Azure Data Factory 템플릿을 사용하여 데이터베이스에서 Azure Data Explorer로 대량 복사
Azure Data Explorer는 빠른 완전 관리형 데이터 분석 서비스입니다. 애플리케이션, 웹 사이트 및 IoT 디바이스와 같은 다양한 원본에서 스트림되는 대용량 데이터에 대한 실시간 분석을 제공합니다.
데이터를 Oracle Server, Netezza, Teradata 또는 SQL Server의 데이터베이스에서 Azure Data Explorer에 복사하려면 여러 테이블에서 대량의 데이터를 로드해야 합니다. 일반적으로 단일 테이블에서 여러 스레드를 병렬 처리하여 행을 로드할 수 있도록 각 테이블에 데이터를 분할해야 합니다. 이 문서에서는 이러한 시나리오에서 사용할 템플릿을 설명합니다.
Azure Data Factory 템플릿은 미리 정의된 Data Factory 파이프라인입니다. 이러한 템플릿을 사용하면 Data Factory를 빠르게 시작하고 데이터 통합 프로젝트의 개발 시간을 줄일 수 있습니다.
Lookup 및 ForEach 작업을 사용하여 데이터베이스에서 Azure Data Explorer로 대량 복사 템플릿을 만듭니다. 데이터를 더 빨리 복사하기 위해 템플릿을 사용하여 데이터베이스당 또는 테이블당 많은 파이프라인을 만들 수 있습니다.
중요
복사하려는 데이터의 양에 적합한 도구를 사용해야 합니다.
- 데이터베이스에서 Azure Data Explorer로 대량 복사 템플릿을 사용하여 SQL 서버 및 Google BigQuery와 같은 데이터베이스에서 Azure Data Explorer로 대량의 데이터를 복사합니다.
- Data Factory 데이터 복사 도구를 사용하여 데이터 소량 또는 중간 양의 데이터가 있는 몇 개의 테이블을 Azure Data Explorer에 복사합니다.
사전 요구 사항
- Azure 구독 평가판 Azure 계정을 만듭니다.
- Azure Data Explorer 클러스터 및 데이터베이스. 클러스터 및 데이터베이스를 만듭니다.
- 데이터 팩터리 데이터 팩터리를 만듭니다.
- 데이터 원본
ControlTableDataset 만들기
ControlTableDataset는 원본에서 파이프라인의 대상으로 복사할 데이터를 나타냅니다. 행 수는 데이터를 복사하는 데 필요한 총 파이프라인 수를 나타냅니다. ControlTableDataset를 원본 데이터베이스의 일부로 정의해야 합니다.
SQL Server 원본 테이블 형식의 예는 다음 코드에 나와 있습니다.
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
코드 요소는 다음 표에 설명되어 있습니다.
| 속성 | Description | 예제 |
|---|---|---|
| PartitionId | 복사 순서 | 1 |
| SourceQuery | 파이프라인 런타임 중에 복사할 데이터를 나타내는 쿼리입니다. | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | 대상 테이블 이름 | MyAdxTable |
ControlTableDataset의 형식이 다른 경우 해당 형식에 대해 비슷한 ControlTableDataset를 만듭니다.
데이터베이스에서 Azure Data Explorer로 대량 복사 템플릿 사용
시작하기 창에서 템플릿에서 파이프라인 만들기를 선택하여 템플릿 갤러리 창을 엽니다.
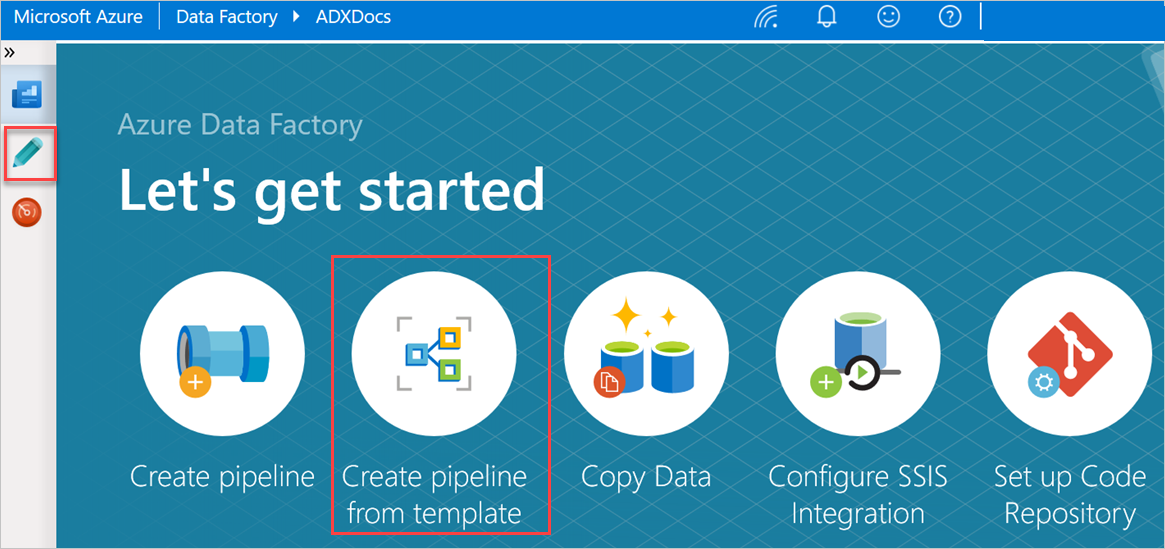
데이터베이스에서 Azure Data Explorer로 대량 복사 템플릿을 선택합니다.
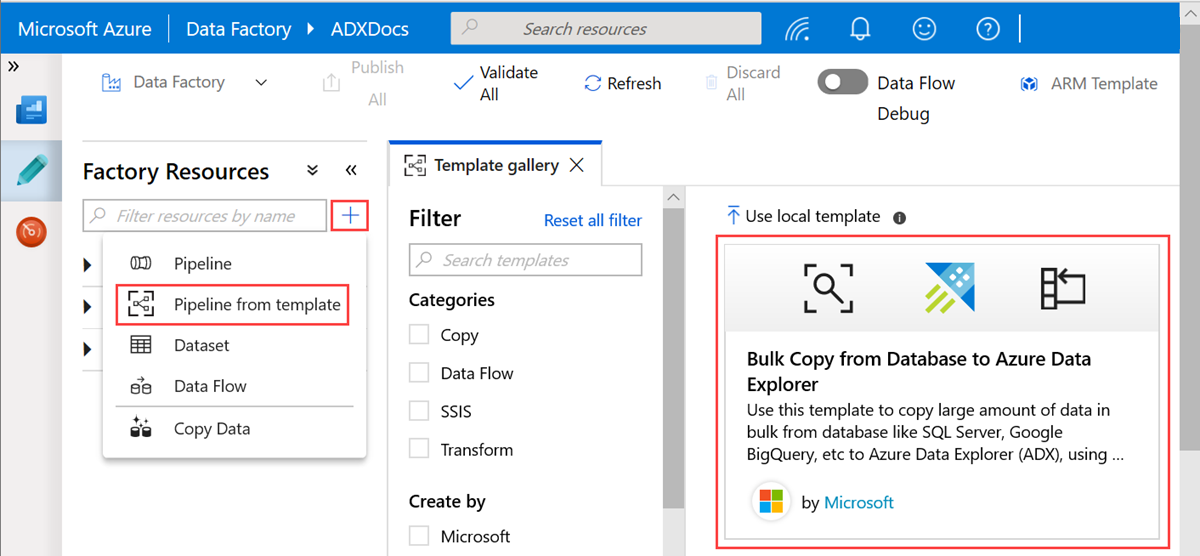
데이터베이스에서 Azure Data Explorer로 대량 복사 창의 사용자 입력 아래에서 다음을 수행하여 데이터 세트를 지정합니다.
a. ControlTableDataset 드롭다운 목록에서 원본에서 대상으로 복사되는 데이터와 대상에서 복사되는 위치를 나타내는 제어 테이블에 연결된 서비스를 선택합니다.
b. SourceDataset 드롭다운 목록에서 원본 데이터베이스에 연결된 서비스를 선택합니다.
다. AzureDataExplorerTable 드롭다운 목록에서 Azure Data Explorer 테이블을 선택합니다. 데이터 세트가 없는 경우 Azure Data Explorer 연결된 서비스를 만들어 데이터 세트를 추가합니다.
d. 이 템플릿 사용을 선택합니다.

캔버스에서 작업 외부의 영역을 선택하여 템플릿 파이프라인에 액세스합니다. 매개 변수 탭을 선택하여 이름(제어 테이블 이름) 및 기본값(열 이름)을 포함한 테이블에 대한 매개 변수를 입력합니다.
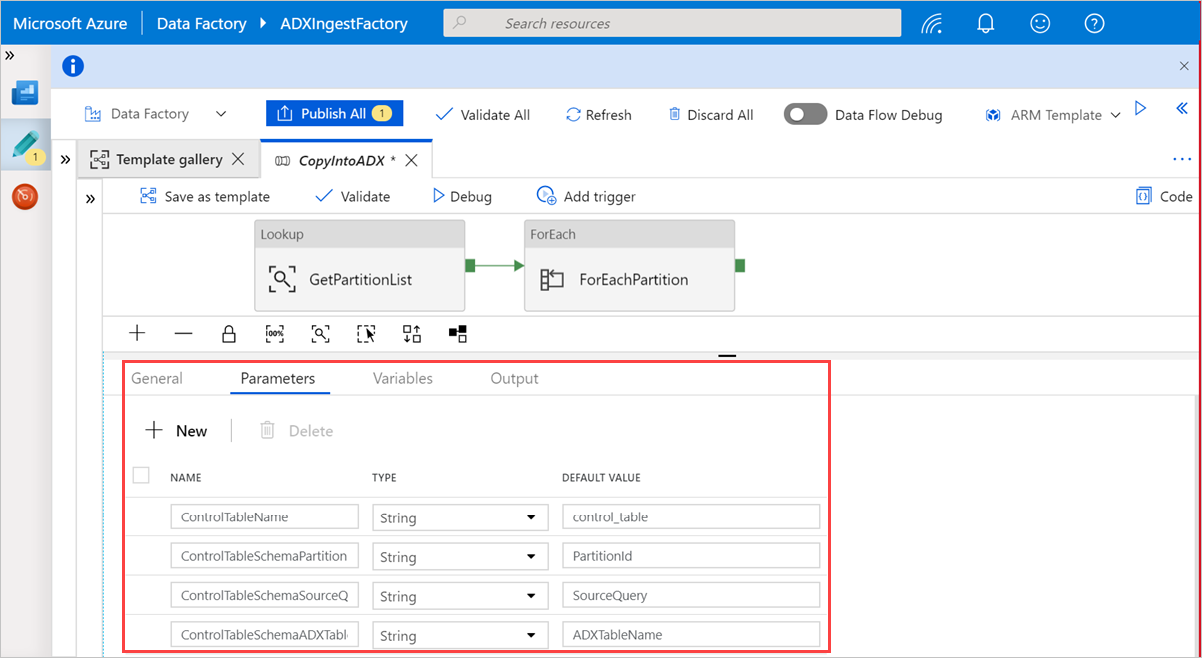
Lookup 아래에서 GetPartitionList를 선택하여 기본 설정을 확인합니다. 쿼리가 자동으로 만들어집니다.
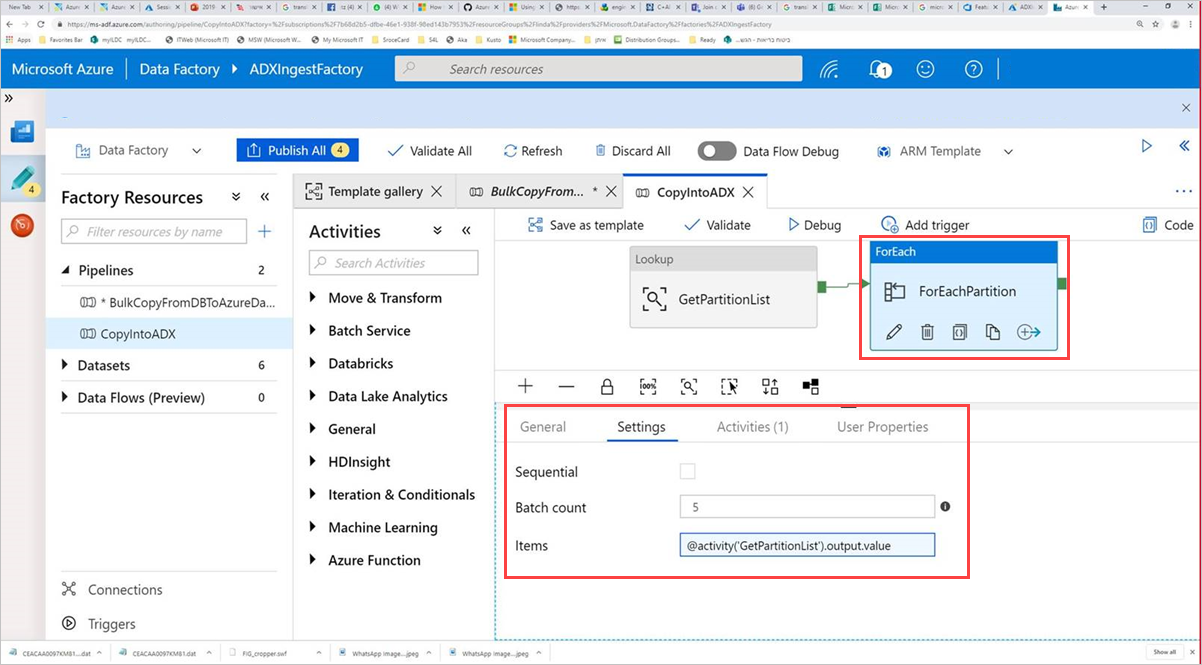
ForEachPartition 명령 작업을 선택하고, 설정 탭을 선택하고, 다음을 수행합니다.
a. 일괄 처리 수 상자에서 1~50의 숫자를 입력합니다. 이 선택 항목은 ControlTableDataset 행 수에 도달할 때까지 병렬로 실행되는 파이프라인 수를 결정합니다.
b. 파이프라인 일괄 처리가 병렬로 실행되도록 하려면 순차 확인란을 선택하지 않습니다.
팁
데이터를 더 빨리 복사할 수 있도록 많은 파이프라인을 병렬로 실행하는 것이 가장 좋습니다. 효율성을 높이려면 원본 테이블의 데이터를 분할하고 날짜 및 테이블에 따라 파이프라인당 하나의 파티션을 할당합니다.
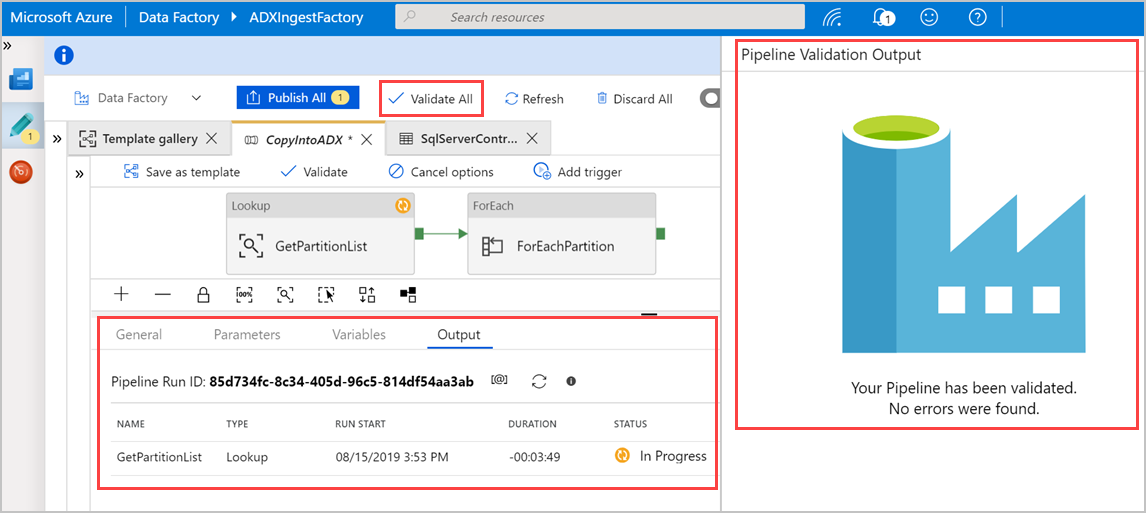
모두 유효성 검사를 선택하여 Azure Data Factory 파이프라인의 유효성을 검사한 다음, 파이프라인 유효성 검사 출력 창에서 결과를 확인합니다.
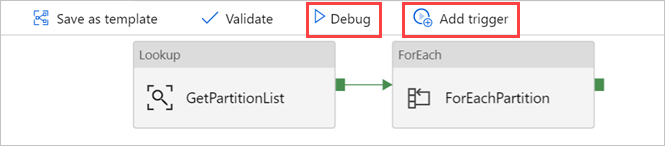
필요한 경우 디버그를 선택한 다음, 트리거 추가를 선택하여 파이프라인을 실행합니다.
이제 템플릿을 사용하여 데이터베이스 및 테이블에서 대량의 데이터를 효율적으로 복사할 수 있습니다.
관련 콘텐츠
- Azure Data Factory용 Azure Data Explorer 커넥터 에 대해 알아봅니다.
- Data Factory UI에서 연결된 서비스, 데이터 세트 및 파이프라인을 편집합니다.
- Azure Data Explorer 웹 UI에서 데이터를 쿼리합니다.