작업 영역 개체에 대한 식별자 가져오기
이 문서에서는 Azure Databricks에서 작업 영역, 클러스터, 디렉터리, 모델, Notebook 및 작업 식별자와 URL을 가져오는 방법을 설명합니다.
작업 영역 인스턴스 이름, URL 및 ID
작업 영역별 URL이라고도 하는 고유한 인스턴스 이름이 각 Azure Databricks 배포에 할당됩니다. Azure Databricks 배포에 로그인하고 API를 요청하는 데 사용되는 정규화된 도메인 이름입니다.
Azure Databricks 작업 영역은 Azure Databricks 플랫폼이 실행되고 Spark 클러스터를 만들고 워크로드를 예약할 수 있는 곳입니다. 작업 영역에는 고유한 숫자 작업 영역 ID가 있습니다.
작업 영역별 URL
고유한 작업 영역별 URL의 형식은 adb-<workspace-id>.<random-number>.azuredatabricks.net입니다. 작업 영역 ID는 adb- 바로 뒤와 "마침표"(.) 앞에 나타납니다. 작업 영역별 URL https://adb-5555555555555555.19.azuredatabricks.net/의 경우:
- 인스턴스 이름은
adb-5555555555555555.19.azuredatabricks.net입니다. - 작업 영역 ID는
5555555555555555입니다.
작업 영역별 URL 결정
작업 영역에 대한 작업 영역별 URL을 결정할 수 있습니다.
로그인했을 때 브라우저에서:

Azure Portal에서 리소스를 선택하고 URL 필드의 값을 기록해 둡니다.
Azure API 사용. Azure API를 사용하여 작업 영역별 URL 가져오기를 참조하세요.
레거시 지역 URL
Important
레거시 지역 URL을 사용하지 마세요. 새 작업 영역에서는 작동하지 않을 수 있으며 작업 영역당 URL보다 안정성이 낮고 성능이 낮습니다.
레거시 지역 URL은 Azure Databricks 작업 영역이 배포된 지역과 azuredatabricks.net 도메인(예: https://westus.azuredatabricks.net/)으로 구성됩니다.
https://westus.azuredatabricks.net/과 같은 레거시 지역 URL에 로그인하는 경우 인스턴스 이름은westus.azuredatabricks.net입니다.- 작업 영역 ID는 레거시 지역 URL을 사용하여 로그인한 후에만 URL에 나타납니다.
o=뒤에 나타납니다. URLhttps://<databricks-instance>/?o=6280049833385130에서 작업 영역 ID는6280049833385130입니다.
클러스터 URL 및 ID
Azure Databricks 클러스터는 프로덕션 ETL 파이프라인 실행, 스트리밍 분석, 임시 분석 및 기계 학습과 같은 다양한 사용 사례를 위한 통합 플랫폼을 제공합니다. 각 클러스터에는 클러스터 ID라는 고유 ID가 있습니다. 이는 다목적 및 작업 클러스터 모두에 적용됩니다. REST API를 사용하여 클러스터의 세부 정보를 가져오려면 클러스터 ID가 필수적입니다.
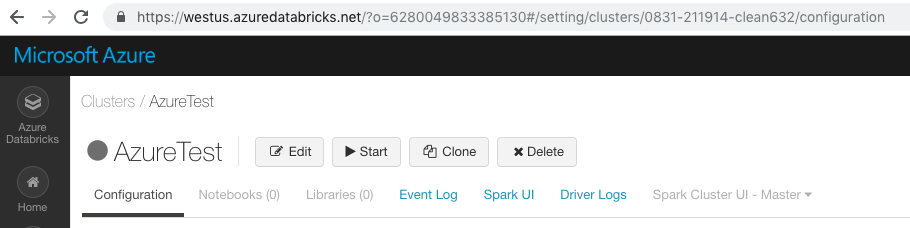
클러스터 ID를 가져오려면 사이드바에서 클러스터 탭을 클릭한 다음 클러스터 이름을 선택합니다. 클러스터 ID는 이 페이지의 URL에서 /clusters/ 구성 요소 뒤의 숫자입니다.
https://<databricks-instance>/#/setting/clusters/<cluster-id>
다음 스크린샷에서 클러스터 ID는 0831-211914-clean632입니다.
Notebook URL 및 ID
Notebook은 실행 가능한 코드, 시각화 및 내러티브 문자를 포함하는 문서에 대한 웹 기반 인터페이스입니다. Notebooks는 Azure Databricks와 상호 작용하기 위한 하나의 인터페이스입니다. 각 Notebook에는 고유한 ID가 있습니다. Notebook URL에는 Notebook ID가 있으므로 Notebook URL은 Notebook에 고유합니다. Notebook을 보고 편집할 수 있는 권한이 있는 Azure Databricks 플랫폼의 모든 사용자와 공유할 수 있습니다. 또한 각 Notebook 명령(셀)의 URL은 서로 다릅니다.
Notebook URL 또는 ID를 찾으려면 Notebook을 엽니다. 셀 URL을 찾으려면 명령의 내용을 클릭합니다.
예제 Notebook URL:
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342`예제 Notebook ID:
1940481404050342예제 명령(셀) URL:
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342/command/2432220274659491
폴더 ID
폴더는 Azure Databricks 작업 영역에서 사용할 수 있는 파일을 저장하는 데 사용되는 디렉터리입니다. 이러한 파일은 Notebook, 라이브러리 또는 하위 폴더일 수 있습니다. 각 폴더 및 각 개별 하위 폴더와 연결된 특정 ID가 있습니다. 권한 API는 이 ID를 directory_id로 참조하며 폴더에 대한 사용 권한을 설정하고 업데이트하는 데 사용됩니다.
directory_id를 검색하려면 작업 영역 API를 사용합니다.
curl -n -X GET -H 'Content-Type: application/json' -d '{"path": "/Users/me@example.com/MyFolder"}' \
https://<databricks-instance>/api/2.0/workspace/get-status
API 호출 응답의 예입니다.
{
"object_type": "DIRECTORY",
"path": "/Users/me@example.com/MyFolder",
"object_id": 123456789012345
}
Model ID
모델은 단계 전환 및 버전 관리를 통해 프로덕션에서 MLflow 모델을 관리할 수 있는 MLflow 등록된 모델을 나타냅니다. Permissions API를 통해 프로그래밍 방식으로 모델에 대한 권한을 변경하려면 등록된 모델 ID가 필요합니다.
등록된 모델의 ID를 가져오려면 작업 영역 API 엔드포인트 mlflow/databricks/registered-models/get을(를) 사용할 수 있습니다. 예를 들어, 다음 코드는 등록된 모델 개체를 ID를 포함하여 속성과 함께 반환합니다.
curl -n -X GET -H 'Content-Type: application/json' -d '{"name": "model_name"}' \
https://<databricks-instance>/api/2.0/mlflow/databricks/registered-models/get
반환된 값의 형식은 다음과 같습니다.
{
"registered_model_databricks": {
"name":"model_name",
"id":"ceb0477eba94418e973f170e626f4471"
}
}
작업 URL 및 ID
작업은 Notebook이나 JAR을 즉시 또는 예정대로 실행하는 방법입니다.
작업 URL을 가져오려면 사이드바에서 ![]() 워크플로를 클릭하고 작업 이름을 클릭합니다. 작업 ID는 URL에서 텍스트
워크플로를 클릭하고 작업 이름을 클릭합니다. 작업 ID는 URL에서 텍스트 #job/ 뒤에 있습니다. 작업 URL은 실패한 작업 실행의 근본 원인을 해결하는 데 필요합니다.
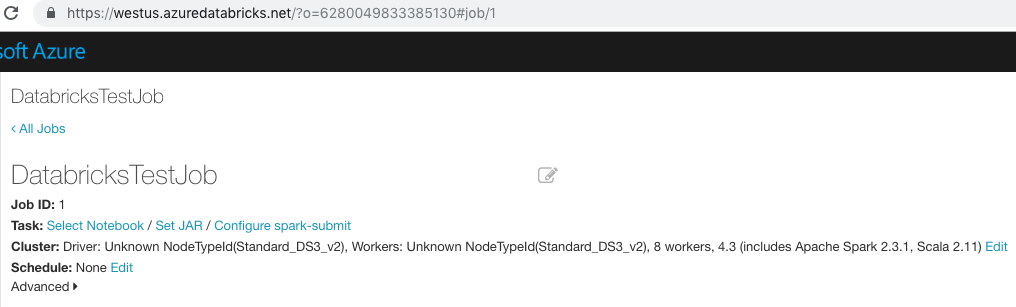
다음 스크린샷에서 작업 URL은 다음과 같습니다.
https://westus.azuredatabricks.net/?o=6280049833385130#job/1
이 예에서 작업 ID는 1입니다.