기계 학습 파이프라인 트리거
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 Azure에서 실행할 파이프라인을 프로그래밍 방식으로 예약하는 방법을 알아봅니다. 경과된 시간 또는 파일 시스템 변경 내용에 따라 일정을 만들 수 있습니다. 시간 기반 일정을 사용하여 데이터 드리프트 모니터링과 같은 일상적인 작업을 처리할 수 있습니다. 변경 기반 일정을 사용하여 새 데이터 업로드 또는 이전 데이터 편집 등의 비정상 또는 예기치 않은 변경 내용에 대응할 수 있습니다. 일정을 만드는 방법을 알아본 후 이를 검색 및 비활성화하는 방법을 배웁니다. 마지막으로, 다른 Azure 서비스, Azure 논리 앱 및 Azure Data Factory를 사용하여 파이프라인을 실행하는 방법을 알아봅니다. Azure 논리 앱을 사용하면 더 복잡한 트리거 논리나 동작을 수행할 수 있습니다. Azure Data Factory 파이프라인을 사용하여 더 큰 데이터 오케스트레이션 파이프라인의 일부로 기계 학습 파이프라인을 호출할 수 있습니다.
필수 구성 요소
Azure 구독 Azure 구독이 아직 없는 경우 무료 계정을 만듭니다.
Python용 Azure Machine Learning SDK가 설치된 Python 환경. 자세한 내용은 Azure Machine Learning을 사용하여 학습 및 배포를 위한 재사용 가능 환경 생성 및 관리를 참조하세요.
게시된 파이프라인이 있는 Machine Learning 작업 영역. Azure Machine Learning SDK를 사용하여 기계 학습 파이프라인 만들기 및 실행에 기본 제공되는 것을 사용할 수 있습니다.
Python용 Azure Machine Learning SDK를 사용하여 파이프라인 트리거
파이프라인을 예약하려면 작업 영역에 대한 참조, 게시된 파이프라인의 식별자 및 일정을 만들려는 실험의 이름을 제공해야 합니다. 다음 코드를 사용하여 이러한 값을 가져올 수 있습니다.
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
일정 만들기
파이프라인을 반복적으로 실행하기 위해 일정을 만듭니다. Schedule은 파이프라인, 실험 및 트리거를 연결합니다. 트리거는 작업 간 대기를 설명하는 ScheduleRecurrence 또는 변경 내용을 감시하는 디렉터리를 지정하는 데이터 저장소 경로일 수 있습니다. 두 경우 모두 일정을 만들 실험의 이름과 파이프라인 식별자가 필요합니다.
Python 파일의 상단에서 Schedule 및 ScheduleRecurrence 클래스를 가져옵니다.
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
시간 기반 일정 만들기
ScheduleRecurrence 생성자에는 "Minute", "Hour", "Day", "Week" 또는 "Month" 문자열 중 하나여야 하는 필수 frequency 인수가 있습니다. 또한 일정 시작 사이에 경과해야 하는 frequency 단위 수를 지정하는 정수 interval 인수도 필요합니다. 선택적 인수를 사용하면 ScheduleRecurrence SDK 문서에 설명된 대로 시작 시간을 보다 구체적으로 지정할 수 있습니다.
15분마다 작업을 시작하는 Schedule을 만듭니다.
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
변경 기반 일정 만들기
파일 변경에 의해 트리거되는 파이프라인은 시간 기반 일정보다 효율적일 수 있습니다. 파일이 변경되거나 새 파일이 데이터 디렉터리에 추가되기 전에 작업을 수행하려는 경우 해당 파일을 전처리할 수 있습니다. 데이터 저장소에 대한 변경 내용 또는 데이터 저장소 내의 특정 디렉터리 내 변경 내용을 모니터링할 수 있습니다. 특정 디렉터리를 모니터링하는 경우 해당 디렉터리의 하위 디렉터리 내 변경 내용은 작업을 트리거하지 않습니다.
참고 항목
변경 기반 일정은 Azure Blob Storage 모니터링만 지원합니다.
파일 반응형 Schedule을 만들려면 Schedule.create에 대한 호출에 datastore 매개 변수를 설정해야 합니다. 폴더를 모니터링하려면 path_on_datastore 인수를 설정합니다.
polling_interval 인수를 사용하면 데이터 저장소의 변경 내용이 확인되는 빈도(분)를 지정할 수 있습니다.
파이프라인이 DataPath PipelineParameter를 사용하여 생성된 경우 data_path_parameter_name 인수를 설정하여 해당 변수를 변경된 파일의 이름으로 설정할 수 있습니다.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
일정을 만들 때 선택적 인수
앞에서 설명한 인수 외에도 status 인수를 "Disabled"로 설정하여 비활성 일정을 만들 수 있습니다. 마지막으로, continue_on_step_failure를 사용하여 파이프라인의 기본 오류 동작을 재정의하는 부울을 전달할 수 있습니다.
예약된 파이프라인 보기
웹 브라우저에서 Azure Machine Learning으로 이동합니다. 탐색 패널의 엔드포인트 섹션에서 파이프라인 엔드포인트를 선택합니다. 그러면 작업 영역에 게시된 파이프라인의 목록으로 이동됩니다.
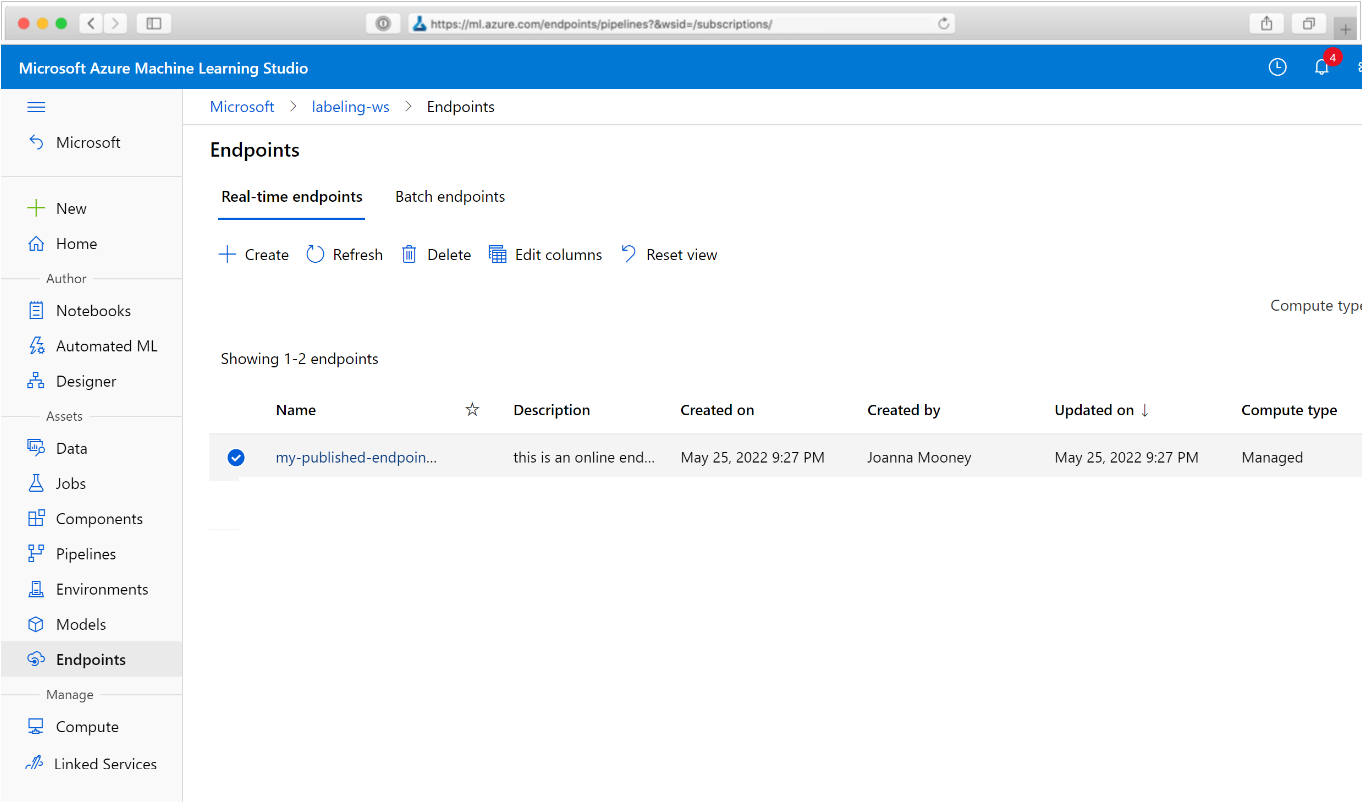
이 페이지에서 작업 영역에 있는 모든 파이프라인에 대한 이름, 설명, 상태 등의 요약 정보를 볼 수 있습니다. 파이프라인을 클릭하여 드릴 인합니다. 결과 페이지에 파이프라인에 대한 자세한 내용이 있으며 개별 작업으로 드릴 다운할 수 있습니다.
파이프라인 비활성화
Pipeline이 게시되었지만 예약되지 않은 경우 다음을 사용하여 사용하지 않도록 설정할 수 있습니다.
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
파이프라인이 예약된 경우 먼저 일정을 취소해야 합니다. 포털에서 또는 다음을 실행하여 일정의 식별자를 검색합니다.
ss = Schedule.list(ws)
for s in ss:
print(s)
사용하지 않도록 설정할 schedule_id가 있으면 다음을 실행합니다.
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
그런 다음, Schedule.list(ws)를 다시 실행하면 빈 목록이 표시됩니다.
Azure Logic Apps를 사용하여 복잡한 트리거 만들기
Azure 논리 앱을 사용하여 더 복잡한 트리거 규칙 또는 동작을 만들 수 있습니다.
Azure 논리 앱을 사용하여 Machine Learning 파이프라인을 트리거하려면 게시된 Machine Learning 파이프라인에 대한 REST 엔드포인트가 필요합니다. 파이프라인을 만들고 게시합니다. 그런 다음, 파이프라인 ID를 사용하여 PublishedPipeline의 REST 엔드포인트를 찾습니다.
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Azure에서 논리 앱을 만듭니다.
이제 Azure 논리 앱 인스턴스를 만듭니다. 논리 앱이 프로비전된 후 다음 단계에서 파이프라인에 대한 트리거를 구성합니다.
시스템 할당 관리 ID를 만들어 Azure Machine Learning 작업 영역에 액세스할 수 있는 권한을 앱에 부여합니다.
논리 앱 디자이너 뷰로 이동하고 빈 논리 앱 템플릿을 선택합니다.
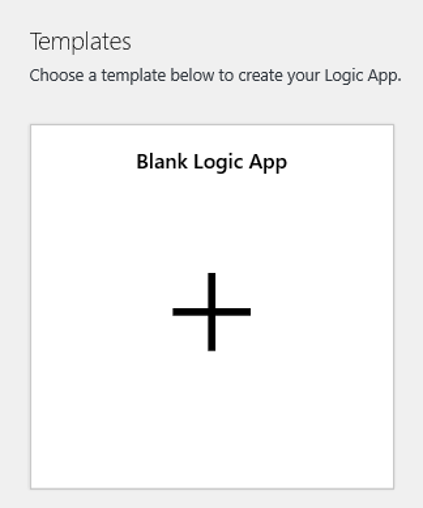
디자이너에서 Blob을 검색합니다. Blob이 추가되거나 수정된 경우(속성만) 트리거를 선택하고 논리 앱에 이 트리거를 추가합니다.
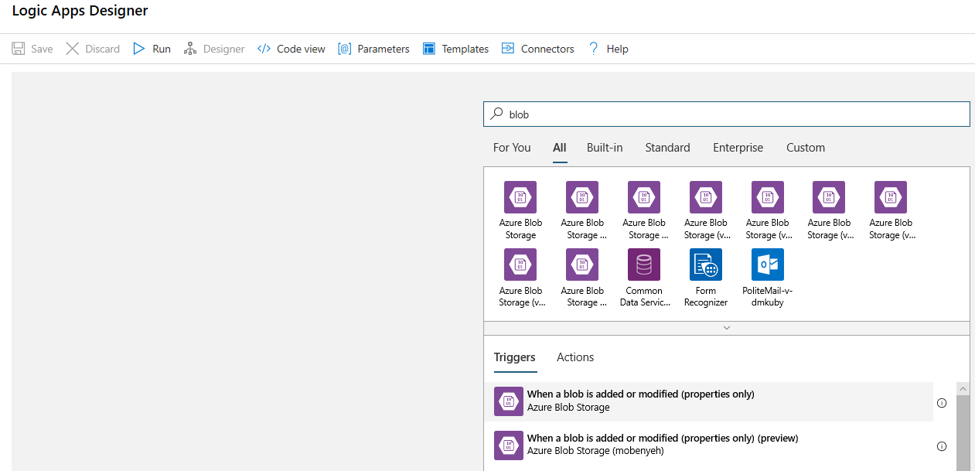
Blob 추가 또는 수정 사항을 모니터링할 Blob Storage 계정에 대한 연결 정보를 입력합니다. 모니터링할 컨테이너를 선택합니다.
업데이트를 폴링할 적당한 간격 및 빈도를 선택합니다.
참고 항목
이 트리거는 선택된 컨테이너를 모니터링하지만 하위 폴더는 모니터링하지 않습니다.
새 Blob 또는 수정된 Blob이 검색될 때 실행되는 HTTP 작업을 추가합니다. + 새 단계를 선택한 다음, HTTP 작업을 검색하고 선택합니다.
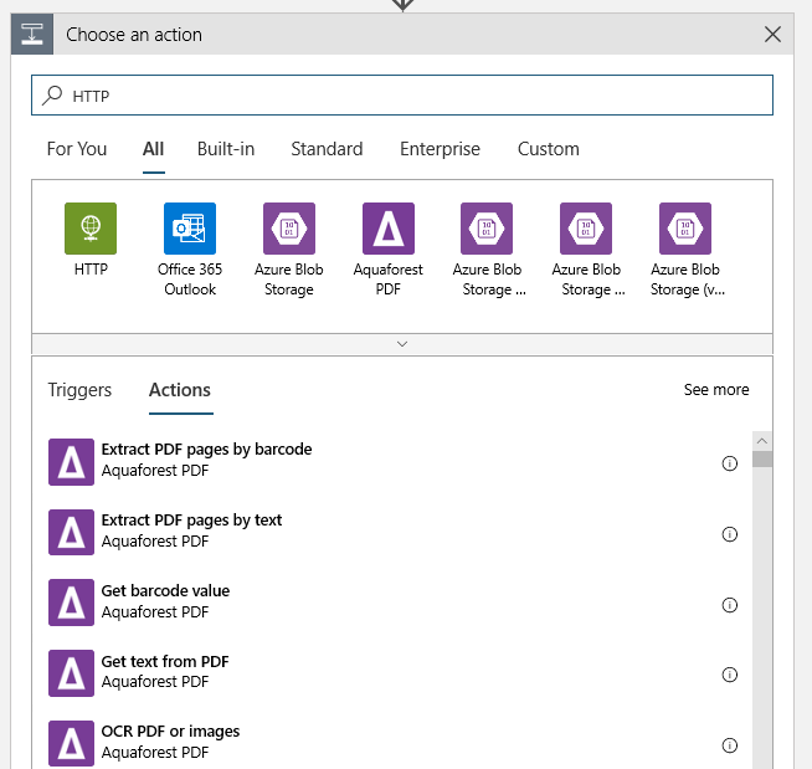
다음 설정을 사용하여 작업을 구성합니다.
| 설정 | 값 |
|---|---|
| HTTP 동작 | 게시 |
| URI | 필수 구성 요소로 확인된, 게시된 파이프라인에 대한 엔드포인트 |
| 인증 모드 | 관리 ID |
다음과 같이 일정을 설정하여 DataPath PipelineParameters의 값을 설정합니다.
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }작업 영역에 추가한
DataStoreName을 필수 구성 요소로 사용합니다.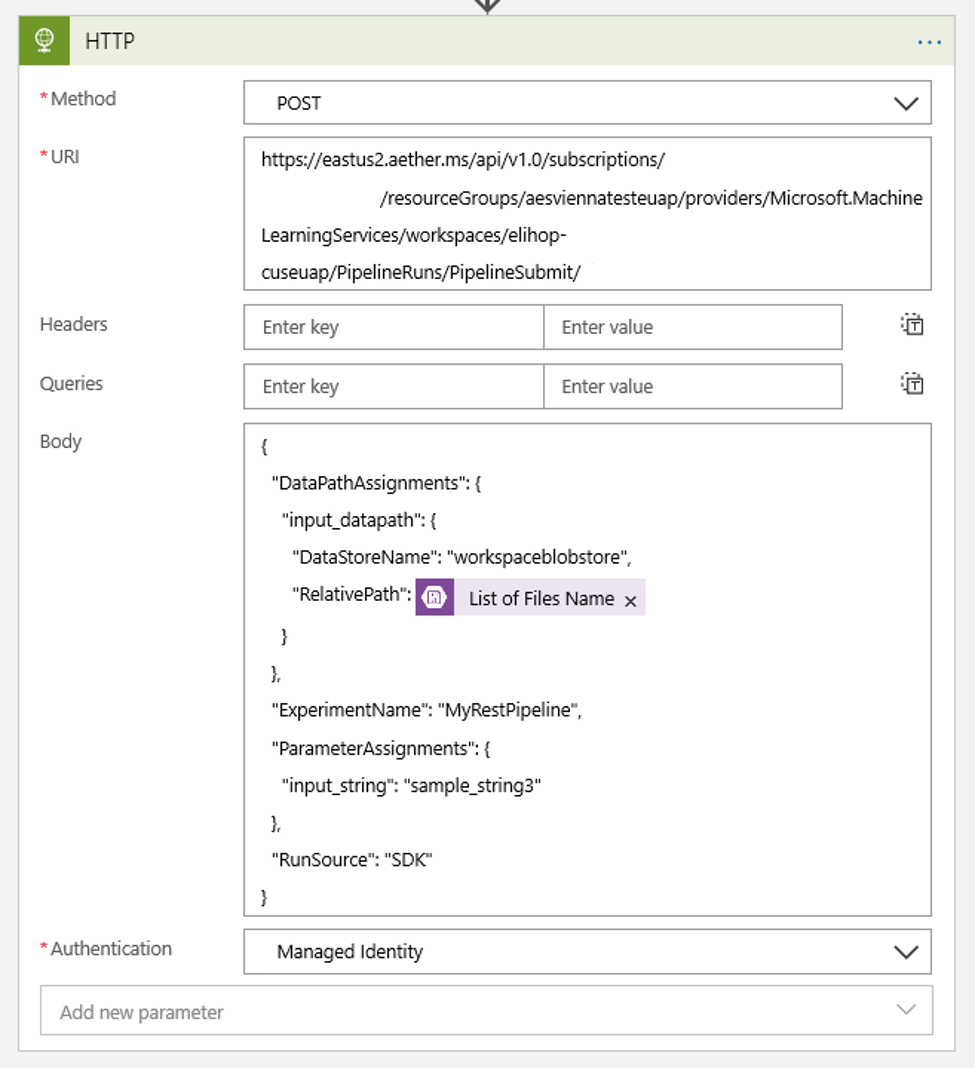
저장을 선택하면 이제 일정이 준비됩니다.
Important
Azure RBAC(역할 기반 액세스 제어)를 사용하여 파이프라인에 대한 액세스를 관리하는 경우 파이프라인 시나리오(학습 또는 채점)에 대한 사용 권한을 설정합니다.
Azure Data Factory 파이프라인에서 기계 학습 파이프라인 호출
Azure Data Factory 파이프라인에서 Machine Learning 파이프라인 실행 작업은 Azure Machine Learning 파이프라인을 실행합니다. 이 작업은 Data Factory 제작 페이지의 Machine Learning 범주 아래에서 찾을 수 있습니다.
다음 단계
이 문서에서는 Python용 Azure Machine Learning SDK를 사용하여 두 가지 방법으로 파이프라인을 예약했습니다. 한 일정은 경과된 시간에 따라 되풀이됩니다. 지정된 Datastore 또는 해당 저장소의 디렉터리 내에서 파일이 수정된 경우에 다른 일정 작업이 수행됩니다. 포털을 사용하여 파이프라인 및 개별 작업을 검사하는 방법을 살펴보았습니다. 파이프라인 실행이 중지되도록 일정을 비활성화하는 방법을 배웠습니다. 마지막으로, 파이프라인을 트리거하는 Azure 논리 앱을 만들었습니다.
자세한 내용은 다음을 참조하세요.
- 파이프라인에 대한 자세한 정보
- Jupyter를 사용한 Azure Machine Learning 탐색에 대한 자세한 정보