예측 모델의 유추 및 평가
이 문서에서는 예측 작업의 모델 유추 및 평가와 관련된 개념을 소개합니다. AutoML에서 예측 모델을 학습하는 지침과 예제는 SDK 및 CLI를 사용하여 시계열 예측 모델을 학습하도록 AutoML 설정을 참조하세요.
AutoML을 사용하여 최상의 모델을 학습하고 선택했다면 다음 단계는 예측을 생성하는 것입니다. 그런 다음 가능하다면 학습 데이터에서 유지된 테스트 집합에 대한 정확도를 평가합니다. 자동화된 Machine Learning에서 예측 모델 평가를 설정하고 실행하는 방법을 보려면 학습, 유추 및 평가 조정을 참조하세요.
유추 시나리오
기계 학습에서 유추는 학습에 사용되지 않는 새로운 데이터에 대한 모델 예측을 생성하는 프로세스입니다. 데이터의 시간 의존성으로 인해 예측(forecast)에서 예측(prediction)을 생성하는 방법에는 여러 가지가 있습니다. 가장 간단한 시나리오는 유추 기간이 학습 기간 바로 뒤에 나타나고 예측(forecast) 범위에 대한 예측(prediction)을 생성하는 경우입니다. 다음 다이어그램은 이 시나리오를 보여 줍니다.
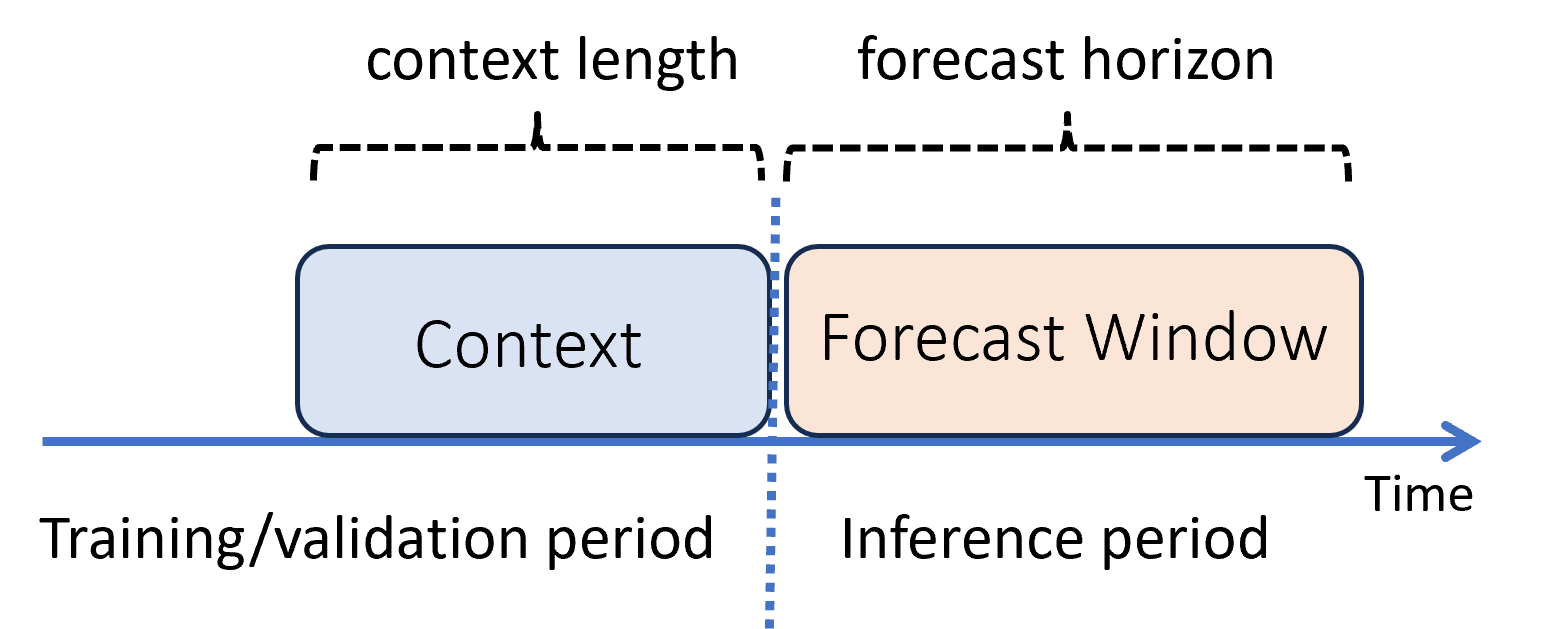
다이어그램은 두 가지 중요한 유추 매개 변수를 보여 줍니다.
- 컨텍스트 길이는 모델이 예측을 수행하는 데 필요한 기록의 양입니다.
- 예측 범위는 예측자가 예측하도록 학습받은 시간을 나타냅니다.
예측 모델은 일반적으로 일부 과거 정보, 즉 컨텍스트를 사용하여 예측 범위까지 미리 예측합니다. 컨텍스트가 학습 데이터의 일부인 경우 AutoML은 예측에 필요한 내용을 저장합니다. 따라서 이를 명시적으로 제공할 필요는 없습니다.
더 복잡한 두 가지 다른 유추 시나리오가 있습니다.
- 예측 범위보다 더 먼 향후에 대한 예측을 생성합니다.
- 학습 기간과 유추 기간 사이에 간격이 있을 때 예측을 가져옵니다.
다음 하위 섹션에서는 이러한 사례를 검토합니다.
예측 범위를 넘어서는 예측: 재귀적 예측
범위를 지나 예측이 필요한 경우 AutoML은 유추 기간 동안 모델을 되풀이적으로 적용합니다. 후속 예측 기간에 대한 예측을 생성하기 위해 모델의 예측이 입력으로 피드백됩니다. 다음 다이어그램은 간단한 예를 보여 줍니다.
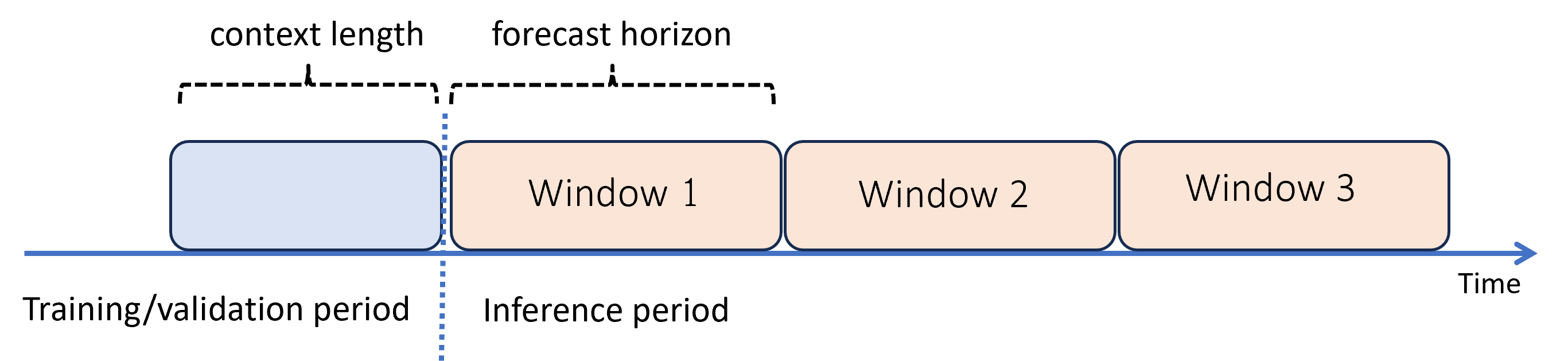
여기서 기계 학습은 범위 길이의 3배에 달하는 기간에 대한 예측을 생성하고 한 기간의 예측을 다음 기간의 컨텍스트로 사용합니다.
Warning
재귀적 예측은 모델링 오류를 악화합니다. 예측은 원래 예측 수평선에서 멀어질수록 정확도가 떨어집니다. 더 긴 범위로 재학습하면 더 정확한 모델을 찾을 수 있습니다.
학습 기간과 유추 기간 사이에 간격이 있는 예측
모델을 학습한 다음, 학습 중에는 아직 사용할 수 없었던 새로운 관찰을 통해 예측하는 데 해당 모델을 사용한다고 가정해 보겠습니다. 이 경우 학습 기간과 유추 기간 사이에 시간 차이가 있습니다.
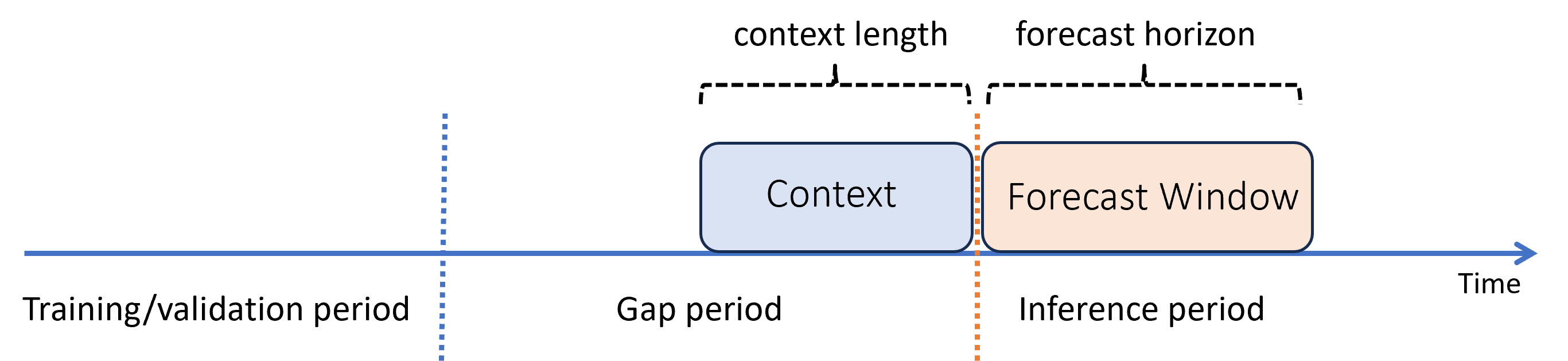
AutoML은 이 유추 시나리오를 지원하지만 다이어그램에 표시된 것처럼 간격 기간에 컨텍스트 데이터를 제공해야 합니다. 유추 구성 요소에 전달된 예측 데이터에는 간격의 기능 및 관찰된 대상 값에 대한 값과 유추 기간의 대상에 대한 누락된 값 또는 NaN 값이 필요합니다. 다음 표에서는 이 패턴의 예를 보여 줍니다.
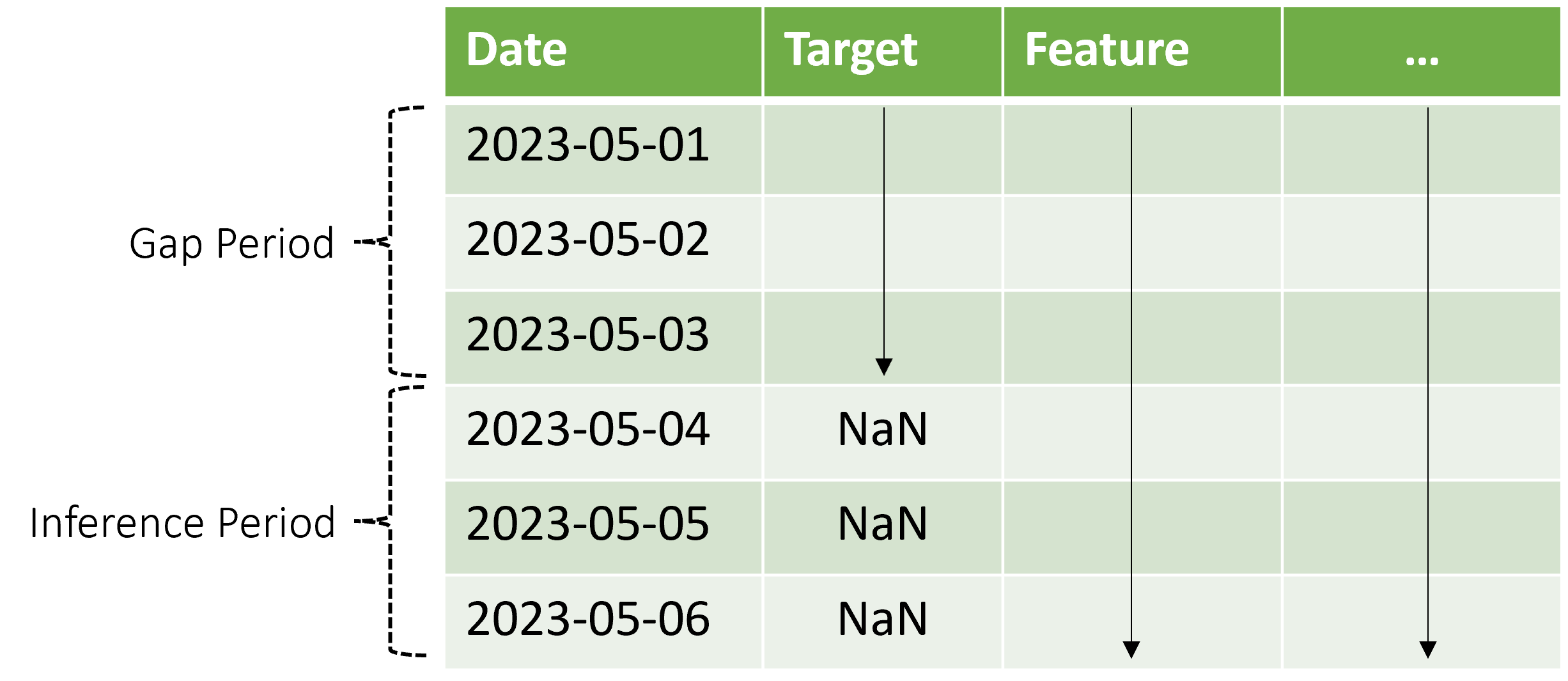
2023-05-01부터 2023-05-03에 알려진 대상 및 기능 값이 제공됩니다. 2023-05-04부터 시작하는 누락된 대상 값은 유추 기간이 해당 날짜에 시작됨을 나타냅니다.
AutoML은 새로운 컨텍스트 데이터를 사용하여 지연 및 기타 전환 기능을 업데이트하고 내부 상태를 유지하는 ARIMA와 같은 모델도 업데이트합니다. 이 작업은 모델 매개 변수를 업데이트하거나 다시 맞추지 않습니다.
모델 평가
평가는 학습 데이터에서 유지된 테스트 집합에 대한 예측을 생성하고 모델 배포 결정을 안내하는 이러한 예측에서 메트릭을 계산하는 프로세스입니다. 따라서 모델 평가에 특히 적합한 유추 모드인 롤링 예측이 있습니다.
예측 모델을 평가하는 모범 사례 절차는 학습된 예측자를 테스트 집합에 대해 시간에 맞춰 롤업하여 여러 예측 창에 대한 오류 메트릭의 평균을 구하는 것입니다. 이 절차는 백테스트라고도 합니다. 이상적으로 평가에 대한 테스트 집합은 모델의 예측 기간에 비해 깁니다. 예측 오류의 예측값은 통계적으로 노이즈가 심할 수 있으므로 신뢰성이 떨어집니다.
다음 다이어그램은 세 가지 예측 기간이 포함된 간단한 예를 보여 줍니다.
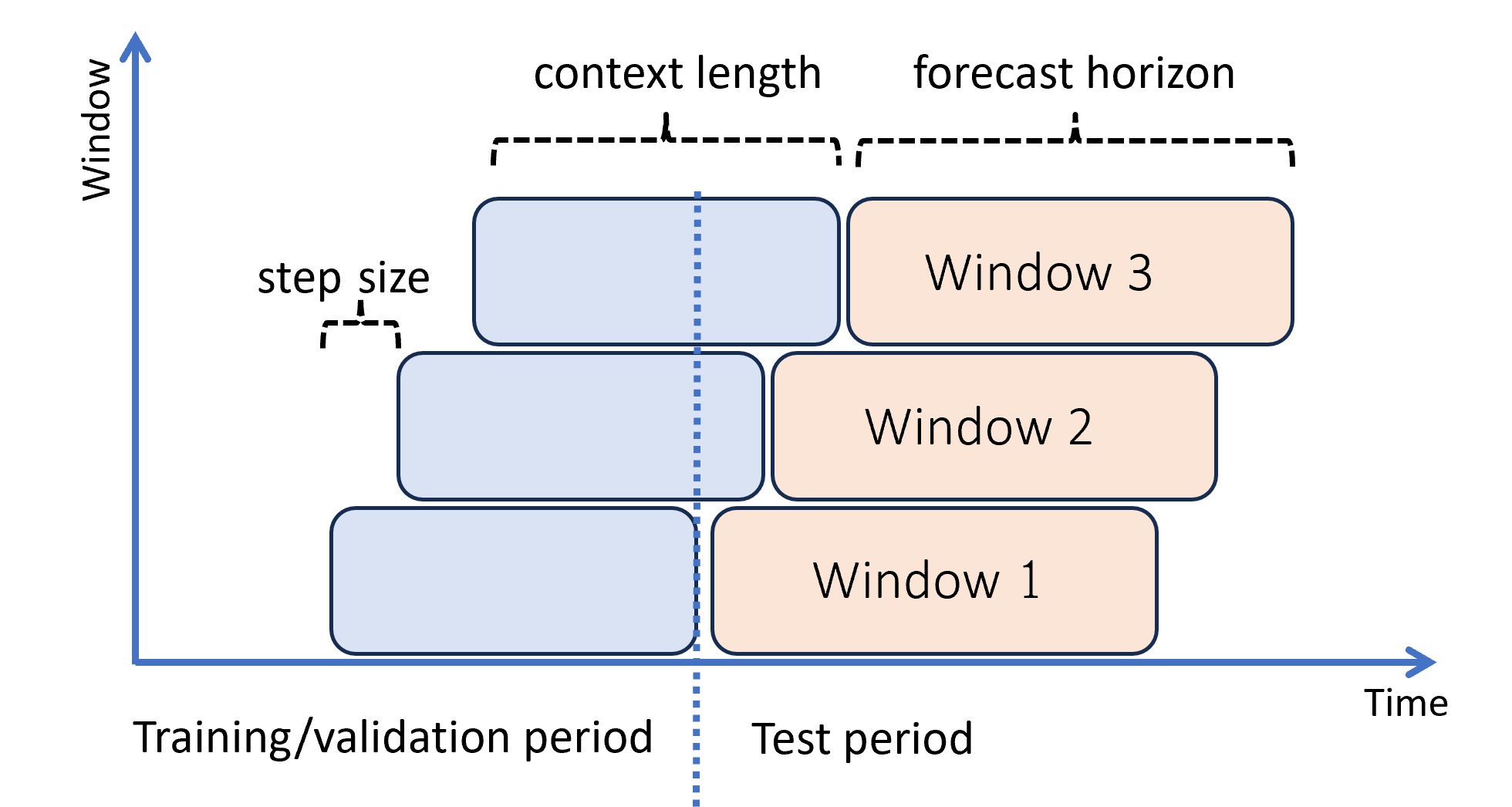
다이어그램은 세 가지 롤링 평가 매개 변수를 보여 줍니다.
- 컨텍스트 길이는 모델이 예측을 수행하는 데 필요한 기록의 양입니다.
- 예측 범위는 예측자가 예측하도록 학습받은 시간을 나타냅니다.
- 단계 크기는 테스트 집합의 각 반복에서 롤링 기간이 시간적으로 얼마나 앞으로 진행되는지를 나타냅니다.
컨텍스트는 예측 기간과 함께 진행됩니다. 테스트 집합의 실제 값은 현재 컨텍스트 기간에 속할 때 예측을 만드는 데 사용됩니다. 특정 예측 기간에 사용된 실제 값의 가장 늦은 날짜를 해당 기간의 원본 시간이라고 합니다. 다음 표는 범위가 3일이고 단계 크기가 1일인 3개 창 롤링 예측의 출력 예를 보여 줍니다.
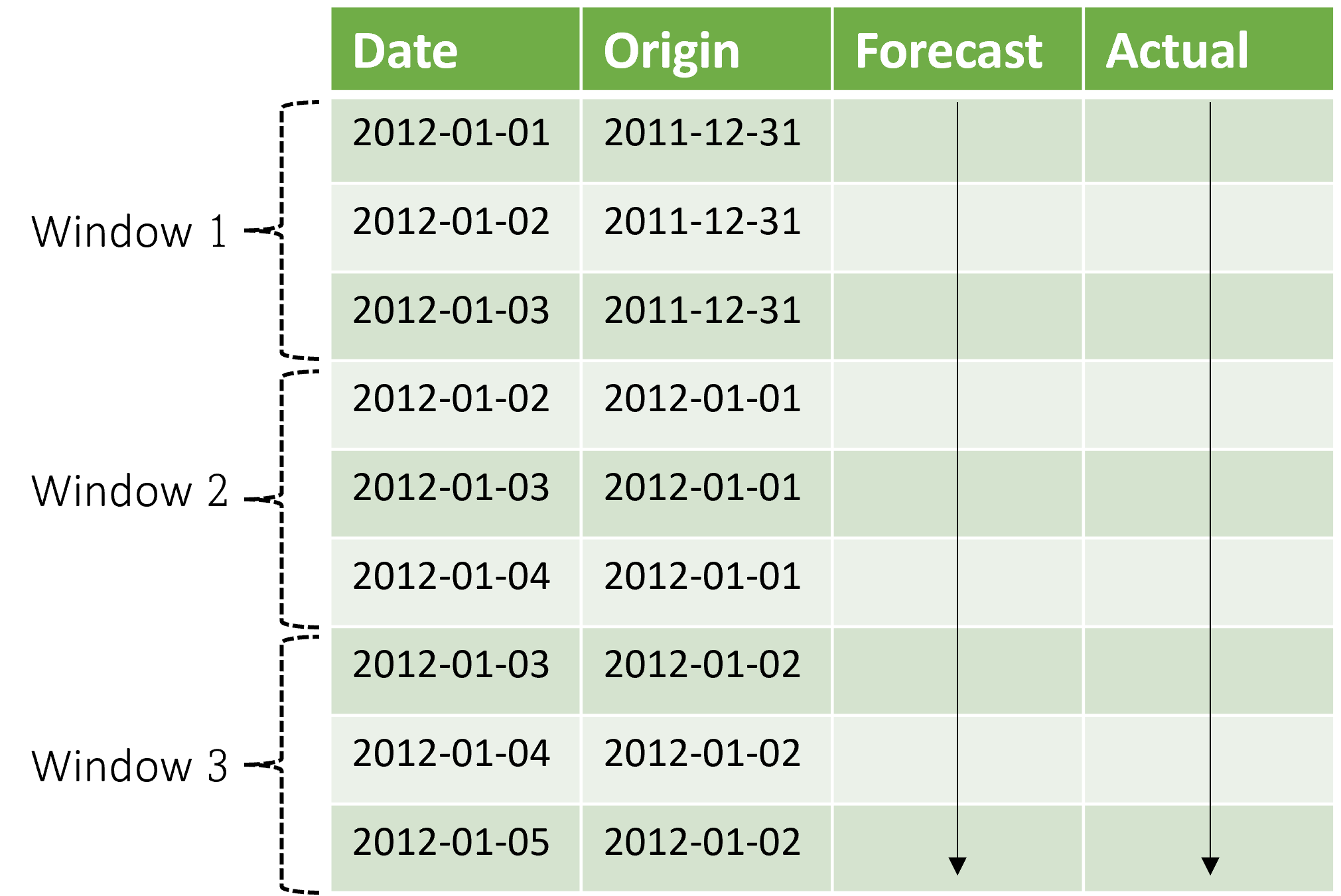
이와 같은 테이블을 사용하면 예측과 실제를 시각화하고 원하는 평가 메트릭을 계산할 수 있습니다. AutoML 파이프라인은 유추 구성 요소를 사용하여 테스트 집합에 대한 롤링 예측을 생성할 수 있습니다.
참고 항목
테스트 기간이 예측 범위와 동일한 길이인 경우 롤링 예측은 해당 기간까지 단일 예측 창을 제공합니다.
평가 메트릭
평가 요약을 선택할지, 아니면 메트릭을 선택할지는 보통 특정 비즈니스 시나리오에 따라 결정됩니다. 몇 가지 일반적인 선택 사항은 다음과 같습니다.
- 모델이 캡처하는 데이터의 특정 역학을 확인하기 위한, 관찰된 대상 값과 예측 값의 플롯
- 실제 값과 예측 값 사이의 평균 절대 백분율 오차(MAPE)
- 실제 값과 예측 값 사이의 정규화를 통해 구할 수 있는 제곱 평균 오차(RMSE)
- 실제 값과 예측 값 사이의 정규화를 통해 구할 수 있는 평균 절대 오차(MAE)
비즈니스 시나리오에 따라 다른 가능성도 많이 있습니다. 유추 결과 또는 롤링 예측에서 평가 메트릭을 계산하려면 자체 후처리 유틸리티를 만들어야 할 수도 있습니다. 메트릭에 대한 자세한 내용은 회귀/예측 메트릭을 참조하세요.
관련 콘텐츠
- 시계열 예측 모델 학습을 위해 AutoML을 설정하는 방법에 대해 자세히 알아봅니다.
- AutoML이 기계 학습을 사용하여 예측 모델을 빌드하는 방법에 대해 알아봅니다.
- AutoML 예측에 대한 질문과 대답의 답변을 참조하세요.