실시간 유추를 위한 온라인 엔드포인트 배포
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
이 문서에서는 Azure Machine Learning에서 실시간 유추를 위한 온라인 엔드포인트에 대해 설명합니다. 유추는 새로운 입력 데이터를 기계 학습 모델에 적용하여 출력을 생성하는 프로세스입니다. Azure Machine Learning을 사용하면 온라인 엔드포인트에 배포된 모델을 사용하여 데이터에 대한 실시간 유추를 수행할 수 있습니다. 이러한 출력을 일반적으로 예측이라고 부르지만 유추를 사용하여 분류 및 클러스터링과 같은 다른 기계 학습 작업에 대한 출력을 생성할 수 있습니다.
온라인 엔드포인트
온라인 엔드포인트는 HTTP 프로토콜에 따라 예측을 반환할 수 있는 웹 서버에 모델을 배포합니다. 온라인 엔드포인트는 대기 시간이 낮은 동기식 요청에서 실시간 유추를 위한 모델을 운용할 수 있으며, 최적의 사용 시기는 다음과 같습니다.
- 짧은 대기 시간 요구 사항이 있습니다.
- 모델은 비교적 짧은 시간 내에 요청에 답변할 수 있습니다.
- 모델의 입력이 요청의 HTTP 페이로드에 맞습니다.
- 요청 수를 스케일 업해야 합니다.
엔드포인트를 정의하려면 다음을 지정해야 합니다.
- 엔드포인트 이름. 이 이름은 Azure 지역에서 고유해야 합니다. 그 밖의 명명 요구 사항은 Azure Machine Learning 온라인 엔드포인트 및 일괄 처리 엔드포인트를 참조하세요.
- 인증 모드. 엔드포인트에 대해 키 기반 인증 모드, Azure Machine Learning 토큰 기반 인증 모드, Microsoft Entra 토큰 기반 인증 중에서 선택할 수 있습니다. 인증에 대한 자세한 내용은 온라인 엔드포인트에 대한 클라이언트 인증을 참조하세요.
관리형 온라인 엔드포인트
관리형 온라인 엔드포인트는 편리한 턴키 방식으로 기계 학습 모델을 배포하며, Azure Machine Learning 온라인 엔드포인트를 사용하는 데 권장되는 방법입니다. 관리형 온라인 엔드포인트는 확장성 있는 완전 관리형 방식으로 Azure의 강력한 CPU 및 GPU 머신에서 작동합니다.
기본 인프라를 설정하고 관리하는 오버헤드로부터 벗어나려면 이러한 엔드포인트로 모델의 제공, 크기 조정, 보안 및 모니터링도 처리합니다. 관리형 온라인 엔드포인트를 정의하는 방법을 알아보려면 엔드포인트 정의를 참조하세요.
관리형 온라인 엔드포인트와 Azure Container Instances 또는 AKS(Azure Kubernetes Service) v1 비교
관리형 온라인 엔드포인트는 Azure Machine Learning에서 온라인 엔드포인트를 사용하는 권장되는 방법입니다. 다음 표에서는 Azure Container Instances 및 AKS(Azure Kubernetes Service) v1과 비교하여 관리형 온라인 엔드포인트의 주요 특성을 중점적으로 설명합니다.
| 특성 | 관리형 온라인 엔드포인트(v2) | Container Instances 또는 AKS(v1) |
|---|---|---|
| 네트워크 보안/격리 | 빠른 토글로 쉬운 인바운드/아웃바운드 제어 | 가상 네트워크가 지원되지 않거나 복잡한 수동 구성이 필요합니다. |
| 관리 서비스 | • 완전 관리형 컴퓨팅 프로비전/크기 조정 • 데이터 반출 방지를 위한 네트워크 구성 • 호스트 OS 업그레이드, 현재 위치 업데이트의 제어된 롤아웃 |
• 크기 조정은 제한됨 • 사용자가 네트워크 구성 또는 업그레이드를 관리해야 함 |
| 엔드포인트/배포 개념 | 엔드포인트와 배포 간을 구분하면 모델의 안전한 롤아웃과 같은 복잡한 시나리오를 사용할 수 있습니다. | 엔드포인트 개념 없음 |
| 진단 및 모니터링 | • Docker 및 Visual Studio Code를 사용하여 로컬 엔드포인트 디버깅 가능 • 차트/쿼리를 사용하여 배포 간을 비교하는 고급 메트릭 및 로그 분석 • 배포 수준까지 비용 분석 |
쉬운 로컬 디버깅 없음 |
| 확장성 | 탄력적 및 자동 크기 조정(기본 클러스터 크기에 바인딩되지 않음) | • Container Instances를 확장할 수 없음 • AKS v1은 클러스터 내 크기 조정만 지원하며 확장성 구성이 필요함 |
| 엔터프라이즈 준비 | 프라이빗 링크, 고객 관리형 키, Microsoft Entra ID, 할당량 관리, 청구 통합, SLA(서비스 수준 약정) | 지원되지 않음 |
| 고급 ML 기능 | • 모델 데이터 수집 • 모델 모니터링 • 챔피언-챌린저 모델, 안전한 롤아웃, 트래픽 미러링 • 책임 있는 AI 확장성 |
지원되지 않음 |
관리형 온라인 엔드포인트와 Kubernetes 온라인 엔드포인트 비교
Kubernetes를 사용하여 모델을 배포하고 엔드포인트를 제공하는 것을 선호하며 인프라 요구 사항을 관리하는 데 익숙한 경우 Kubernetes 온라인 엔드포인트를 사용할 수 있습니다. 이러한 엔드포인트를 사용하면 어디서나 완전히 구성 및 관리되는 Kubernetes 클러스터에서 모델을 배포하고 CPU 또는 GPU를 사용하여 온라인 엔드포인트를 제공할 수 있습니다.
관리형 온라인 엔드포인트는 배포 프로세스를 간소화하고 Kubernetes 온라인 엔드포인트보다 다음과 같은 이점을 제공할 수 있습니다.
자동 인프라 관리
- 컴퓨팅을 프로비전하고 모델을 호스트합니다. VM(가상 머신) 유형 및 크기 조정 설정을 지정하기만 하면 됩니다.
- 기본 호스트 OS 이미지를 업데이트 및 패치합니다.
- 시스템 오류 발생 시 노드 복구를 수행합니다.
모니터링 및 로그
- Azure Monitor와의 네이티브 통합을 사용하여 모델 가용성, 성능 및 SLA를 모니터링할 수 있습니다.
- Log Analytics와의 네이티브 통합 및 로그를 사용하여 배포를 손쉽게 디버그합니다.
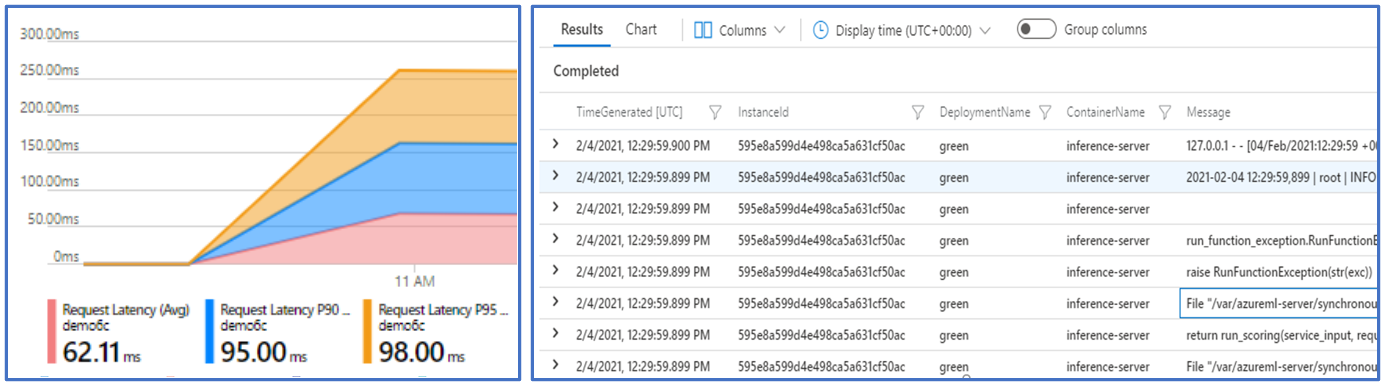
비용 분석 보기를 사용하면 엔드포인트 및 배포 수준에서 비용을 모니터링할 수 있습니다.

참고 항목
관리형 온라인 엔드포인트는 Azure Machine Learning 컴퓨팅을 기반으로 합니다. 관리형 온라인 엔드포인트를 사용하는 경우 컴퓨팅 및 네트워킹 요금을 지불합니다. 추가 요금은 없습니다. 가격 책정에 대한 자세한 내용은 Azure 가격 책정 계산기를 참조하세요.
Azure Machine Learning 가상 네트워크를 사용하여 관리형 온라인 엔드포인트에서 아웃바운드 트래픽을 보호하는 경우 관리형 가상 네트워크에서 사용하는 Azure Private Link 및 FQDN(정규화된 도메인 이름) 아웃바운드 규칙에 대한 요금이 청구됩니다. 자세한 내용은 관리형 가상 네트워크 가격 책정을 참조하세요.


다음 표에서는 관리형 온라인 엔드포인트와 Kubernetes 온라인 엔드포인트 간의 주요 차이점을 보여 줍니다.
| 관리형 온라인 엔드포인트 | Kubernetes 온라인 엔드포인트(AKS v2) | |
|---|---|---|
| 권장 사용자 | 관리 모델 배포 및 향상된 MLOps 환경을 원하는 사용자 | Kubernetes를 기본 설정하고 인프라 요구 사항을 자체 관리할 수 있는 사용자 |
| 노드 프로비전 | 관리형 컴퓨팅 프로비저닝, 업데이트, 제거 | 사용자 책임 |
| 노드 유지 관리 | 관리 호스트 OS 이미지 업데이트 및 보안 강화 | 사용자 책임 |
| 클러스터 크기 조정(크기 조정) | 추가 노드 프로비저닝을 지원하는 관리되는 수동 및 자동 크기 조정 | 수동 및 자동 크기 조정, 고정 클러스터 경계 내의 복제본 수 크기 조정 지원 |
| 컴퓨팅 형식 | 서비스에서 관리 | 고객 관리되는 Kubernetes 클러스터 |
| 관리 ID | 지원됨 | 지원됨 |
| 가상 네트워크 | 관리되는 네트워크 격리를 통해 지원됨 | 사용자 책임 |
| 기본 모니터링 및 로깅 | Azure Monitor 및 Log Analytics 기반, 엔드포인트 및 배포에 대한 주요 메트릭 및 로그 테이블 포함 | 사용자 책임 |
| Application Insights를 사용하여 로깅(레거시) | 지원됨 | 지원됨 |
| 비용 보기 | 엔드포인트/배포 수준에 대한 세부 정보 | 클러스터 수준 |
| 비용 적용 대상 | 배포에 할당된 VM(가상 머신) | 클러스터에 할당된 VM |
| 미러링된 트래픽 | 지원됨 | 지원되지 않음 |
| 코드 없는 배포 | MLflow 및 Triton 모델 지원 | MLflow 및 Triton 모델 지원 |
온라인 배포
배포는 유추를 수행하는 모델을 호스트하는 데 필요한 리소스 및 컴퓨팅 집합입니다. 단일 엔드포인트는 서로 다른 구성의 여러 배포를 포함할 수 있습니다. 이 설정은 배포에 있는 구현 세부 정보에서 엔드포인트가 제공하는 인터페이스를 분리하는 데 도움이 됩니다. 온라인 엔드포인트에는 요청을 엔드포인트의 특정 배포로 전달할 수 있는 라우팅 메커니즘이 있습니다.
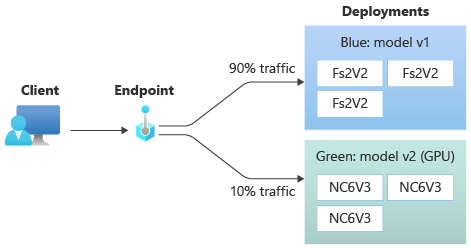
다음 다이어그램에서는 두 개의 배포인 파란색 및 녹색이 있는 온라인 엔드포인트를 보여 줍니다. 파랑색 배포는 CPU SKU와 함께 VM을 사용하고 모델의 버전 1을 실행합니다. 녹색 배포는 GPU SKU와 함께 VM을 사용하고 모델의 버전 2를 실행합니다. 엔드포인트는 들어오는 트래픽의 90%를 파란색 배포로 라우팅하는 반면, 녹색 배포는 나머지 10%를 수신하도록 구성됩니다.
모델을 배포하려면 다음이 있어야 합니다.
모델 파일, 또는 작업 영역에 이미 등록된 모델의 이름 및 버전.
채점 스크립트, 지정된 입력 요청에서 모델을 실행하는 코드.
채점 스크립트는 배포된 웹 서비스에 제출된 데이터를 수신하여 모델에 전달합니다. 그런 다음 스크립트는 모델을 실행하고 응답을 클라이언트에 반환합니다. 채점 스크립트는 모델에 따라 다르며 모델이 입력으로 예상하고 출력으로 반환하는 데이터를 이해해야 합니다.
모델을 실행할 환경. 환경은 Conda 종속성이 있는 Docker 이미지 또는 Dockerfile일 수 있습니다.
인스턴스 유형 및 크기 조정 용량을 지정하는 설정입니다.
Azure CLI, Python SDK, Azure Machine Learning 스튜디오 또는 ARM 템플릿을 사용하여 온라인 엔드포인트를 배포하는 방법을 알아보려면 온라인 엔드포인트를 사용하여 기계 학습 모델 배포를 참조하세요.
배포의 주요 특성
다음 표에서는 배포의 주요 특성을 설명합니다.
| attribute | 설명 |
|---|---|
| 이름 | 배포의 이름입니다. |
| 엔드포인트 이름 | 배포를 만들 엔드포인트의 이름입니다. |
| 모델 | 배포에 사용할 모델입니다. 이 값은 작업 영역에서 기존 버전의 모델에 대한 참조 또는 인라인 모델 사양일 수 있습니다. 모델의 경로를 추적하고 지정하는 방법에 대한 자세한 내용은 온라인 엔드포인트에서 사용할 모델 지정을 참조하세요. |
| 코드 경로 | 모델 채점을 위한 모든 Python 소스 코드가 포함된 로컬 개발 환경의 디렉터리 경로입니다. 중첩된 디렉터리 및 패키지를 사용할 수 있습니다. |
| 채점 스크립트 | 소스 코드 디렉터리에 있는 채점 파일의 상대 경로입니다. 이 Python 코드에는 init() 함수와 run() 함수가 있어야 합니다. init() 함수는 모델을 메모리에 캐시하는 등의 용도로 모델을 만들거나 업데이트한 후에 호출됩니다. run() 함수는 실제 채점/예측을 수행하도록 엔드포인트를 호출할 때마다 호출됩니다. |
| 환경 | 모델 및 코드를 호스팅할 환경입니다. 이 값은 작업 영역에서 기존 버전의 환경에 대한 참조 또는 인라인 환경 사양일 수 있습니다. |
| 인스턴스 유형 | 배포에 사용할 VM 크기입니다. 지원되는 크기 목록은 관리되는 온라인 엔드포인트 SKU 목록을 참조하세요. |
| 인스턴트 수 | 배포에 사용할 인스턴스 수입니다. 예상되는 워크로드 값을 기준으로 합니다. 고가용성을 위해 값을 3 이상으로 설정합니다. 업그레이드 수행을 위해 시스템에서 추가 20%를 예약합니다. 자세한 내용은 배포에 대한 VM 할당량 할당을 참조하세요. |
온라인 배포용 노트
배포 인스턴스가 보안 패치 또는 기타 복구 작업을 수행할 때와 같이 배포는 언제든지 환경에 정의된 모델 및 컨테이너 이미지를 참조할 수 있습니다. 배포를 위해 Azure Container Registry에 등록된 모델 또는 컨테이너 이미지를 사용하고 모델 또는 컨테이너 이미지를 나중에 제거하는 경우 이미지를 다시 생성할 때 이러한 자산을 사용하는 배포가 실패할 수 있습니다. 모델 또는 컨테이너 이미지를 제거하는 경우 대체 모델 또는 컨테이너 이미지를 사용하여 종속 배포를 다시 만들거나 업데이트해야 합니다.
환경이 참조하는 컨테이너 레지스트리는 엔드포인트 ID에 Microsoft Entra 인증 및 Azure RBAC(역할 기반 액세스 제어)를 통해 액세스할 수 있는 권한이 있는 경우에만 프라이빗일 수 있습니다. 같은 이유로 Container Registry 이외의 프라이빗 Docker 레지스트리는 지원되지 않습니다.
Microsoft는 알려진 보안 취약성에 대한 기본 이미지를 정기적으로 패치합니다. 패치된 이미지를 사용하려면 엔드포인트를 다시 배포해야 합니다. 사용자 고유의 이미지를 제공하는 경우 해당 이미지를 업데이트해야 합니다. 자세한 내용은 이미지 패치를 참조하세요.
배포를 위한 VM 할당량 할당
관리형 온라인 엔드포인트의 경우 Azure Machine Learning은 일부 VM SKU에서 업그레이드를 수행하기 위해 컴퓨팅 리소스의 20%를 예약합니다. 배포에서 해당 VM SKU에 대해 지정된 수의 인스턴스를 요청하는 경우 오류 발생을 방지하려면 사용 가능한 ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU에 대한 할당량이 있어야 합니다. 예를 들어, 배포에서 Standard_DS3_v2 VM 인스턴스 10개(코어 4개 포함)를 요청하는 경우 48개 코어(12 instances * 4 cores)에 대한 할당량을 사용할 수 있어야 합니다. 이 추가 할당량은 OS 업그레이드 및 VM 복구와 같은 시스템 시작 작업을 위해 예약되어 있으며 이러한 작업이 실행되지 않으면 비용이 발생하지 않습니다.
추가 할당량 예약에서 제외되는 특정 VM SKU가 있습니다. 전체 목록을 보려면 관리형 온라인 엔드포인트 SKU 목록을 참조하세요. 사용량을 확인하고 할당량 증가를 요청하려면 Azure Portal에서 사용량 및 할당량 보기를 참조하세요. 관리형 온라인 엔드포인트 실행 비용을 보려면 관리형 온라인 엔드포인트 비용 보기를 참조하세요.
공유 할당량 풀
Azure Machine Learning은 다양한 지역의 사용자가 할당량에 액세스하여 가용성에 따라 제한된 시간 동안 테스트를 수행할 수 있는 공유 할당량 풀을 제공합니다. 스튜디오를 사용하여 모델 카탈로그의 Llama-2, Phi, Nemotron, Mistral, Dolly 및 Deci-DeciLM 모델을 관리형 온라인 엔드포인트에 배포하는 경우 Azure Machine Learning을 사용하면 잠시 공유 할당량 풀에 액세스하여 테스트를 수행할 수 있습니다. 공유 할당량 풀에 대한 자세한 내용은 Azure Machine Learning 공유 할당량을 참조하세요.
공유 할당량을 사용하여 모델 카탈로그에서 Llama-2, Phi, Nemotron, Mistral, Dolly, Deci-DeciLM 모델을 배포하려면 기업계약 구독이 있어야 합니다. 온라인 엔드포인트 배포에 공유 할당량을 사용하는 방법에 대한 자세한 내용은 스튜디오를 사용하여 기본 모델을 배포하는 방법을 참조하세요.
Azure Machine Learning의 리소스 할당량 및 한도에 대한 자세한 내용은 Azure Machine Learning을 사용하여 리소스 할당량 및 한도 관리 및 늘리기를 참조하세요.
코더 및 비코더용 배포
Azure Machine Learning은 코드 없는 배포, 로우코드 배포 및 BYOC(Bring Your Own Container) 배포에 대한 옵션을 제공하여 코더와 비코더를 위한 온라인 엔드포인트로의 모델 배포를 지원합니다.
- 코드 없는 배포는 MLflow 및 Triton을 통해 일반적인 프레임워크(예: scikit-learn, TensorFlow, PyTorch 및 ONNX(Open Neural Network Exchange))에 대한 기본 유추를 제공합니다.
- 낮은 코드 배포를 사용하면 배포용 기계 학습 모델과 함께 최소한의 코드를 제공할 수 있습니다.
- BYOC 배포를 사용하면 사실상 모든 컨테이너를 가져와 온라인 엔드포인트를 실행할 수 있습니다. 자동 크기 조정, GitOps, 디버깅 및 안전한 롤아웃과 같은 모든 Azure Machine Learning 플랫폼 기능을 사용하여 MLOps 파이프라인을 관리할 수 있습니다.
다음 표에서는 온라인 배포 옵션에 대한 주요 측면을 강조해서 설명합니다.
| 코드 없음 | 로우 코드 | BYOC | |
|---|---|---|---|
| 요약 | MLflow 및 Triton을 통해 scikit-learn, TensorFlow, PyTorch 및 ONNX와 같은 인기 있는 프레임워크에 대해 기본 유추를 사용합니다. 자세한 내용은 온라인 엔드포인트에 MLflow 모델 배포를 참조하세요. | 인기 있는 프레임워크에 대해 공개적으로 게시된 안전하고 큐레이팅된 이미지를 사용하며 취약성을 해결하기 위해 2주마다 업데이트됩니다. 채점 스크립트 및/또는 Python 종속성을 제공합니다. 자세한 내용은 Azure Machine Learning 큐레이팅된 환경을 참조하세요. | 사용자 지정 이미지에 대한 Azure Machine Learning의 지원을 통해 전체 스택을 제공합니다. 자세한 내용은 사용자 지정 컨테이너를 사용하여 모델을 온라인 엔드포인트에 배포를 참조하세요. |
| 사용자 지정 기본 이미지 | 없음 큐레이팅된 환경은 손쉬운 배포를 위해 기본 이미지를 제공합니다. | 큐레이팅된 이미지 또는 사용자 지정된 이미지 중 하나를 선택해서 사용할 수 있습니다. | docker.io, Container Registry 또는 Microsoft 아티팩트 레지스트리와 같은 액세스 가능한 컨테이너 이미지 위치 또는 Container Registry로 컨테이너를 빌드/푸시할 수 있는 Docker 파일을 가져옵니다. |
| 사용자 지정 종속성 | 없음 큐레이팅된 환경은 손쉬운 배포를 위해 종속성을 제공합니다. | 모델이 실행되는 Azure Machine Learning 환경(Conda 종속성이 있는 Docker 이미지 또는 dockerfile)을 가져옵니다. | 사용자 지정 종속성이 컨테이너 이미지에 포함됩니다. |
| 사용자 지정 코드 | 없음 손쉬운 배포를 위해 채점 스크립트가 자동으로 생성됩니다. | 채점 스크립트를 가져옵니다. | 채점 스크립트가 컨테이너 이미지에 포함됩니다. |
참고 항목
AutoML 실행은 사용자에 대한 채점 스크립트 및 종속성을 자동으로 만듭니다. 코드 없는 배포의 경우 다른 코드를 작성하지 않고도 AutoML 모델을 배포할 수 있습니다. 로우코드 배포의 경우 자동 생성된 스크립트를 비즈니스 요구 사항에 맞게 수정할 수 있습니다. AutoML 모델을 사용하여 배포하는 방법을 알아보려면 온라인 엔드포인트에 AutoML 모델을 배포하는 방법을 참조하세요.
온라인 엔드포인트 디버깅
가능하면 Azure에 배포하기 전에 로컬에서 엔드포인트를 테스트 실행하여 코드와 구성의 유효성을 검사하고 디버그합니다. Azure CLI 및 Python SDK는 로컬 엔드포인트 및 배포를 지원하지만 Azure Machine Learning 스튜디오 및 ARM 템플릿은 로컬 엔드포인트 또는 배포를 지원하지 않습니다.
Azure Machine Learning은 다음과 같은 방법을 통해 컨테이너 로그를 사용하여 로컬로 온라인 엔드포인트를 디버그합니다.
- Azure Machine Learning 유추 HTTP 서버를 사용한 로컬 디버깅
- 로컬 엔드포인트를 사용한 로컬 디버깅
- 로컬 엔드포인트 및 Visual Studio Code를 사용한 로컬 디버깅
- 컨테이너 로그를 사용하여 디버깅
Azure Machine Learning 유추 HTTP 서버를 사용한 로컬 디버깅
Azure Machine Learning 유추 HTTP 서버를 사용하여 채점 스크립트를 로컬로 디버그할 수 있습니다. HTTP 서버는 채점 함수를 HTTP 엔드포인트로 노출하고 Flask 서버 코드 및 종속성을 단일 패키지로 래핑하는 Python 패키지입니다.
Azure Machine Learning에는 모델을 배포하는 데 사용되는 유추를 위해 미리 빌드된 Docker 이미지에 HTTP 서버가 포함되어 있습니다. 이 패키지만 사용하여 프로덕션을 위해 모델을 로컬로 배포할 수 있으며 로컬 개발 환경에서 항목 채점 스크립트의 유효성을 쉽게 검사할 수 있습니다. 채점 스크립트에 문제가 있는 경우 서버는 오류와 오류 발생 위치를 반환합니다. Visual Studio Code를 사용하여 Azure Machine Learning 유추 HTTP 서버를 사용하여 디버그할 수도 있습니다.
팁
Azure Machine Learning 유추 HTTP 서버 Python 패키지를 사용하여 Docker 엔진 없이 로컬로 채점 스크립트를 디버그할 수 있습니다. 유추 서버를 사용하여 디버깅하면 로컬 엔드포인트에 배포하기 전에 채점 스크립트를 디버그하여 배포 컨테이너 구성의 영향을 받지 않고 디버그할 수 있습니다.
HTTP 서버를 사용하여 디버그하는 방법에 대한 자세한 내용은 Azure Machine Learning 유추 HTTP 서버를 사용하여 채점 스크립트 디버깅을 참조하세요.
로컬 엔드포인트를 사용한 로컬 디버깅
로컬 디버깅의 경우 로컬 Docker 환경에 배포되는 모델이 필요합니다. 클라우드에 배포하기 전에 테스트 및 디버깅을 위해 이 로컬 배포를 사용할 수 있습니다.
로컬로 배포하려면 Docker 엔진을 설치하고 실행해야 합니다. 그러면 Azure Machine Learning이 온라인 이미지를 모방하는 로컬 Docker 이미지를 만듭니다. Azure Machine Learning은 로컬로 배포를 빌드 및 실행하고 빠른 반복을 위해 이미지를 캐시합니다.
팁
컴퓨터가 시작될 때 Docker 엔진이 시작되지 않으면 Docker 엔진의 문제를 해결하면 됩니다. Docker Desktop과 같은 클라이언트 쪽 도구를 사용하여 컨테이너에서 발생하는 상황을 디버깅할 수 있습니다.
로컬 디버깅에는 일반적으로 다음 단계가 포함됩니다.
- 먼저, 로컬 배포가 성공했는지 확인합니다.
- 다음으로, 유추를 위해 로컬 엔드포인트를 호출합니다.
- 마지막으로
invoke작업에 대한 출력 로그를 검토합니다.
로컬 엔드포인트에 대한 제한 사항은 다음과 같습니다.
트래픽 규칙, 인증 또는 프로브 설정은 지원되지 않습니다.
엔드포인트당 하나의 배포만 지원됩니다.
로컬 conda 파일을 통해서만 로컬 모델 파일 및 환경을 지원합니다.
로컬 디버깅에 대한 자세한 내용은 로컬 엔드포인트를 사용하여 로컬로 배포 및 디버그를 참조하세요.
로컬 엔드포인트 및 Visual Studio Code(미리 보기)를 사용한 로컬 디버깅
Important
이 기능은 현재 공개 미리 보기로 제공됩니다. 이 미리 보기 버전은 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다.
자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
로컬 디버깅과 마찬가지로 Docker 엔진 을 설치하고 실행한 다음, 로컬 Docker 환경에 모델을 배포해야 합니다. 로컬 배포가 있는 경우, Azure Machine Learning 로컬 엔드포인트는 Docker 및 Visual Studio Code 개발 컨테이너(개발 컨테이너)를 사용하여 로컬 디버깅 환경을 빌드하고 구성합니다.
개발 컨테이너를 사용하면 Docker 컨테이너 내에서 대화형 디버깅과 같은 Visual Studio Code 기능을 활용할 수 있습니다. Visual Studio Code에서 온라인 엔드포인트를 대화형으로 디버깅하는 방법에 대한 자세한 내용은 Visual Studio Code에서 로컬로 온라인 엔드포인트 디버그를 참조하세요.
컨테이너 로그를 사용하여 디버깅
모델이 배포되는 VM에 직접 액세스할 수는 없지만 VM에서 실행되는 다음 컨테이너에서 로그를 가져올 수 있습니다.
- 유추 서버 콘솔 로그에는 채점 스크립트 score.py 코드의 인쇄/로깅 함수 출력이 포함됩니다.
- 스토리지 이니셜라이저 로그에는 코드 및 모델 데이터가 컨테이너에 성공적으로 다운로드되었는지 여부에 대한 정보가 포함됩니다. 유추 서버 컨테이너가 실행되기 전에 컨테이너가 실행됩니다.
컨테이너 로그를 사용하여 디버깅하는 방법에 대한 자세한 내용은 컨테이너 로그 가져오기를 참조하세요.
온라인 배포에 대한 트래픽 라우팅 및 미러링
단일 엔드포인트에는 여러 배포가 있을 수 있습니다. 엔드포인트는 들어오는 트래픽 요청을 수신할 때 네이티브 파란색/녹색 배포 전략에서처럼 트래픽의 백분율을 각 배포로 라우팅할 수 있습니다. 트래픽 미러링 또는 섀도잉이라고 하는 한 배포에서 다른 배포로 트래픽을 미러(또는 복사)할 수도 있습니다.
파란색/녹색 배포를 위한 트래픽 라우팅
파란색/녹색 배포는 완전히 롤아웃하기 전에 소규모 사용자 또는 요청 하위 집합에 새 녹색 배포를 롤아웃할 수 있는 배포 전략입니다. 엔드포인트는 부하 분산을 구현하여 각 배포에 특정 비율의 트래픽을 할당하고 모든 배포에 대한 총 할당이 최대 100%까지 추가됩니다.
팁
요청은 azureml-model-deployment의 HTTP 헤더를 포함하여 구성된 트래픽 부하 분산을 무시할 수 있습니다. 요청을 라우팅하는 데 사용할 배포의 이름으로 헤더 값을 설정합니다.
다음 이미지는 파란색 배포와 녹색 배포 간에 트래픽을 할당하기 위한 Azure Machine Learning 스튜디오의 설정을 보여 줍니다.
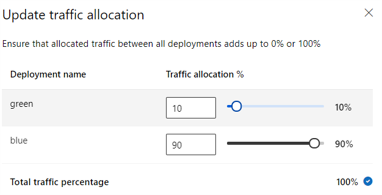
앞의 트래픽 할당은 다음 이미지와 같이 트래픽의 10%를 녹색 배포로, 트래픽의 90%를 파란색 배포로 라우팅합니다.
온라인 배포에 대한 트래픽 미러링
엔드포인트는 한 배포에서 다른 배포로 트래픽을 미러하거나 복사할 수도 있습니다. 트래픽 미러링(섀도 테스트라고도 함)은 고객이 기존 배포에서 수신하는 결과에 영향을 주지 않고 프로덕션 트래픽으로 새 배포를 테스트하려는 경우에 사용할 수 있습니다.
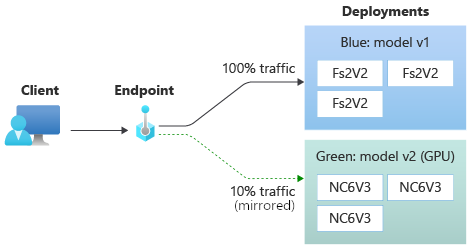
예를 들어 트래픽의 100%가 파란색으로 라우팅되고 10%가 녹색으로 미러링되는 파란색/녹색 배포를 구현할 수 있습니다. 녹색 배포에 대해 미러링된 트래픽의 결과가 클라이언트에 반환되지 않지만 메트릭과 로그가 기록됩니다.
트래픽 미러링을 사용하는 방법에 대한 자세한 내용은 실시간 유추를 위한 새 배포의 안전한 롤아웃 수행을 참조하세요.
더 많은 온라인 엔드포인트 기능
다음 섹션에서는 Azure Machine Learning 온라인 엔드포인트의 다른 기능에 대해 설명합니다.
인증 및 암호화
- 인증: 키 및 Azure Machine Learning 토큰
- 관리 ID: 사용자 할당 및 시스템 할당
- 엔드포인트 호출을 위한 기본 SSL(Secure Socket Layer)
자동 확장
자동 크기 조정은 애플리케이션의 로드를 처리하기 위해 적절한 양의 리소스를 자동으로 실행합니다. 관리 엔드포인트는 Azure Monitor 자동 크기 조정 기능과의 통합을 통해 자동 크기 조정을 지원합니다. 메트릭 기반 크기 조정(예: CPU 사용률이 >70%임) 또는 일정 기반 크기 조정(예: 최대 업무 시간) 중 하나를 구성하거나 둘 다 구성할 수 있습니다.

자세한 내용은 Azure Machine Learning에서 온라인 엔드포인트 자동 크기 조정을 참조하세요.
관리되는 네트워크 격리
기계 학습 모델을 관리형 온라인 엔드포인트에 배포할 때 프라이빗 엔드포인트를 사용하여 온라인 엔드포인트와의 통신을 보호할 수 있습니다. 인바운드 채점 요청 및 아웃바운드 통신에 대한 보안을 별도로 구성할 수 있습니다.
인바운드 통신은 Azure Machine Learning 작업 영역의 프라이빗 엔드포인트를 사용하는 반면, 아웃바운드 통신은 작업 영역의 관리형 가상 네트워크에 대해 만들어진 프라이빗 엔드포인트를 사용합니다. 자세한 내용은 관리되는 온라인 엔드포인트를 통한 네트워크 격리를 참조하세요.
온라인 엔드포인트 및 배포 모니터링
Azure Machine Learning은 Azure Monitor와 통합됩니다. Azure Monitor 통합을 사용하면 차트에서 메트릭을 보고, 경고를 구성하고, 로그 테이블에서 쿼리하고, Application Insights를 사용하여 사용자 컨테이너의 이벤트를 분석할 수 있습니다. 자세한 내용은 온라인 엔드포인트 모니터링을 참조하세요.
온라인 배포의 비밀 삽입(미리 보기)
온라인 배포의 비밀 삽입 시에는 비밀 저장소에서 API 키 같은 비밀을 검색하여 배포 내에서 실행되는 사용자 컨테이너에 삽입합니다. BYOC 배포에서 채점 스크립트 또는 추론 스택을 실행하는 유추 서버가 비밀을 안전하게 사용할 수 있도록 하려면 환경 변수를 사용하여 비밀에 액세스하면 됩니다.
관리 ID를 사용하여 직접 비밀을 삽입하거나 비밀 삽입 기능을 사용할 수 있습니다. 자세한 내용은 온라인 엔드포인트의 비밀 삽입(미리 보기)을 참조하세요.