Azure Data Factory 및 Azure Synapse Analytics의 Excel 파일 형식
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
Excel 파일을 구문 분석하려는 경우 이 문서를 따릅니다. 이 서비스는 ".xls" 및 ".xlsx"을 모두 지원합니다.
Excel 형식은 Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage 및 SFTP 커넥터에 지원됩니다. 원본으로 지원되며 싱크로는 지원되지 않습니다.
참고 항목
HTTP를 사용하는 동안에는 ".xls" 형식이 지원되지 않습니다.
데이터 세트 속성
데이터 세트를 정의하는 데 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트 문서를 참조하세요. 이 섹션에서는 Excel 데이터 세트에서 지원하는 속성 목록을 제공합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 type 속성을 Excel로 설정해야 합니다. | 예 |
| location | 파일의 위치 설정입니다. 각 파일 기반 커넥터에는 자체 위치 유형과 지원되는 속성이 있습니다 location. |
예 |
| sheetName | 데이터를 읽을 Excel 워크시트 이름입니다. | sheetName 또는 sheetIndex를 지정합니다. |
| sheetIndex | 데이터를 읽을 Excel 워크시트 인덱스입니다(0부터 시작). | sheetName 또는 sheetIndex를 지정합니다. |
| range | 선택적 데이터를 찾을 수 있는 지정된 워크시트의 셀 범위입니다. 예를 들면 다음과 같습니다. - 지정되지 않음: 비어 있지 않은 첫 번째 행과 열에서 전체 워크시트를 테이블로 읽습니다. - A3: 지정된 셀에서 시작하여 테이블을 읽고 아래의 모든 행과 오른쪽의 모든 열을 동적으로 검색합니다.- A3:H5: 이 고정 범위를 테이블로 읽습니다.- A3:A3: 이 단일 셀을 읽습니다. |
아니요 |
| firstRowAsHeader | 지정된 워크시트/범위의 첫 번째 행을 열 이름의 머리글 줄로 처리할지 여부를 지정합니다. 허용되는 값은 true 및 false(기본값)입니다. |
아니요 |
| nullValue | null 값의 문자열 표현을 지정합니다. 기본값은 빈 문자열입니다. |
아니요 |
| 압축 | 파일 압축을 구성하는 속성 그룹입니다. 작업 실행 중에 압축/압축 해제를 수행하려는 경우 이 섹션을 구성합니다. | 아니요 |
| type ( compression 아래) |
JSON 파일을 읽고 쓰는 데 사용되는 압축 코덱입니다. 허용되는 값은 bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy 또는 lz4입니다. 기본값은 압축되지 않음입니다. 현재 복사 작업 "snappy" 및 "lz4"를 지원하지 않으며 매핑 데이터 흐름은 "ZipDeflate", "TarGzip" 및 "Tar"를 지원하지 않습니다. 복사 작업을 사용하여 ZipDeflate 파일의 압축을 풀고 파일 기반 싱크 데이터 저장소에 쓸 때 파일은 폴더 <path specified in dataset>/<folder named as source zip file>/에 추출됩니다. |
아니요. |
| level ( compression 아래) |
압축 비율입니다. 허용되는 값은 최적 또는 가장 빠릅니다. - 가장 빠른 속도: 결과 파일이 최적으로 압축되지 않은 경우에도 압축 작업이 가능한 한 빨리 완료되어야 합니다. - 최적: 작업을 완료하는 데 시간이 더 오래 걸리더라도 압축 작업을 최적으로 압축해야 합니다. 자세한 내용은 압축 수준 항목을 참조하세요. |
아니요 |
다음은 Azure Blob Storage에 대한 Excel 데이터 세트의 예입니다.
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
복사 작업 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 문서를 참조하세요. 이 섹션에서는 Excel 원본에서 지원하는 속성 목록을 제공합니다.
Excel을 원본으로
복사 작업 *source* 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 원본의 type 속성을 ExcelSource로 설정해야 합니다. | 예 |
| storeSettings | 데이터 저장소에서 데이터를 읽는 방법에 대한 속성 그룹입니다. 각 파일 기반 커넥터에는 storeSettings 아래에 고유의 지원되는 읽기 설정이 있습니다. |
아니요 |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
매핑 데이터 흐름 속성
매핑 데이터 흐름에서는 Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3, SFTP 데이터 저장소에서 Excel 형식을 읽을 수 있습니다. Excel 데이터 세트를 사용하거나 인라인 데이터 세트를 사용하여 Excel 파일을 가리킬 수 있습니다.
원본 속성
아래 표에서는 Excel 원본에서 지원하는 속성을 나열합니다. 원본 옵션 탭에서 이러한 속성을 편집할 수 있습니다. 인라인 데이터 세트를 사용하는 경우 데이터 세트 속성 섹션에 설명된 속성과 동일한 추가 파일 설정이 표시됩니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 와일드 카드 경로 | 와일드 카드 경로와 일치하는 모든 파일이 처리됩니다. 데이터 세트에 설정된 폴더 및 파일 경로를 재정의합니다. | 아니요 | String[] | wild카드Paths |
| 파티션 루트 경로 | 분할된 파일 데이터의 경우 분할된 폴더를 열로 읽기 위해 파티션 루트 경로를 입력할 수 있습니다. | 아니요 | 문자열 | partitionRootPath |
| 파일 목록 | 원본이 처리할 파일을 나열하는 텍스트 파일을 가리키는지 여부 | 아니요 | true 또는 false |
fileList |
| 파일 이름을 저장할 열 | 원본 파일 이름 및 경로를 사용하여 새 열을 만듭니다. | 아니요 | 문자열 | rowUrlColumn |
| 완료 후 | 처리 후 파일을 삭제하거나 이동합니다. 컨테이너 루트에서 파일 경로 시작 | 아니요 | 삭제: true 또는 false 이동: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 마지막으로 수정한 시간으로 필터링 | 마지막으로 변경된 시기에 따라 파일을 필터링하도록 선택 | 아니요 | 타임스탬프 | modifiedAfter modifiedBefore |
| 파일을 찾을 수 없음 허용 | true이면 파일이 없으면 오류가 throw되지 않습니다. | 아니요 | true 또는 false |
ignoreNoFilesFound |
원본 예
아래 이미지는 데이터 세트 모드를 사용하여 데이터 흐름을 매핑하는 Excel 원본 구성의 예입니다.
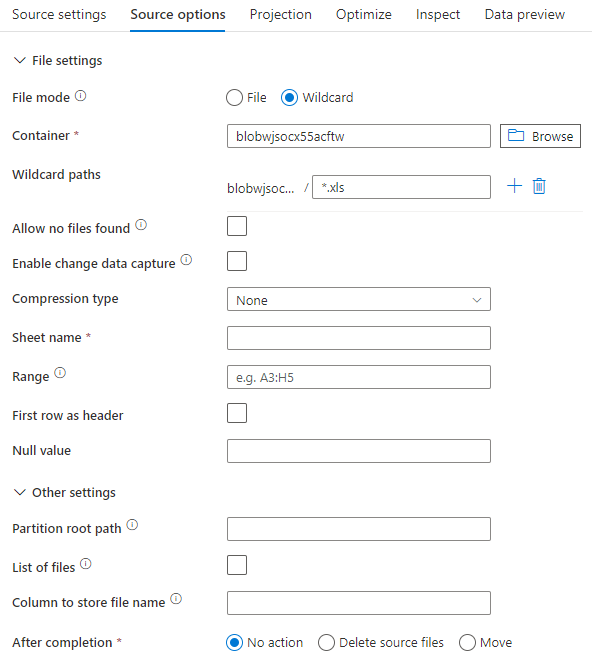
연결된 데이터 흐름 스크립트는 다음과 같습니다.
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
인라인 데이터 세트를 사용하는 경우 매핑 데이터 흐름에 다음 원본 옵션이 표시됩니다.
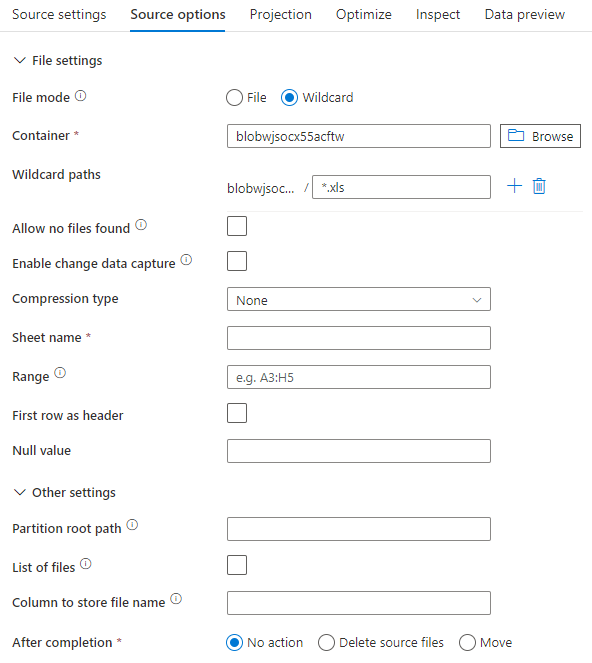
연결된 데이터 흐름 스크립트는 다음과 같습니다.
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
매우 큰 Excel 파일 처리
Excel 커넥터는 복사 작업에 대한 스트리밍 읽기를 지원하지 않으며 데이터를 읽으려면 먼저 전체 파일을 메모리에 로드해야 합니다. 스키마를 가져오거나, 데이터를 미리 보거나, Excel 데이터 세트를 새로 고치려면 HTTP 요청 시간 제한(100초) 전에 데이터를 반환해야 합니다. 큰 Excel 파일의 경우 이러한 작업이 해당 기간 내에 완료되지 않아 시간 제한 오류가 발생할 수 있습니다. 큰 Excel 파일(> 100MB)을 다른 데이터 저장소로 이동하려는 경우 다음 옵션 중 하나를 사용하여 이 제한을 해결할 수 있습니다.
- SHIR(자체 호스팅 통합 런타임)을 사용한 다음, 복사 작업을 사용하여 SHIR을 통해 큰 Excel 파일을 다른 데이터 저장소로 이동합니다.
- 큰 Excel 파일을 여러 개의 더 작은 파일로 분할한 다음, 복사 작업을 사용하여 파일이 포함된 폴더를 이동합니다.
- 데이터 흐름 작업을 사용하여 큰 Excel 파일을 다른 데이터 저장소로 이동합니다. 데이터 흐름은 Excel에 대한 스트리밍 읽기를 지원하며 큰 파일을 빠르게 이동/전송할 수 있습니다.
- 큰 Excel 파일을 CSV 형식으로 수동으로 변환한 다음, 복사 작업을 사용하여 파일을 이동합니다.