Azure SQL Database의 정규화된 데이터베이스 스키마를 Azure CosmosDB 비정규화된 컨테이너로 마이그레이션
이 가이드에서는 Azure SQL Database에서 기존의 정규화된 데이터베이스 스키마를 가져와서 Azure Cosmos DB에 로드하기 위해 Azure Cosmos DB 비정규화된 스키마로 변환하는 방법을 설명합니다.
일반적으로 SQL 스키마는 세 번째 정규 형식을 사용하여 모델링되어 높은 수준의 데이터 무결성을 제공하고 중복 데이터 값이 줄어든 정규화된 스키마가 생성됩니다. 쿼리는 테이블 간에 엔터티를 조인하여 읽을 수 있습니다. Azure Cosmos DB는 문서 내에 자체 포함된 데이터를 사용하여 비정규화된 스키마를 통해 컬렉션 또는 컨테이너 내에서 트랜잭션 및 쿼리를 매우 빠르게 처리하도록 최적화되었습니다.
Azure Data Factory를 사용하여 단일 매핑 데이터 흐름을 사용하여 기본 키와 외세 키를 엔터티 관계로 포함하는 두 개의 Azure SQL Database 정규화된 테이블에서 읽는 파이프라인을 빌드합니다. 데이터 팩터리는 데이터 흐름 Spark 엔진을 사용하여 이러한 테이블을 단일 스트림에 조인하고, 조인된 행을 배열로 수집하고, 정리된 개별 문서를 생성하여 새 Azure Cosmos DB 컨테이너에 삽입합니다.
이 가이드에서는 표준 SQL Server Adventure Works 샘플 데이터베이스의 테이블과 SalesOrderDetail 해당 테이블을 사용하는 SalesOrderHeader "orders"라는 새 컨테이너를 즉시 빌드합니다. 이러한 테이블은 SalesOrderID에 의해 조인된 판매 트랜잭션을 나타냅니다. 각 고유 세부 정보 레코드에는 고유한 기본 키가 있습니다 SalesOrderDetailID. 헤더와 세부 정보 간의 관계는 1:M입니다. ADF에 SalesOrderID 조인한 다음 각 관련 세부 정보 레코드를 "detail"라는 배열로 롤업합니다.
이 가이드의 대표 SQL 쿼리는 다음과 같습니다.
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
결과 Azure Cosmos DB 컨테이너는 내부 쿼리를 단일 문서에 포함하며 다음과 같습니다.

파이프라인을 만듭니다.
+새 파이프라인을 선택하여 새 파이프라인을 만듭니다.
데이터 흐름 작업 추가
데이터 흐름 작업에서 새 매핑 데이터 흐름을 선택합니다.
다음 데이터 흐름 그래프를 생성합니다.
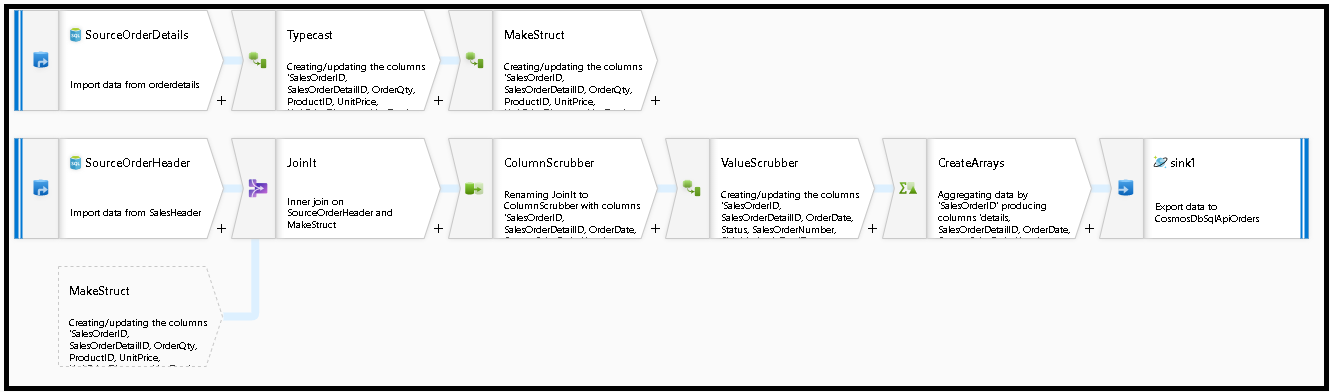
'SourceOrderDetails'의 원본을 정의합니다. 데이터 세트의 경우
SalesOrderDetail테이블을 가리키는 새 Azure SQL Database 데이터 세트를 만듭니다.'SourceOrderHeader'의 원본을 정의합니다. 데이터 세트의 경우
SalesOrderHeader테이블을 가리키는 새 Azure SQL Database 데이터 세트를 만듭니다.맨 위 원본에서 'SourceOrderDetails' 뒤에 파생 열 변환을 추가합니다. 새 변환 'TypeCast'를 호출합니다.
UnitPrice열을 반올림하고 Azure Cosmos DB의 이중 데이터 형식으로 캐스팅해야 합니다. 수식을toDouble(round(UnitPrice,2))로 설정합니다.다른 파생 열을 추가하고 'MakeStruct'라고 부릅니다. 여기서는 세부 정보 테이블의 값을 보관하는 계층 구조를 만듭니다. 세부 정보는 헤더와
M:1관계라는 점을 기억하세요. 새 구조체의 이름을orderdetailsstruct로 지정하고 이러한 방식으로 계층 구조를 만들어 각 하위 열을 들어오는 열 이름으로 설정합니다.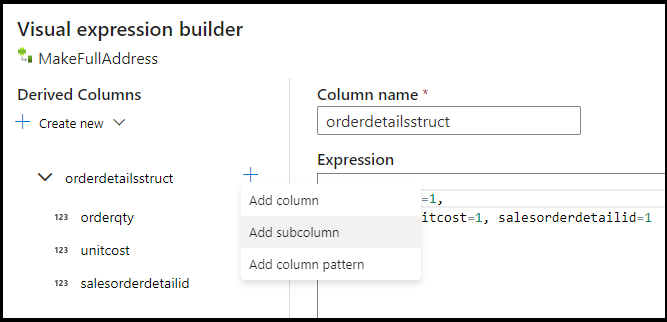
이제 sales 헤더 원본으로 이동하겠습니다. 조인 변환을 추가합니다. 오른쪽에서 'MakeStruct'를 선택합니다. 내부 조인으로 설정된 채로 두고 조인 조건의 양쪽에
SalesOrderID를 선택합니다.이 시점까지 결과를 볼 수 있도록 추가한 새 조인에서 데이터 미리 보기 탭을 선택합니다. 세부 정보 행과 조인된 헤더 행이 모두 표시되어야 합니다. 이는
SalesOrderID에서 형성된 조인의 결과입니다. 다음으로, 공통 행의 세부 정보를 세부 정보 구조체로 결합하고 공통 행을 집계합니다.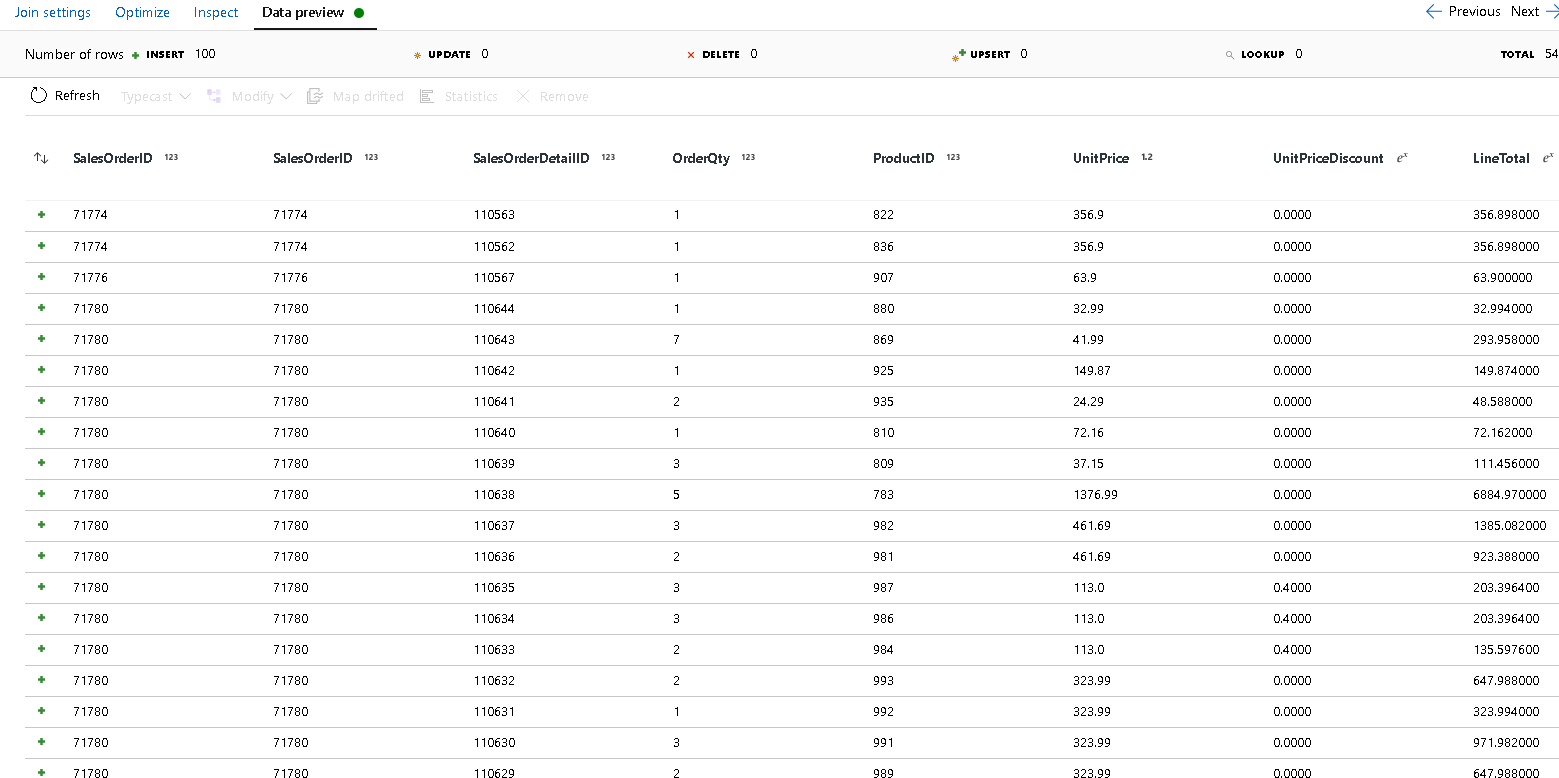
이러한 행을 비정규화하는 배열을 만들려면 먼저 불필요한 열을 제거하고 데이터 값이 Azure Cosmos DB 데이터 형식과 일치하도록 해야 합니다.
다음 Select 변환을 추가하고 필드 매핑을 다음과 같이 설정합니다.
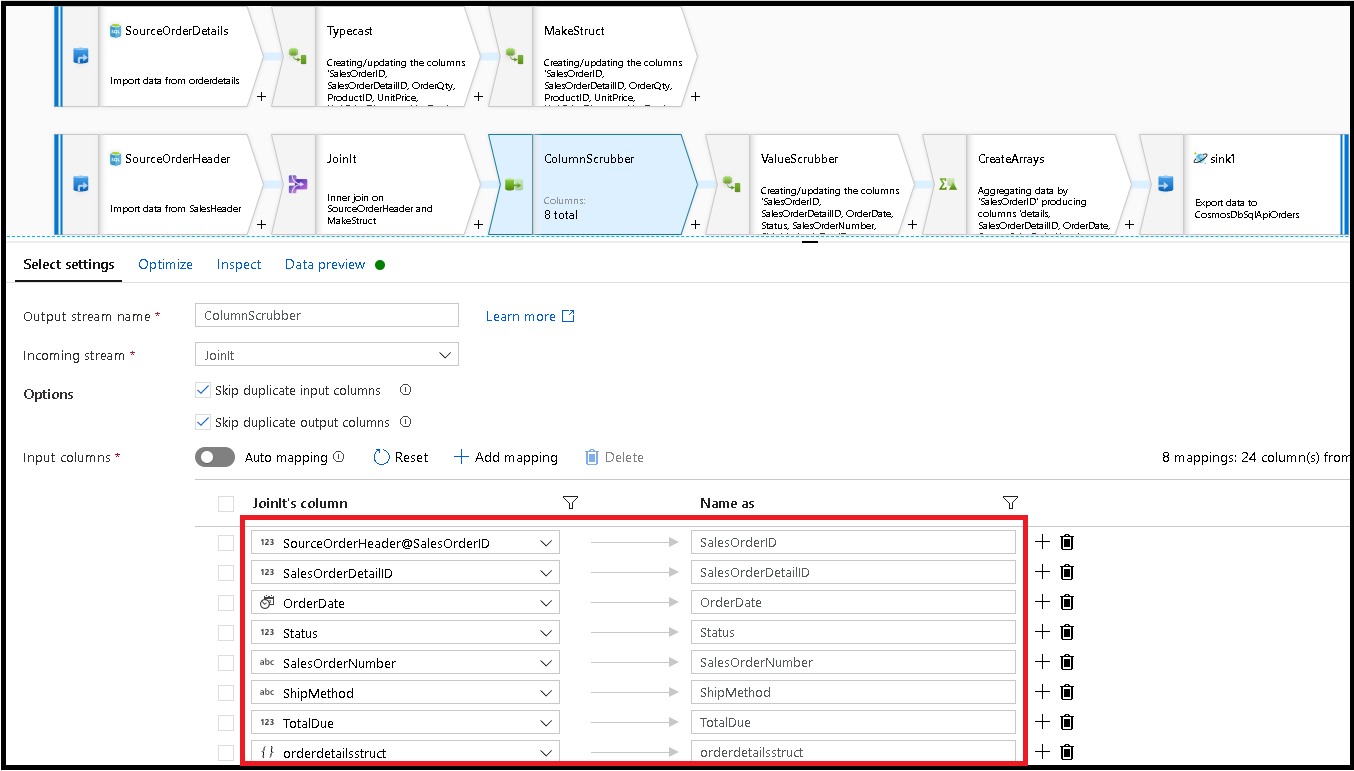
이제 통화 열을 다시 캐스팅하겠습니다. 이번에는
TotalDue입니다. 7단계에서 설명한 것처럼 수식을toDouble(round(TotalDue,2))로 설정합니다.다음은 공통 키
SalesOrderID로 그룹화하여 행을 비정규화하는 위치입니다. 집계 변환을 추가하고 그룹화를SalesOrderID로 설정합니다.집계 수식에서 'details'라는 새 열을 추가하고 이 수식을 사용하여 앞서 만든
orderdetailsstruct:collect(orderdetailsstruct)라는 구조체에서 값을 수집합니다.집계 변환은 집계 또는 그룹화 수식의 일부인 열만 출력합니다. 따라서 sales 헤더의 열도 포함해야 합니다. 이렇게 하려면 동일한 집계 변환에 열 패턴을 추가합니다. 이 패턴에는 아래 나열된 열(OrderQty, UnitPrice, SalesOrderID)을 제외한 출력의 다른 모든 열이 포함됩니다.
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
동일한 열 이름을 유지하고
first()함수를 집계로 사용하도록 다른 속성에 '다음' 구문($$)을 사용합니다. 이는 ADF에 일치하는 첫 번째 값을 찾도록 지시합니다.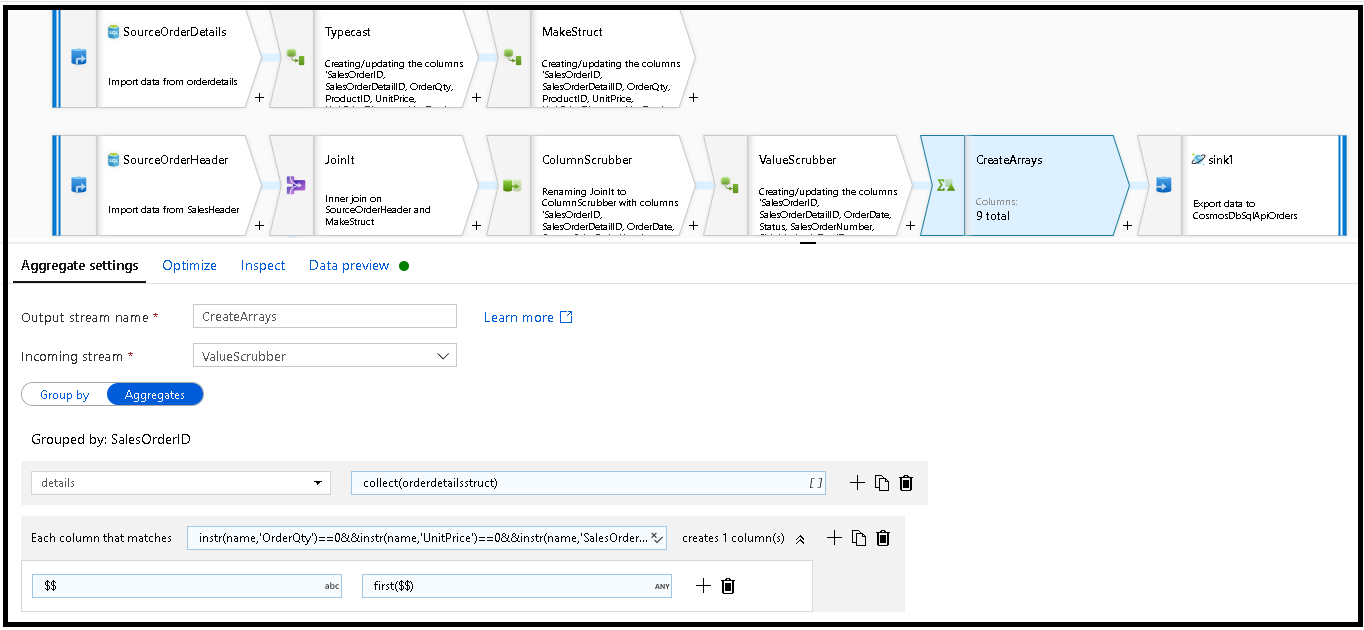
싱크 변환을 추가하여 마이그레이션 흐름을 완료할 준비가 되었습니다. 데이터 세트 옆에 있는 "새로 만들기"를 선택하고 Azure Cosmos DB 데이터베이스를 가리키는 Azure Cosmos DB 데이터 세트를 추가합니다. 컬렉션의 경우 "orders"라고 하며 즉석에서 만들어지므로 스키마와 문서가 없습니다.
싱크 설정에서 파티션 키를
/SalesOrderID로, 컬렉션 작업을 '다시 만들기'로 설정합니다. 매핑 탭이 다음과 같이 표시되는지 확인합니다.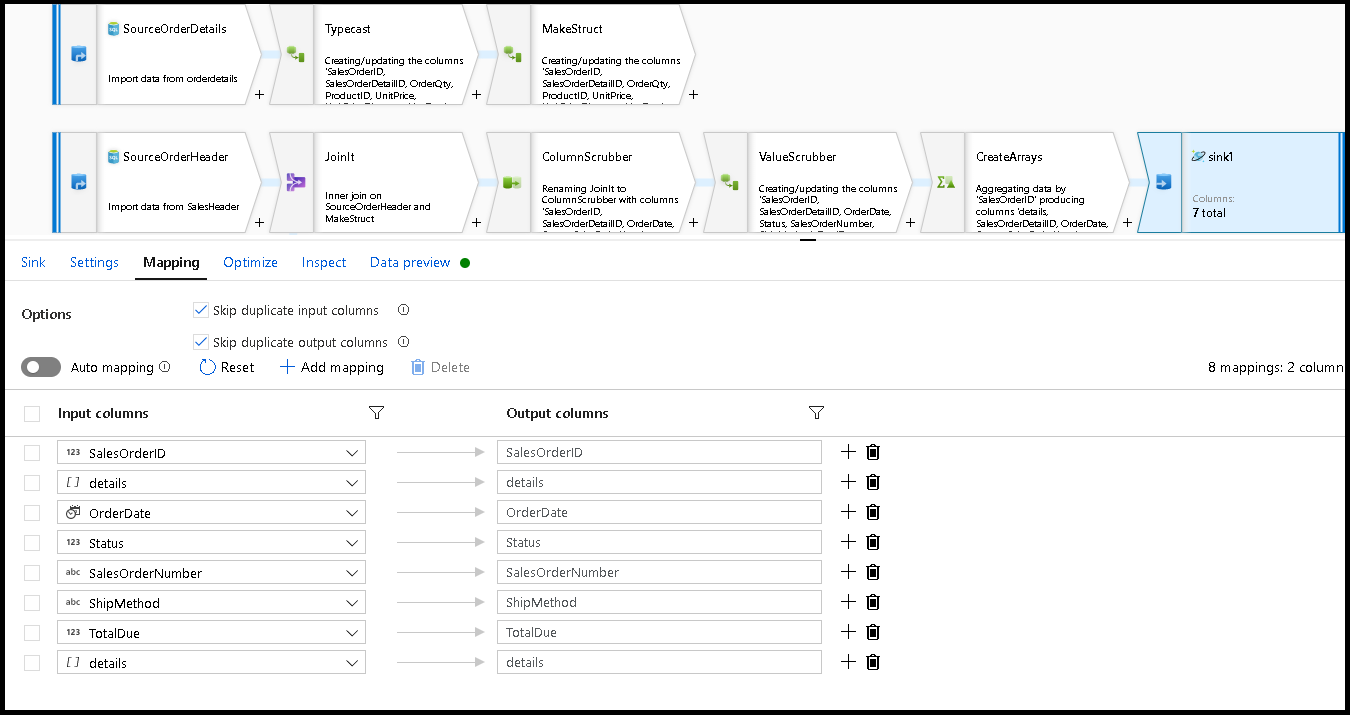
데이터 미리 보기를 선택하여 새 컨테이너에 새 문서로 삽입하도록 설정된 32개의 행이 표시되는지 확인합니다.
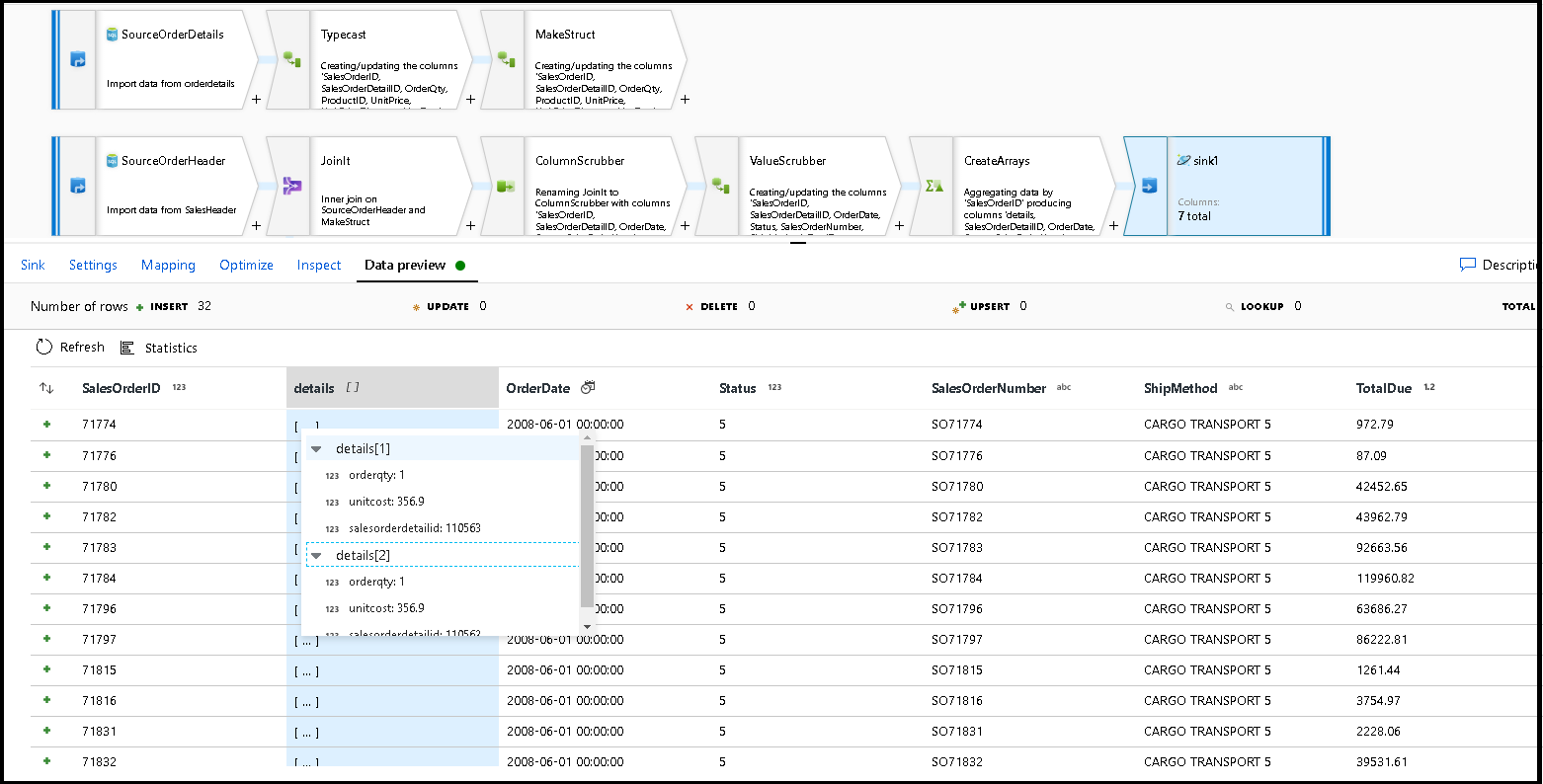
모든 것이 제대로 표시되면 이제 새 파이프라인을 만들고 이 데이터 흐름 작업을 해당 파이프라인에 추가하고 실행할 준비가 되었습니다. 디버그 또는 트리거된 실행에서 실행할 수 있습니다. 몇 분 후에 Azure Cosmos DB 데이터베이스에 'orders'라는 비정규화된 새 컨테이너가 생깁니다.
관련 콘텐츠
- 매핑 데이터 흐름 변환을 사용하여 나머지 데이터 흐름 논리를 빌드합니다.
- 이 자습서에 대해 완료된 파이프라인 템플릿을 다운로드하고 템플릿을 팩터리에 가져옵니다.