워크플로에 대한 서버리스 컴퓨팅을 사용하여 Azure Databricks 작업 실행
Important
워크플로에 대한 서버리스 컴퓨팅은 송신 트래픽 제어를 지원하지 않으므로 작업에는 인터넷에 대한 모든 권한이 있습니다.
워크플로에 대한 서버리스 컴퓨팅을 사용하면 인프라를 구성하고 배포하지 않고도 Azure Databricks 작업을 실행할 수 있습니다. 서버리스 컴퓨팅을 사용하면 데이터 처리 및 분석 파이프라인을 구현하는 데 집중하고, Azure Databricks가 워크로드에 대한 컴퓨팅 최적화 및 크기 조정을 포함하여 컴퓨팅 리소스를 효율적으로 관리합니다. 자동 크기 조정 및 Photon은 작업을 실행하는 컴퓨팅 리소스에 대해 자동으로 사용하도록 설정됩니다.
워크플로 자동 최적화를 위한 서버리스 컴퓨팅은 워크로드에 따라 인스턴스 유형, 메모리 및 처리 엔진과 같은 적절한 리소스를 선택하여 컴퓨팅을 자동으로 최적화합니다. 자동 최적화는 실패한 작업도 자동으로 다시 시도합니다.
Databricks는 Azure Databricks 작업의 안정성을 보장하면서 플랫폼에 대한 향상된 기능 및 업그레이드를 지원하도록 Databricks 런타임 버전을 자동으로 업그레이드합니다. 워크플로에 대해 서버리스 컴퓨팅에서 사용하는 현재 Databricks 런타임 버전을 보려면 서버리스 컴퓨팅 릴리스 정보를 참조하세요.
클러스터 만들기 권한이 필요하지 않으므로 모든 작업 영역 사용자는 서버리스 컴퓨팅을 사용하여 워크플로를 실행할 수 있습니다.
이 문서에서는 Azure Databricks 작업 UI를 사용하여 서버리스 컴퓨팅을 사용하는 작업을 만들고 실행하는 방법을 설명합니다. 작업 API, Databricks 자산 번들 및 Python용 Databricks SDK를 사용하여 서버리스 컴퓨팅을 사용하는 작업 만들기 및 실행을 자동화할 수도 있습니다.
- 작업 API를 사용하여 작업을 만들고 서버리스 컴퓨팅을 이용하는 작업을 실행하는 방법은 REST API 참조의 작업을 참조하세요.
- Databricks 자산 번들을 사용하여 서버리스 컴퓨팅을 사용하는 작업을 만들고 실행하는 방법에 대한 자세한 내용은 Databricks 자산 번들을 사용하여 Azure Databricks에서 작업 개발을 참조하세요.
- Python용 Databricks SDK를 사용하여 서버리스 컴퓨팅을 사용하는 작업을 만들고 실행하는 방법에 대한 자세한 내용은 Python용 Databricks SDK를 참조하세요.
요구 사항
Azure Databricks 작업 영역에 Unity Catalog가 활성화되어 있어야 합니다.
워크플로에 대한 서버리스 컴퓨팅은 공유 액세스 모드를 사용하므로 워크로드에서 이 액세스 모드를 지원해야 합니다.
Azure Databricks 작업 영역은 지원되는 지역에 속해야 합니다. 신기능 사용 가능여부를 참조하세요.
Azure Databricks 계정에는 서버리스 컴퓨팅을 사용하도록 설정해야 합니다. 서버리스 컴퓨팅 사용을 참조하세요.
서버리스 컴퓨팅을 사용하여 작업 만들기
참고 항목
워크플로에 대한 서버리스 컴퓨팅은 워크로드를 실행하기 위해 충분한 리소스가 프로비전되도록 하기 때문에 많은 양의 메모리가 필요하거나 많은 작업을 포함하는 Azure Databricks 작업을 실행할 때 시작 시간이 증가할 수 있습니다.
서버리스 컴퓨팅은 Notebook, Python 스크립트, dbt 및 Python 휠 작업 종류에서 지원됩니다. 기본적으로 서버리스 컴퓨팅은 새 작업을 만들고 지원되는 작업 종류 중 하나를 추가할 때 컴퓨팅 유형으로 선택됩니다.
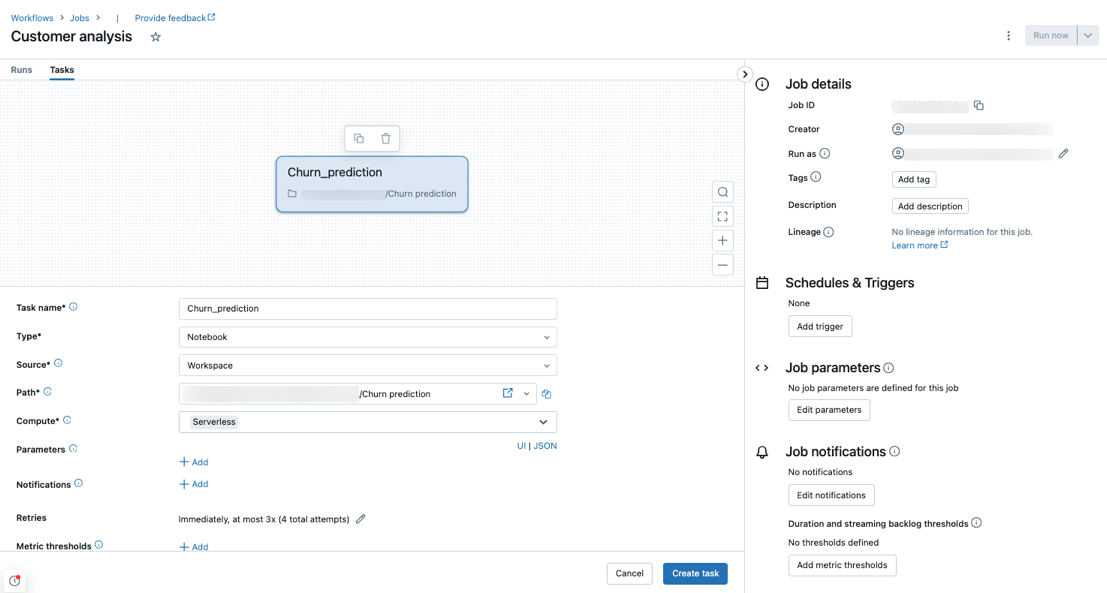
Databricks는 모든 작업 작업에 서버리스 컴퓨팅을 사용하는 것이 좋습니다. 워크플로에 대한 서버리스 컴퓨팅에서 작업 종류를 지원하지 않는 경우 필요할 수 있는 작업의 태스크에 대해 다른 컴퓨팅 유형을 지정할 수도 있습니다.
서버리스 컴퓨팅을 사용하도록 기존 작업 구성
작업을 편집할 때 지원되는 작업 종류에 대해 서버리스 컴퓨팅을 사용하도록 기존 작업을 전환할 수 있습니다. 서버리스 컴퓨팅으로 전환하려면 다음 중 하나를 수행합니다.
- 작업 세부 정보 측면 패널에서 컴퓨팅아래 전환을 클릭하고 새로 만들기를 클릭하고 설정을 입력하거나 업데이트한 다음 업데이트를 클릭합니다.
- 컴퓨팅
 드롭다운 메뉴를 클릭하고 서버리스를 선택합니다.
드롭다운 메뉴를 클릭하고 서버리스를 선택합니다.

서버리스 컴퓨팅을 사용하여 Notebook 예약
작업 UI를 사용하여 서버리스 컴퓨팅을 사용하여 작업을 만들고 예약하는 것 외에도 Databricks Notebook에서 직접 서버리스 컴퓨팅을 사용하는 작업을 만들고 실행할 수 있습니다. 예약된 Notebook 작업 만들기 및 관리를 참조하세요.
Spark 구성 매개 변수 설정
서버리스 컴퓨팅에서 Spark의 구성을 자동화하기 위해 Databricks는 특정 Spark 구성 매개 변수만 설정할 수 있습니다. 허용되는 매개 변수 목록은 지원되는 Spark 구성 매개 변수를 참조하세요.
세션 수준에서만 Spark 구성 매개 변수를 설정할 수 있습니다. 이렇게 하려면 Notebook에서 설정하고 매개 변수를 사용하는 동일한 작업에 포함된 작업에 Notebook을 추가합니다. Notebook에서 Apache Spark 구성 속성을 가져오고 설정하는 방법을 참조하세요.
환경 및 종속성 구성
서버리스 컴퓨팅을 사용하여 libaries 및 종속성을 설치하는 방법을 알아보려면 Notebook 종속성 설치를 참조하세요.
재시도를 허용하지 않도록 서버리스 컴퓨팅 자동 최적화 구성
워크플로 자동 최적화를 위한 서버리스 컴퓨팅은 작업을 실행하는 데 사용되는 컴퓨팅을 자동으로 최적화하고 실패한 작업을 다시 시도합니다. 자동 최적화는 기본적으로 사용하도록 설정되며, Databricks는 중요한 워크로드가 한 번 이상 성공적으로 실행되도록 사용하도록 설정하는 것이 좋습니다. 그러나 idempotent가 아닌 작업과 같이 한 번에 실행해야 하는 워크로드가 있는 경우 작업을 추가하거나 편집할 때 자동 최적화를 해제할 수 있습니다.
- 다시 시도 옆의 추가(또는
 재시도 정책이 이미 있는 경우)를 클릭합니다.
재시도 정책이 이미 있는 경우)를 클릭합니다. - 다시 시도 정책 대화 상자에서 서버리스 자동 최적화 사용(추가 재시도 포함)을 선택 취소합니다.
- 확인을 클릭합니다.
- 작업을 추가하는 경우 작업 만들기를 클릭합니다. 작업을 편집하는 경우 작업 저장을 클릭합니다.
워크플로에 서버리스 컴퓨팅을 사용하는 작업 비용 모니터링
청구 가능한 사용량 시스템 테이블을 쿼리하여 워크플로에 서버리스 컴퓨팅을 사용하는 작업의 비용을 모니터링할 수 있습니다. 이 테이블은 서버리스 비용에 대한 사용자 및 워크로드 특성을 포함하도록 업데이트되었습니다. 청구 가능한 사용량 시스템 테이블 참조를 참조하세요.
Spark 쿼리에 대한 세부 정보 보기
워크플로에 대한 서버리스 컴퓨팅에는 메트릭 및 쿼리 계획과 같은 Spark 문에 대한 자세한 런타임 정보를 보기 위한 새로운 인터페이스가 있습니다. 작업에 포함된 Spark 문에 대한 쿼리 인사이트를 보려면 서버리스 컴퓨팅에서 실행됩니다.
- 사이드바에서
 워크플로를 클릭합니다.
워크플로를 클릭합니다. - 이름 열에서 인사이트를 보려는 작업 이름을 클릭합니다.
- 인사이트를 보려는 특정 실행을 클릭합니다.
- 작업 실행 쪽 패널의 컴퓨팅 섹션에서 쿼리 기록을 클릭합니다.
- 쿼리 기록으로 리디렉션되며, 작업 실행 ID에 따라 미리 필터링됩니다.
쿼리 기록 사용에 대한 자세한 내용은 쿼리 기록을 참조하세요.
제한 사항
워크플로 제한에 대한 서버리스 컴퓨팅 목록은 서버리스 컴퓨팅 릴리스 정보에서 서버리스 컴퓨팅 제한을 참조하세요.