인스턴스여야 합니다.
참고 항목
- 관리되는 인스턴스를 만드는 동안
--license-type을 지정해야 합니다. 이렇게 하면 기본 데이터 센터의 주 인스턴스에서 DR 인스턴스를 시드할 수 있습니다. 배포 후 이 속성을 업데이트해도 동일한 효과가 없습니다.
배포 프로세스
두 인스턴스 간에 Azure 장애 조치(failover) 그룹을 설정하려면 다음 단계를 완료합니다.
- 주 사이트에서 분산 가용성 그룹에 대한 사용자 지정 리소스 만들기
- 보조 사이트에서 분산 가용성 그룹에 대한 사용자 지정 리소스 만들기
- 미러링 인증서에서 이진 파일 데이터 복사
- 기본 사이트와 보조 사이트 간에
sync모드 또는async모드로 분산 가용성 그룹을 설정합니다.
다음 이미지는 올바르게 구성된 분산 가용성 그룹을 보여 줍니다.
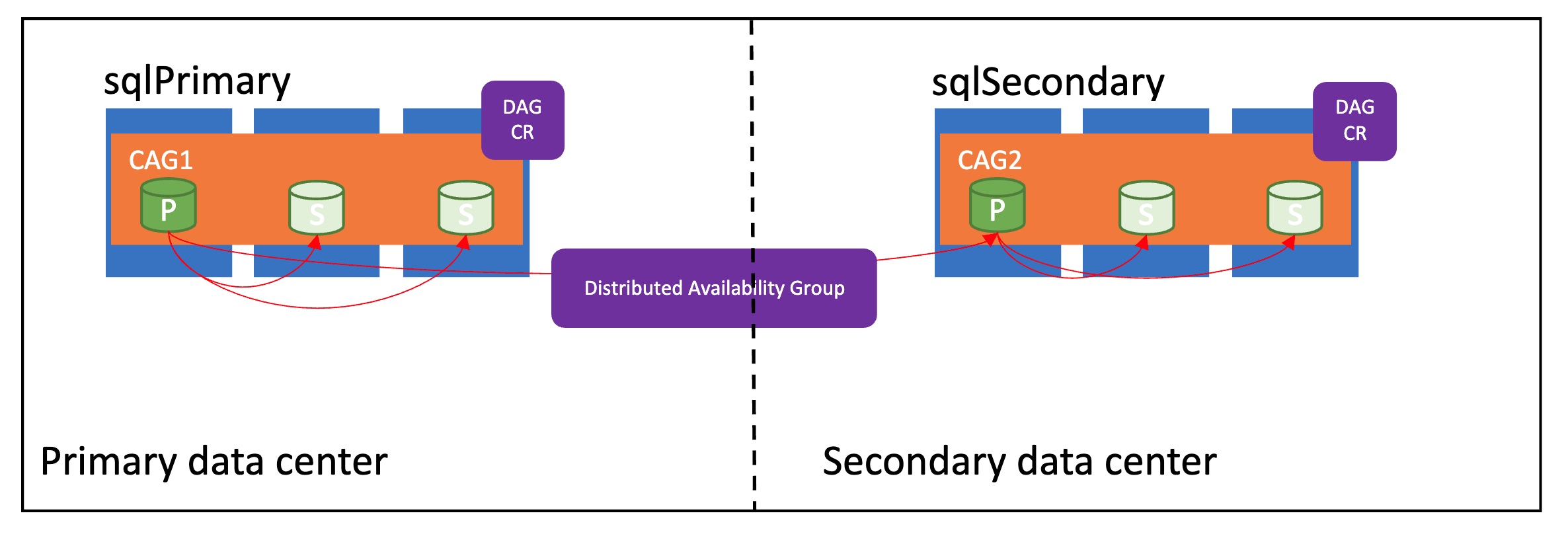
동기화 모드
Azure Arc 데이터 서비스의 장애 조치(failover) 그룹은 sync와 async라는 두 가지 동기화 모드를 지원합니다. 동기화 모드는 인스턴스 간에 데이터가 동기화되는 방식과 기본 관리되는 인스턴스의 성능에 직접적인 영향을 줍니다.
기본 사이트와 보조 사이트가 서로 몇 마일 이내인 경우 sync 모드를 사용하세요. 그렇지 않으면 기본 사이트 성능에 영향을 주지 않도록 async 모드를 사용합니다.
Azure 장애 조치(failover) 그룹 구성 - 직접 모드
Azure Arc 데이터 서비스가 directly 연결된 모드에서 배포되는 경우 다음 단계를 수행합니다.
필수 구성 요소가 충족되면 다음 명령을 실행하여 두 인스턴스 간에 Azure 장애 조치(failover) 그룹을 설정합니다.
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
예시:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
위 명령은 다음과 같습니다.
- 기본 사이트와 보조 사이트 모두에서 필요한 사용자 지정 리소스를 만듭니다.
- 미러링 인증서를 복사하고 인스턴스 간에 장애 조치(failover) 그룹을 구성합니다.
Azure 장애 조치(failover) 그룹 구성 - 간접 모드
Azure Arc 데이터 서비스가 indirectly 연결된 모드에서 배포되는 경우 다음 단계를 수행합니다.
주 사이트에서 관리되는 인스턴스를 프로비저닝합니다.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8skubectl config use-context <secondarycluster>를 실행하여 컨텍스트를 보조 클러스터로 전환하고 보조 사이트에서 재해 복구 인스턴스가 될 관리되는 인스턴스를 프로비전합니다. 이 시점에서 시스템 데이터베이스는 포함된 가용성 그룹의 일부가 아닙니다.참고 항목
관리되는 인스턴스를 만드는 동안
--license-type DisasterRecovery를 지정해야 합니다. 이렇게 하면 기본 데이터 센터의 주 인스턴스에서 DR 인스턴스를 시드할 수 있습니다. 배포 후 이 속성을 업데이트해도 동일한 효과가 없습니다.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8s미러링 인증서 - 관리되는 인스턴스의 미러링 인증서 속성 내부에 있는 이진 데이터는 인스턴스 장애 조치(failover) 그룹 CR(사용자 지정 리소스)을 만드는 데 필요합니다.
이는 몇 가지 방법으로 달성할 수 있습니다.
(a)
azCLI를 사용하는 경우 미러링 인증서 파일을 먼저 생성한 다음 인스턴스 장애 조치(failover) 그룹을 구성하는 동안 해당 파일을 가리켜 이진 데이터를 파일에서 읽어 CR에 복사하도록 합니다. 장애 조치(failover) 그룹을 만든 후에는 인증서 파일이 필요하지 않습니다.(b)
kubectl을 사용하는 경우 관리되는 인스턴스 CR의 이진 데이터를 직접 복사하여 인스턴스 장애 조치(Failover) 그룹을 만드는 데 사용할 yaml 파일에 붙여넣습니다.위의(a) 사용:
주 인스턴스에 대한 미러링 인증서 파일을 만듭니다.
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8s예시:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8s보조 클러스터에 연결하고 보조 인스턴스에 대한 미러링 인증서 파일을 만듭니다.
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8s예시:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8s미러링 인증서 파일이 만들어지면 인증서를 보조 인스턴스에서 주 인스턴스 클러스터의 공유/로컬 경로로 또는 그 반대로 복사합니다.
두 사이트 모두에 장애 조치(failover) 그룹 리소스를 만듭니다.
참고 항목
SQL 인스턴스의 기본 및 보조 사이트 이름이 서로 다른지 확인하고
shared-name값이 두 사이트에서 동일해야 합니다.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8s예시:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8s보조 인스턴스에서 다음 명령을 실행하여 장애 조치(failover) 그룹 사용자 지정 리소스를 설정합니다. 이 경우
--partner-mirroring-cert-file은 위의 3(a)에서 설명한 대로 주 인스턴스에서 생성된 미러링 인증서 파일이 있는 경로를 가리켜야 합니다.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8s예시:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Azure 장애 조치(failover) 그룹 성능 상태 검색
기본 또는 보조 사이트의 사용자 지정 리소스에서 기본 역할, 보조 역할 및 현재 성능 상태와 같은 장애 조치(failover) 그룹에 대한 정보를 확인할 수 있습니다.
기본 또는 보조 사이트에서 다음 명령을 실행하여 장애 조치(failover) 그룹 사용자 지정 리소스를 나열합니다.
kubectl get fog -n <namespace>
다음과 같이 사용자 지정 리소스를 설명하여 장애 조치(failover) 그룹 상태를 검색합니다.
kubectl describe fog <failover group cr name> -n <namespace>
장애 조치(failover) 그룹 작업
관리되는 인스턴스 간에 장애 조치(failover) 그룹이 설정되면 상황에 따라 여러 가지 장애 조치(failover) 작업을 수행할 수 있습니다.
가능한 장애 조치(failover) 시나리오는 다음과 같습니다.
두 사이트의 인스턴스는 정상 상태이지만 장애 조치(failover)를 수행해야 합니다.
- 기본 SQL MI에서
role=secondary를 설정하여 데이터 손실 없이 기본 사이트에서 보조 사이트로 수동 장애 조치(failover)를 수행합니다.
- 기본 SQL MI에서
기본 사이트는 비정상/연결 불가능 상태이며 장애 조치(failover)를 수행해야 합니다.
- Azure Arc에서 지원하는 기본 SQL Managed Instance가 다운/비정상/연결 불가능한 상태입니다.
- Azure Arc에서 지원하는 보조 SQL Managed Instance는 데이터가 손실될 수 있는 기본 사이트로 강제 승격되어야 합니다.
- Azure Arc에서 지원하는 원래 기본 SQL Managed Instance가 다시 온라인 상태가 되면
Primary역할과 비정상 상태로 보고되며 장애 조치(failover) 그룹에 조인하고 데이터를 동기화할 수 있도록secondary역할로 강제 적용되어야 합니다.
데이터가 손실되지 않는 수동 장애 조치(Failover)
az sql instance-failover-group-arc update ... 명령 그룹을 사용하여 기본 인스턴스에서 보조 인스턴스로 장애 조치(failover)를 시작합니다. 지역 주 인스턴스의 보류 중인 트랜잭션은 장애 조치(failover) 전에 지역 보조 인스턴스로 복제됩니다.
직접 연결 모드
다음 명령을 실행하여 direct 연결된 모드에서 ARM API를 사용해 수동 장애 조치(failover)를 시작합니다.
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
예시:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
간접적으로 연결된 모드
다음 명령을 실행하여 indirect 연결된 모드에서 Kubernetes API를 사용해 수동 장애 조치(failover)를 시작합니다.
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
예시:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
데이터가 손실되는 강제 장애 조치(failover)
지역 주 인스턴스를 사용할 수 없는 상황에서 지역 보조 DR 인스턴스에서 다음 명령을 실행하여 잠재적인 데이터 손실을 초래하는 강제 장애 조치(failover)와 함께 주 인스턴스로 승격할 수 있습니다.
지역 보조 DR 인스턴스에서 다음 명령을 실행하여 데이터 손실과 함께 주 역할로 승격합니다.
참고 항목
--partner-sync-mode가 sync로 구성된 경우 보조 복제본이 기본 복제본으로 승격되면 async로 초기화되어야 합니다.
직접 연결 모드
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
예시:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
간접적으로 연결된 모드
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
지역 기본 인스턴스를 사용할 수 있게 되면 다음 명령을 실행하여 장애 조치(failover) 그룹으로 가져와 데이터를 동기화합니다.
직접 연결 모드
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
간접적으로 연결된 모드
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
필요에 따라 원하는 경우 --partner-sync-mode를 다시 sync 모드로 구성할 수 있습니다.
장애 조치(failover) 후 작업
데이터 손실 유무에 관계없이 기본 사이트에서 보조 사이트로 장애 조치(failover)를 수행하면 다음을 수행해야 할 수 있습니다.
- 애플리케이션에 대한 연결 문자열을 업데이트하여 새로 승격된 기본 Arc SQL 관리되는 인스턴스에 연결합니다.
- 보조 사이트에서 프로덕션 워크로드를 계속 실행하려는 경우
--license-type을BasePrice또는LicenseIncluded로 업데이트하여 사용된 vCore에 대한 요금 청구를 시작합니다.