Power BI를 사용하여 Azure Cosmos DB 데이터 시각화
적용 대상: ![]() NoSQL
NoSQL
이 문서에서는 Azure Cosmos DB 데이터를 Power BI Desktop에 연결하는 데 필요한 단계를 설명합니다.
다음 옵션 중 하나를 사용하여 Power BI Desktop에서 Azure Cosmos DB에 연결할 수 있습니다.
Microsoft Fabric의 미러링을 사용하여 Azure Cosmos DB 데이터를 Fabric OneLake에 복제합니다. 데이터베이스에 대한 변경 내용은 원본 데이터베이스의 성능에 영향을 주거나 RU(리소스 단위)를 사용하지 않고 거의 실시간으로 Fabric OneLake에 자동으로 동기화됩니다.
그런 다음 Power BI 보고서는 DirectLake 모드를 사용하여 OneLake에서 직접 데이터에 액세스할 수 있습니다. 패브릭 내 Power BI의 향상된 Copilot 기능을 사용하여 생성 AI를 활용하여 주요 비즈니스 인사이트를 얻을 수 있습니다.
Azure Synapse Link를 사용하여 트랜잭션 워크로드에 성능이나 비용 영향이 없고 ETL 파이프라인이 없는 Power BI 보고서를 빌드합니다.
DirectQuery 또는 가져오기 모드를 사용할 수 있습니다. DirectQuery를 사용하면 데이터를 Power BI로 가져오거나 복사하지 않고도 Azure Cosmos DB 계정의 라이브 데이터를 사용하여 대시보드/보고서를 빌드할 수 있습니다.
Power BI용 Azure Cosmos DB 커넥터를 사용하여 Azure Cosmos DB 계정에 Power BI Desktop을 연결합니다. 이 옵션은 가져오기 모드에서만 사용할 수 있으며 트랜잭션 워크로드에 할당된 RU를 사용합니다.
참고 항목
Power BI Desktop에서 만든 보고서를 PowerBI.com에 게시할 수 있습니다. Azure Cosmos DB 데이터의 직접 추출은 PowerBI.com에서 수행할 수 없습니다.
필수 조건
이 Power BI 자습서의 지침을 따르기 전에 다음 리소스에 액세스할 수 있는지 확인하세요.
Azure Cosmos DB 데이터베이스 계정을 만들고 Azure Cosmos DB 컨테이너에 데이터를 추가합니다.
PowerBI.com에서 보고서를 공유하려면 PowerBI.com에 계정이 있어야 합니다. Power BI 및 Power BI Pro에 대한 자세한 내용은 https://powerbi.microsoft.com/pricing을 참조하세요.
이제 시작하겠습니다.
Microsoft Fabric에서 미러링을 사용하여 BI 보고서 빌드
기존 Azure Cosmos DB 컨테이너에서 미러링을 사용하도록 설정하고 이 데이터에 대한 BI 보고서/대시보드를 거의 실시간으로 빌드할 수 있습니다. 패브릭 및 미러링을 시작하기 위한 지침은 Azure Cosmos DB용 미러링 자습서를 참조하세요.
Azure Synapse Link를 사용하여 BI 보고서 빌드
Azure Cosmos DB 포털을 사용하여 클릭 몇 번으로 기존 Azure Cosmos DB 컨테이너에서 Azure Synapse Link를 사용하도록 설정하고 이 데이터에 대한 BI 보고서를 빌드할 수 있습니다. Power BI는 직접 쿼리 모드를 사용하여 Azure Cosmos DB에 연결하므로 트랜잭션 워크로드에 영향을 주지 않고 라이브 Azure Cosmos DB 데이터를 쿼리할 수 있습니다.
Power BI 보고서/대시보드를 빌드하려면:
Azure Portal에 로그인하고 Azure Cosmos DB 계정으로 이동합니다.
통합 섹션에서 Power BI 창을 열고 시작하기를 선택합니다.
참고 항목
현재 이 옵션은 API for NoSQL 계정에만 사용할 수 있습니다. Synapse 서버리스 SQL 풀에서 직접 T-SQL 보기를 만들고 Azure Cosmos DB for MongoDB용 BI 대시보드를 빌드할 수 있습니다. 자세한 내용은 "Power BI 및 서버리스 Synapse SQL 풀을 사용하여 Synapse로 Azure Cosmos DB 데이터 분석"을 참조하세요.
Azure Synapse Link 사용하도록 설정 탭의 이 계정에 대해 Azure Synapse Link 사용하도록 설정 섹션에서 계정에 대한 Synapse Link를 사용하도록 설정할 수 있습니다. 계정에 대해 Synapse Link가 이미 사용하도록 설정되어 있는 경우 이 탭이 표시되지 않습니다. 이 단계는 컨테이너에서 Synapse Link 사용하도록 설정을 시작하기 위한 필수 조건입니다.
참고 항목
Azure Synapse Link를 사용하도록 설정하면 비용이 듭니다. 자세한 내용은 Azure Synapse Link 가격 책정 섹션을 참조하세요.
다음으로 컨테이너에 대해 Azure Synapse Link 사용 섹션에서 Synapse Link를 사용하도록 설정하는 데 필요한 컨테이너를 선택합니다.
일부 컨테이너에서 이미 Synapse Link를 사용하도록 설정한 경우 컨테이너 이름 옆에 확인란이 선택되어 있는 것을 볼 수 있습니다. Power BI에서 시각화하려는 데이터를 기반으로 선택적으로 선택을 취소할 수 있습니다.
Synapse Link가 사용하도록 설정되지 않은 경우 기존 컨테이너에서 사용하도록 설정할 수 있습니다.
컨테이너에서 Synapse Link를 사용하도록 설정하는 것이 진행 중이면 해당 컨테이너의 데이터는 포함되지 않습니다. 나중에 이 탭으로 돌아와서 컨테이너가 사용하도록 설정되면 데이터를 가져와야 합니다.
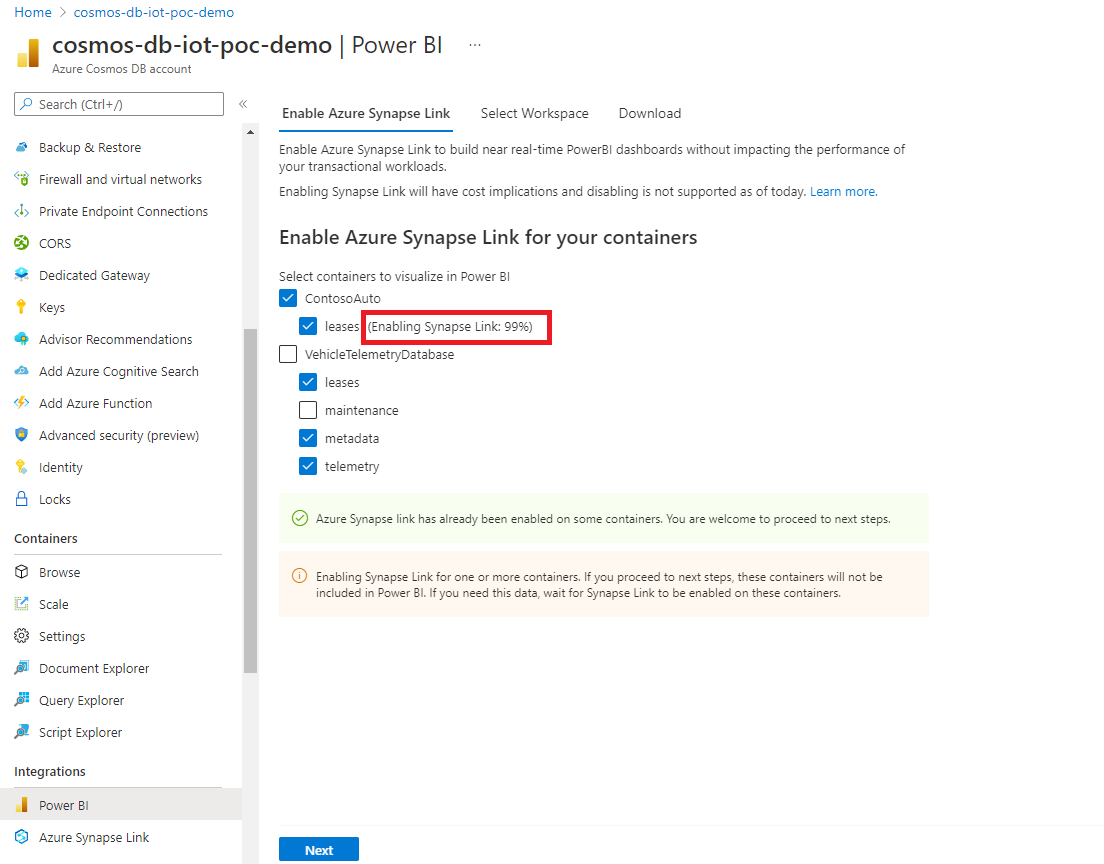
컨테이너의 데이터 양에 따라 Synapse Link를 사용하도록 설정하는 데 시간이 걸릴 수 있습니다. 자세한 내용은 기존 컨테이너에서 Synapse Link 사용 문서를 참조하세요.
다음 화면과 같이 포털에서 진행 상황을 확인할 수 있습니다. 진행률이 100%에 도달하면 컨테이너가 Synapse Link로 사용하도록 설정됩니다.
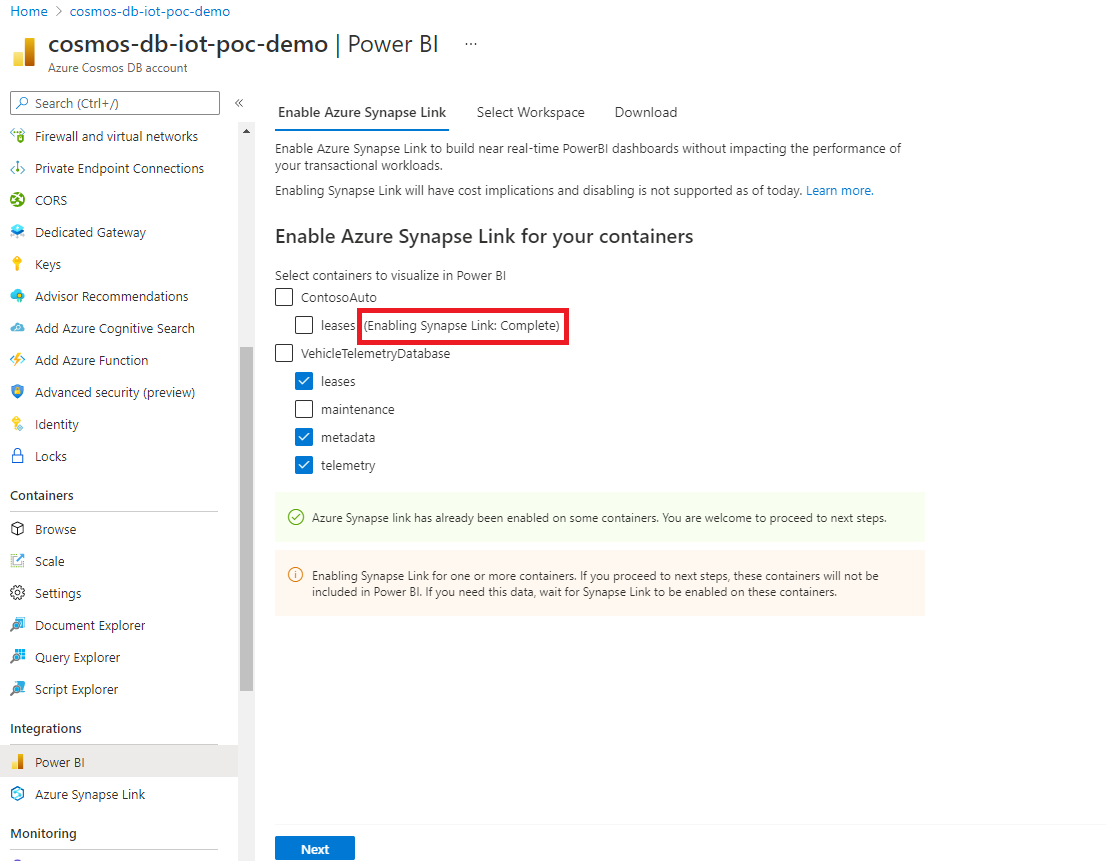
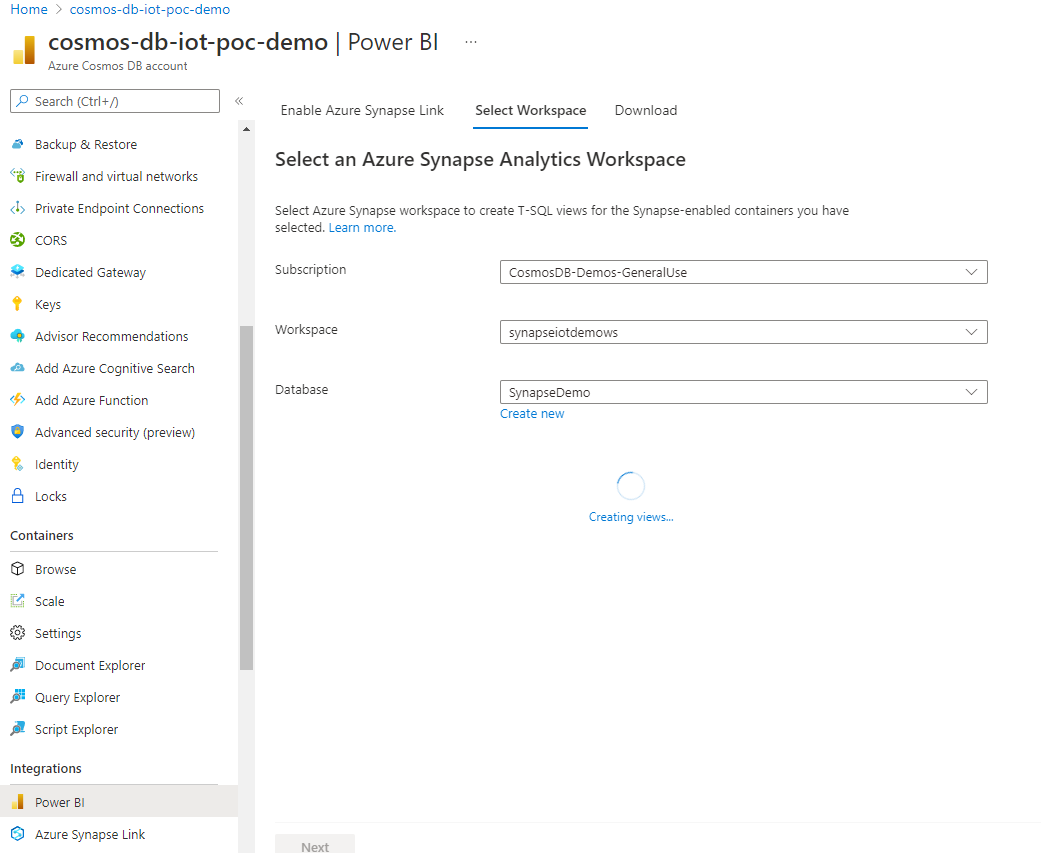
작업 영역 선택 탭에서 Azure Synapse Analytics 작업 영역을 선택하고 다음을 선택합니다. 이 단계에서는 이전에 선택한 컨테이너에 대해 Synapse Analytics에서 T-SQL 보기가 자동으로 만들어집니다. Azure Cosmos DB를 Power BI에 연결하는 데 필요한 T-SQL 보기에 대한 자세한 내용은 보기 준비 문서를 참조하세요.
참고 항목
Azure Cosmos DB 컨테이너 속성은 중첩된 JSON 데이터를 포함하여 T-SQL 보기에서 열로 표시됩니다. 이는 BI 대시보드를 위한 빠른 시작입니다. 이러한 보기는 Synapse 작업 영역/데이터베이스에서 사용할 수 있습니다. 데이터 탐색, 데이터 과학, 데이터 엔지니어링 등을 위해 Synapse Workspace에서 이와 똑같은 보기를 사용할 수도 있습니다. 고급 시나리오에서는 더 나은 성능을 위해 더 복잡한 보기 또는 이러한 보기의 미세 튜닝이 필요할 수 있습니다. 자세한 내용은 Synapse 서버리스 SQL 풀을 사용할 때 Synapse Link에 대한 모범 사례 문서를 참조하세요.
기존 작업 영역을 선택하거나 새 작업 영역을 만들 수 있습니다. 기존 작업 영역을 선택하려면 구독, 작업 영역 및 데이터베이스 세부 정보를 제공합니다. Azure Portal은 Microsoft Entra 자격 증명을 사용하여 Synapse 작업 영역에 자동으로 연결하고 T-SQL 보기를 만듭니다. 이 작업 영역에 대한 "Synapse 관리자" 권한이 있는지 확인합니다.
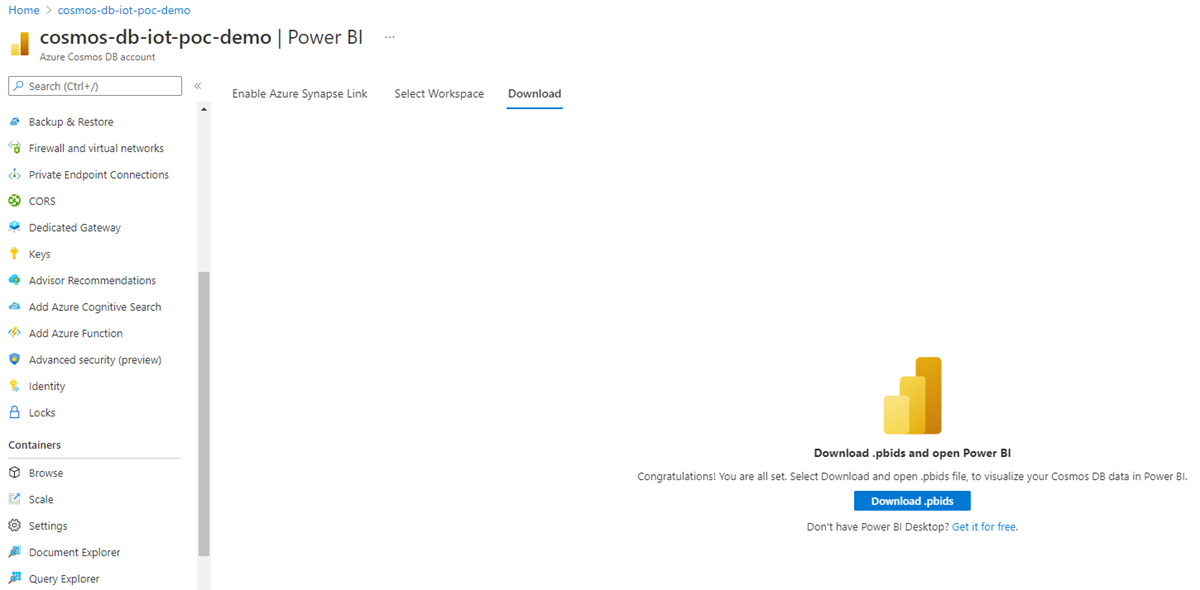
그런 다음 .pbids 다운로드를 선택하여 Power BI 데이터 원본 파일을 다운로드합니다. 다운로드한 파일을 엽니다. 여기에는 필요한 연결 정보가 포함되어 있고 Power BI Desktop이 열립니다.
이제 Power BI Desktop에서 Azure Cosmos DB 데이터에 연결할 수 있습니다. 각 컨테이너의 데이터에 해당하는 T-SQL 보기 목록이 표시됩니다.
예를 들어 다음 화면은 차량 데이터를 보여 줍니다. 추가 분석을 위해 이 데이터를 로드하거나 로드하기 전에 변환할 수 있습니다.
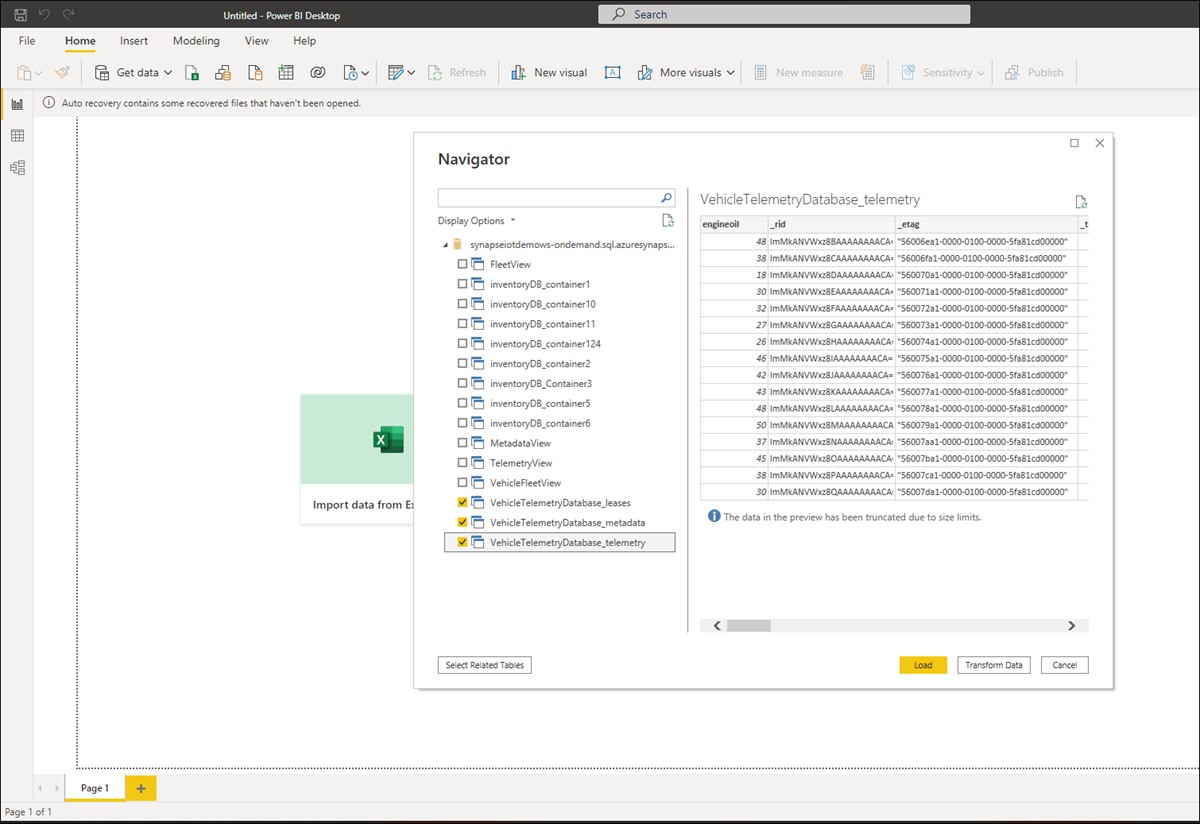
이제 Azure Cosmos DB의 분석 데이터를 사용하여 보고서 빌드를 시작할 수 있습니다. 데이터에 대한 모든 변경 내용은 일반적으로 몇 분 안에 데이터가 분석 저장소에 복제되는 즉시 보고서에 반영됩니다.





Power BI 커넥터를 사용하여 BI 보고서 빌드
참고 항목
Azure Cosmos DB와 Power BI 커넥터 연결은 현재 Azure Cosmos DB for NoSQL 및 API for Gremlin 계정에서만 지원됩니다.
Power BI Desktop을 실행합니다.
시작 화면에서 직접 데이터를 가져오고, 최근 원본 또는 다른 보고서를 열 수 있습니다. 화면을 닫으려면 오른쪽 상단 모서리의 “X”를 선택합니다. Power BI 데스크톱의 보고서 뷰가 표시됩니다.
홈 리본 메뉴를 선택한 다음 데이터 가져오기를 클릭합니다. 데이터 가져오기 창이 나타납니다.
Azure를 클릭하고 Azure Cosmos DB(베타)를 선택한 다음, 연결을 클릭합니다.
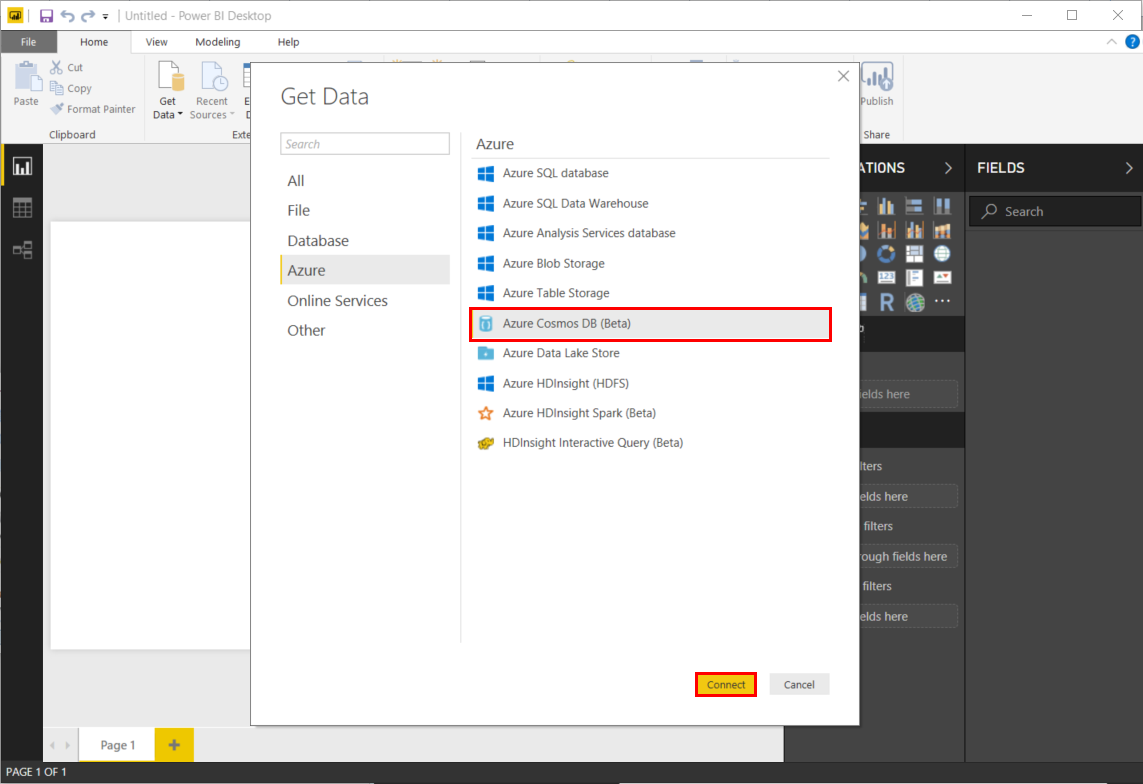
커넥터 미리 보기 페이지에서 계속을 클릭합니다. Azure Cosmos DB 창이 나타납니다.
아래와 같이 데이터를 검색할 Azure Cosmos DB 계정 엔드포인트 URL을 지정한 다음, 확인을 클릭합니다. 자신의 계정을 사용하려면 Azure Portal의 키 블레이드에 있는 URI 상자에서 URL을 검색할 수 있습니다. 필요에 따라 데이터베이스 이름, 컬렉션 이름을 제공하거나 탐색기를 사용하여 데이터를 가져오는 위치를 식별하는 데이터베이스 및 컬렉션을 선택할 수도 있습니다.
처음으로 이 엔드포인트에 연결하는 경우 계정 키를 입력하라는 메시지가 표시됩니다. 자신의 계정을 사용하는 경우 Azure Portal의 읽기 전용 키 블레이드에 있는 기본 키 상자에서 키를 검색합니다. 적절한 키를 입력하고 연결을 클릭합니다.
보고서를 작성할 때는 읽기 전용 키를 사용하는 것이 좋습니다. 이렇게 하면 불필요하게 기본 키가 잠재적인 보안 위험에 노출되는 것을 방지할 수 있습니다. 읽기 전용 키는 Azure Portal의 키 블레이드에서 사용할 수 있습니다.
계정이 성공적으로 연결되면 탐색기 창이 표시됩니다. 탐색기는 계정의 데이터베이스 목록을 표시합니다.
보고서 데이터가 있는 데이터베이스를 클릭하고 확장합니다. 이제 검색할 데이터가 들어 있는 컬렉션을 선택합니다.
미리 보기 창에는 레코드 항목의 목록이 표시됩니다. 문서는 Power BI에서 레코드 형식으로 나타납니다. 마찬가지로, 문서 내의 중첩된 JSON 블록도 레코드입니다. 속성 문서를 열로 보려면 레코드 확장을 상징하는 반대 방향으로 2개의 화살표가 있는 회색 단추를 클릭합니다. 동일한 미리 보기 창의 컨테이너 이름 오른쪽에 있습니다.
Power BI Desktop 보고서 보기에서는 데이터를 시각화하는 보고서 만들기를 시작할 수 있습니다. 필드를 끌어서 보고서 캔버스에 놓으면 보고서를 만들 수 있습니다.
임시 및 예약의 두 가지 방법으로 데이터를 새로 고칠 수 있습니다. 데이터를 새로 고치려면 지금 새로 고침을 클릭하기만 하면 됩니다. 예약된 새로 고침 옵션에 대한 자세한 내용은 Power BI 설명서를 참조하세요.
알려진 문제 및 제한 사항
분할된 Cosmos DB 컨테이너의 경우 쿼리에 파티션 키에 필터(WHERE 절)가 포함된 경우 집계 함수가 있는 SQL 쿼리가 Cosmos DB로 전달됩니다. 집계 쿼리에 파티션 키에 대한 필터가 포함되어 있지 않으면 커넥터에서 집계를 수행합니다.
TOP 또는 LIMIT가 적용된 후에 호출되는 경우 커넥터는 집계 함수를 전달하지 않습니다. Cosmos DB는 쿼리를 처리할 때 마지막에 TOP 작업을 처리합니다. 예를 들어 다음 쿼리에서 TOP은 하위 쿼리에 적용되고 집계 함수는 해당 결과 집합 위에 적용됩니다.
SELECT COUNT(1) FROM(SELECT TOP 4 * FROM EMP) E
DISTINCT가 집계 함수에 제공된 경우 집계 함수에 DISTINCT 절이 제공되면 커넥터는 집계 함수를 Cosmos DB로 전달하지 않습니다. 집계 함수에 있는 경우 DISTINCT는 Cosmos DB SQL API에서 지원되지 않습니다.
SUM 집계 함수의 경우 SUM의 인수가 문자열, 부울 또는 null인 경우 Cosmos DB는 결과 집합으로 정의되지 않은 값을 반환합니다. 그러나 null 값이 있는 경우 커넥터는 SUM 계산의 일부로 null 값을 0으로 바꾸도록 데이터 원본에 요청하는 방식으로 Cosmos DB에 쿼리를 전달합니다.
AVG 집계 함수의 경우 SUM의 인수가 문자열, 부울 또는 null인 경우 Cosmos DB는 결과 집합으로 정의되지 않은 값을 반환합니다. 커넥터는 이 기본 Cosmos DB 동작을 재정의해야 하는 경우 AVG 집계 함수를 Cosmos DB에 전달하지 않도록 설정하는 연결 속성을 제공합니다. AVG 전달을 사용하지 않도록 설정하면 Cosmos DB로 전달되지 않으며 커넥터가 직접 AVG 집계 작업을 수행합니다. 자세한 내용은 고급 옵션에서 "AVERAGE 함수 전달 사용"을 참조하세요.
큰 파티션 키가 있는 Azure Cosmos DB 컨테이너는 현재 커넥터에서 지원되지 않습니다.
서버 제한으로 인해 다음 구문에 대해 집계 전달을 사용할 수 없습니다.
쿼리가 파티션 키에서 필터링되지 않거나 파티션 키 필터가 WHERE 절의 최상위 수준에 있는 다른 조건자와 함께 OR 연산자를 사용하는 경우입니다.
쿼리에 하나 이상의 파티션 키가 있는 경우 WHERE 절의 IS NOT NULL 절에 표시됩니다.
V2 커넥터는 배열, 개체 및 계층 구조와 같은 복잡한 데이터 형식을 지원하지 않습니다. 이러한 시나리오에서는 [Fabric Mirroring for Azure Cosmos DB](/articles/cosmos-db/analytics-and-business-intelligence-overview.md 기능을 사용하는 것이 좋습니다.
V2 커넥터는 처음 1,000개 문서의 샘플링을 사용하여 유추된 스키마를 작성합니다. 문서의 일부만 업데이트되는 경우 스키마 진화 시나리오에는 권장되지 않습니다. 예를 들어 수천 개의 문서가 있는 컨테이너의 한 문서에 새로 추가된 속성은 유추된 스키마에 포함되지 않을 수 있습니다. 이러한 시나리오에서는 Fabric Mirroring for Azure Cosmos DB 기능을 사용하는 것이 좋습니다.
현재 V2 커넥터는 개체 속성에서 문자열이 아닌 값을 지원하지 않습니다.
서버 제한으로 인해 다음 구문에 대해 필터 전달을 사용할 수 없습니다.
WHERE 절에서 하나 이상의 집계 열을 포함하는 쿼리가 참조되는 경우입니다.
다음 단계
- Power BI에 대한 자세한 내용은 Power BI 시작을 참조하세요.
- Azure Cosmos DB에 대한 자세한 내용은 Azure Cosmos DB 설명서 방문 페이지를 참조하세요.