Azure AI 검색에서 벡터 쿼리 만들기
Azure AI 검색에서 벡터 인덱스가 있는 경우 이 문서에서는 다음 방법을 설명합니다.
이 문서에서는 설명을 위해 REST를 사용합니다. 다른 언어로 된 코드 샘플은 벡터 쿼리가 포함된 엔드투엔드 솔루션을 위한 azure-search-vector-samples GitHub 리포지토리를 참조하세요.
Azure Portal에서 검색 탐색기를 사용할 수도 있습니다.
필수 조건
모든 지역 및 모든 계층의 Azure AI 검색.
Azure AI 검색의 벡터 인덱스. 인덱스
vectorSearch섹션을 확인하여 벡터 인덱스를 확인합니다.선택적으로, 쿼리 중에 텍스트-벡터 또는 이미지-벡터 변환을 기본 제공하기 위해 인덱스에 벡터라이저를 추가할 수 있습니다.
이러한 예를 직접 실행하려는 경우 REST 클라이언트 및 샘플 데이터가 포함된 Visual Studio Code입니다. REST 클라이언트를 시작하려면 빠른 시작: REST를 사용하여 Azure AI Search를 참조하세요.
쿼리 문자열 입력을 벡터로 변환
벡터 필드를 쿼리하려면 쿼리 자체가 벡터여야 합니다.
사용자의 텍스트 쿼리 문자열을 벡터 표현으로 변환하는 한 가지 방법은 애플리케이션 코드에서 포함 라이브러리 또는 API를 호출하는 것입니다. 항상 원본 문서에서 포함을 생성하는 데 사용된 것과 동일한 포함 모델을 사용하는 것이 가장 좋습니다. azure-search-vector-samples 리포지토리에서 포함을 생성하는 방법을 보여 주는 코드 샘플을 찾을 수 있습니다.
두 번째 방식은 현재 일반 공급한 통합 벡터화를 사용하여 Azure AI 검색이 쿼리 벡터화 입력 및 출력을 처리하도록 하는 것입니다.
다음은 Azure OpenAI 포함 모델 배포에 제출된 쿼리 문자열의 REST API 예입니다.
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
배포된 모델에 대한 성공적인 호출에 대한 예상 응답은 202입니다.
응답 본문의 "embedding" 필드는 쿼리 문자열 "input"의 벡터 표현입니다. 테스트 목적으로 다음 여러 섹션에 표시된 구문을 사용하여 "embedding" 배열 값을 쿼리 요청의 "VectorQueries.Vector"에 복사합니다.
배포된 모델에 대한 이 POST 호출의 실제 응답에는 가독성을 위해 처음 몇 개의 벡터로 잘려진 1,536개의 포함 항목이 포함됩니다.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
이 방식에서 애플리케이션 코드는 모델 연결, 포함 생성 및 응답 처리를 담당합니다.
벡터 쿼리 요청
이 섹션에서는 벡터 쿼리의 기본 구조를 보여줍니다. Azure Portal, REST API 또는 Azure SDK를 사용하여 벡터 쿼리를 작성할 수 있습니다. 2023-07-01-Preview에서 마이그레이션하는 경우 호환성이 손상되는 변경이 있습니다. 자세한 내용은 최신 REST API로 업그레이드를 참조하세요.
2024-07-01은 검색 POST를 위한 안정적인 REST API 버전입니다. 이 버전은 다음을 지원합니다.
vectorQueries는 벡터 검색의 구문입니다.- 벡터 배열의 경우
vectorQueries.kind를vector로 설정하고, 입력이 문자열이고 벡터라이저가 있는 경우text로 설정합니다. vectorQueries.vector는 쿼리(텍스트 또는 이미지의 벡터 표현)입니다.vectorQueries.weight(선택 사항) 검색 작업에 포함된 각 벡터 쿼리의 상대적 가중치를 지정합니다(벡터 가중치 참조).exhaustive(선택 사항) 필드가 HNSW용으로 인덱싱된 경우에도 쿼리 시간에 전체 KNN을 호출합니다.
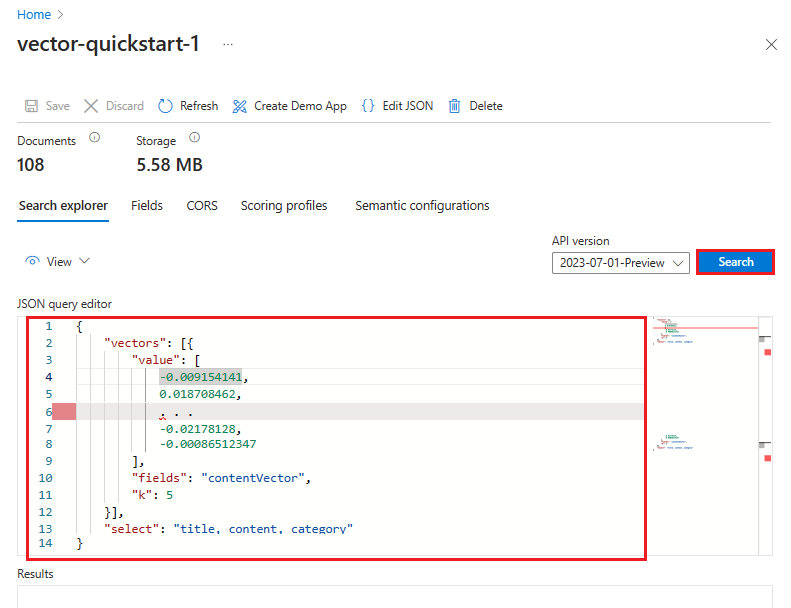
다음 예에서 벡터는 "Azure 서비스에서 전체 텍스트 검색을 지원하는 항목"이라는 문자열의 표현입니다. 쿼리는 contentVector 필드를 대상으로 합니다. 쿼리는 k 결과를 반환합니다. 실제 벡터에는 1,536개의 임베딩이 있으므로 가독성을 위해 이 예제에서 잘립니다.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
벡터 쿼리 응답
Azure AI 검색에서 쿼리 응답은 기본적으로 모든 retrievable 필드로 구성됩니다. 그러나 검색 결과를 select 문에 나열하여 retrievable 필드의 하위 집합으로 제한하는 것이 일반적입니다.
벡터 쿼리에서는 응답에 벡터 필드가 필요한지 신중하게 고려합니다. 벡터 필드는 인간이 읽을 수 없으므로 웹 페이지에 응답을 푸시하는 경우 결과를 나타내는 벡터가 아닌 필드를 선택해야 합니다. 예를 들어, 쿼리가 contentVector에 대해 실행되는 경우 대신 content를 반환할 수 있습니다.
결과에 벡터 필드를 원하는 경우 응답 구조의 예는 다음과 같습니다. contentVector는 포함의 문자열 배열이며, 여기서는 간결함을 위해 잘렸습니다. 검색 점수는 관련성을 나타냅니다. 컨텍스트를 위해 다른 벡터가 아닌 필드가 포함됩니다.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
주요 정보:
k는 가장 인접한 항목 결과가 반환되는 수(이 경우 3개)를 결정합니다. 벡터 쿼리는 적어도k문서가 존재한다고 가정하면 유사성이 낮은 문서가 있더라도 알고리즘이 쿼리 벡터에 가장 가까운k인접 항목을 찾으므로 항상k결과를 반환합니다.@search.score는 벡터 검색 알고리즘에 의해 결정됩니다.검색 결과의 필드는 모두
retrievable필드이거나select절의 필드입니다. 벡터 쿼리 실행 중에는 벡터 데이터에서만 일치가 이루어집니다. 그러나 응답에는 인덱스의 모든retrievable필드가 포함될 수 있습니다. 벡터 필드 결과를 디코딩할 수 있는 기능이 없으므로 벡터가 아닌 텍스트 필드를 포함하면 사람이 읽을 수 있는 값을 얻을 수 있습니다.
여러 벡터 필드
"vectorQueries.fields" 속성을 여러 벡터 필드로 설정할 수 있습니다. 벡터 쿼리는 fields 목록에 제공한 각 벡터 필드에 대해 실행됩니다. 여러 벡터 필드를 쿼리할 때 각 필드에 동일한 포함 모델의 포함이 포함되어 있는지 확인하고 쿼리도 동일한 포함 모델에서 생성되었는지 확인합니다.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
다중 벡터 쿼리
다중 쿼리 벡터 검색은 검색 인덱스의 여러 벡터 필드에 여러 쿼리를 보냅니다. 이 쿼리 요청의 일반적인 예는 동일한 모델이 이미지 및 텍스트 콘텐츠를 벡터화할 수 있는 다중 모달 벡터 검색에 CLIP과 같은 모델을 사용하는 경우입니다.
다음 쿼리 예제에서는 myImageVector 및 myTextVector 모두에서 유사성을 찾지만 각각 병렬로 실행되는 두 개의 서로 다른 쿼리 포함을 보냅니다. 이 쿼리는 RRF(상호 순위 퓨전)를 사용하여 점수가 매겨진 결과를 생성합니다.
vectorQueries는 벡터 쿼리의 배열을 제공합니다.vector에는 검색 인덱스의 이미지 벡터 및 텍스트 벡터가 포함됩니다. 각 인스턴스는 별도의 쿼리입니다.fields는 대상으로 지정할 벡터 필드를 지정합니다.k는 결과에 포함할 가장 가까운 인접 항목의 수입니다.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
검색 결과에는 텍스트와 이미지의 조합이 포함되며, 검색 인덱스가 이미지 파일에 대한 필드를 포함하고 있다고 가정합니다(검색 인덱스가 이미지를 저장하지 않음).
통합 벡터화를 사용한 쿼리
이 섹션에서는 텍스트나 이미지 쿼리를 벡터로 변환하는 통합 벡터화를 호출하는 벡터 쿼리를 보여 줍니다. 이 기능을 사용하려면 안정적인 2024-07-01 REST API, Search Explorer 또는 최신 Azure SDK 패키지를 사용하는 것이 좋습니다.
필수 구성 요소는 벡터 필드에 벡터라이저가 구성되고 할당된 검색 인덱스입니다. 벡터라이저는 쿼리 시간에 사용되는 임베딩 모델에 대한 연결 정보를 제공합니다.
검색 탐색기는 쿼리 시점에 통합 벡터화를 지원합니다. 인덱스에 벡터 필드가 포함되어 있고 벡터라이저가 있는 경우, 기본 제공된 텍스트-벡터 변환 기능을 사용할 수 있습니다.
Azure 계정으로 Azure Portal에 로그인하고 Azure AI 검색 서비스로 이동합니다.
왼쪽 메뉴에서 검색 관리>인덱스를 확장하고 인덱스를 선택합니다. 검색 탐색기는 인덱스 페이지의 첫 번째 탭입니다.
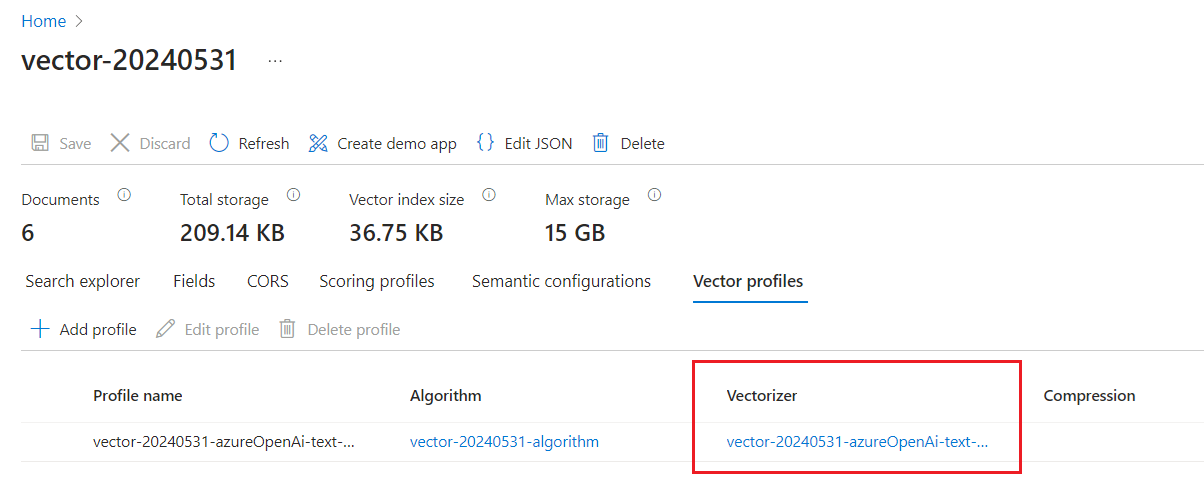
벡터 프로필을 확인하여 벡터라이저가 있는지 확인합니다.
검색 탐색기에서 쿼리 보기의 기본 쿼리 창에 텍스트 문자열을 입력할 수 있습니다. 기본 제공된 벡터라이저는 문자열을 벡터로 변환하고 검색을 수행하여 결과를 반환합니다.
또는 보기>JSON 보기를 선택하여 쿼리를 보거나 수정할 수 있습니다. 벡터가 있으면 검색 탐색기가 자동으로 벡터 쿼리를 설정합니다. JSON 보기를 사용하면 검색과 응답에 사용되는 필드를 선택하고, 필터를 추가하거나, 하이브리드와 같은 고급 쿼리를 구성할 수 있습니다. 이 섹션의 REST API 탭에는 JSON 예가 제공됩니다.
벡터 쿼리 응답의 순위가 지정된 결과 수
벡터 쿼리는 결과에 반환되는 일치 항목 수를 결정하는 k 매개 변수를 지정합니다. 검색 엔진은 항상 k개의 일치 항목 수를 반환합니다. k이 인덱스의 문서 수보다 큰 경우 문서 수가 반환될 수 있는 항목의 상한을 결정합니다.
전체 텍스트 검색에 익숙한 경우 인덱스가 용어 또는 구를 포함하지 않는다면 결과가 0개가 될 것으로 예상해야 합니다. 그러나 벡터 검색에서 검색 작업은 가장 가까운 인접 항목을 식별하고 가장 가까운 인접 항목이 유사하지 않더라도 항상 k 결과를 반환합니다. 따라서 특히 프롬프트를 사용하여 경계를 설정하지 않는 경우 무의미하거나 토픽이 아닌 쿼리에 대한 결과를 얻을 수 있습니다. 관련성이 낮은 결과는 유사성 점수가 더 좋지만 더 가까운 항목이 없으면 여전히 "가장 가까운" 벡터입니다. 따라서 의미 있는 결과가 없는 응답은 k 결과를 반환할 수 있지만, 각 결과의 유사성 점수는 낮습니다.
전체 텍스트 검색을 포함하는 하이브리드 접근 방식은 이 문제를 완화할 수 있습니다. 또 다른 완화 방법은 쿼리가 순수 단일 벡터 쿼리인 경우에만 검색 점수에 대한 최소 임계값을 설정하는 것입니다. 하이브리드 쿼리는 RRF 범위가 훨씬 작고 휘발성이므로 최소 임계값에 도움이 되지 않습니다.
결과 수에 영향을 주는 쿼리 매개 변수는 다음과 같습니다.
- 벡터 전용 쿼리에 대한
"k": n결과 - "search" 매개 변수를 포함하는 하이브리드 쿼리에 대한
"top": n결과
"k" 및 "top"은 모두 선택 사항입니다. 지정되지 않은 응답의 기본 결과 수는 50입니다. 더 많은 결과를 통해 페이지를 "top" 및 "skip"로 설정하거나 기본값을 변경할 수 있습니다.
벡터 쿼리에 사용되는 순위 지정 알고리즘
결과의 순위는 다음 중 하나를 통해 계산됩니다.
- 유사성 메트릭
- 여러 검색 결과 집합이 있는 경우 RRF(상호 순위 퓨전)입니다.
유사성 메트릭
벡터 전용 쿼리의 인덱스 vectorSearch 섹션에 지정된 유사성 메트릭입니다. 유효한 값은 cosine, euclidean 및 dotProduct입니다.
Azure OpenAI 임베딩 모델은 코사인 유사성을 사용하므로 Azure OpenAI 포함 모델을 사용하는 경우 cosine가 권장되는 메트릭입니다. 지원되는 기타 순위 메트릭에는 euclidean과 dotProduct이 항목이 포함됩니다.
RRF 사용
쿼리가 여러 벡터 필드를 대상으로 하거나 여러 벡터 쿼리를 병렬로 실행하는 경우 또는 쿼리가 의미 순위매기기 유무에 관계없이 벡터 쿼리와 전체 텍스트 검색이 혼합된 경우 여러 집합이 만들어집니다.
쿼리 실행 중에 벡터 쿼리는 하나의 내부 벡터 인덱스만 대상으로 지정할 수 있습니다. 따라서 다중 벡터 필드와 다중 벡터 쿼리의 경우 검색 엔진은 각 필드의 각 벡터 인덱스를 대상으로 하는 여러 쿼리를 생성합니다. 출력은 RRF를 사용하여 융합되는 각 쿼리에 대한 순위가 매겨진 결과 집합입니다. 자세한 내용은 RRF(Reciprocal Rank Fusion)를 사용한 관련성 점수를 참조하세요.
벡터 가중치
weight 쿼리 매개 변수를 추가하여 검색 작업에 포함된 각 벡터 쿼리의 상대적 가중치를 지정합니다. 이 값은 동일한 요청의 두 개 이상의 벡터 쿼리 또는 하이브리드 쿼리의 벡터 부분에서 생성된 여러 순위 지정 목록의 결과를 결합할 때 사용됩니다.
기본값은 1.0이고 값은 0보다 큰 양수여야 합니다.
가중치는 각 문서의 상호 순위 융합 점수를 계산할 때 사용됩니다. 계산은 해당 결과 집합 내의 문서의 순위 점수에 대한 weight 값의 승수입니다.
다음 예에서는 두 개의 벡터 쿼리 문자열과 하나의 텍스트 문자열이 포함된 하이브리드 쿼리입니다. 가중치는 벡터 쿼리에 할당됩니다. 첫 번째 쿼리는 가중치가 0.5 또는 절반이므로 요청에서 중요도가 줄어듭니다. 두 번째 벡터 쿼리는 두 배나 중요합니다.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
벡터 가중치는 벡터에만 적용됩니다. 이 예제의 텍스트 쿼리(“헬로 월드”)는 암시적 가중치 1.0 또는 중립 가중치를 가집니다. 그러나 하이브리드 쿼리에서는 maxTextRecallSize를 설정하여 텍스트 필드의 중요도를 늘리거나 줄일 수 있습니다.
임곗값을 설정하여 점수가 낮은 결과 제외(미리 보기)
가장 인접한 항목 검색은 항상 요청된 k 인접 항목을 반환하므로 검색 결과에 대한 k 수 요구 사항을 충족하는 과정에서 점수가 낮은 일치 항목을 여러 개 얻을 수 있습니다. 점수가 낮은 검색 결과를 제외하려면 최소 점수를 기준으로 결과를 필터링하는 threshold 쿼리 매개 변수를 추가할 수 있습니다. 필터링은 서로 다른 회수 집합에서 결과를 융합하기 전에 발생합니다.
이 매개 변수는 아직 미리 보기 단계에 있습니다. 미리 보기 REST API 버전 2024-05-01-preview를 사용하는 것이 좋습니다.
이 예에서는 결과 수가 k 미만이더라도 점수가 0.8 미만인 모든 일치 항목이 벡터 검색 결과에서 제외됩니다.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
하이브리드 검색을 위한 MaxTextSizeRecall(미리 보기)
벡터 쿼리는 벡터가 아닌 필드를 포함하는 하이브리드 구문에 자주 사용됩니다. BM25 순위 지정 결과가 하이브리드 쿼리 결과에서 초과 또는 과소 표시되는 경우 maxTextRecallSize를 설정하여 하이브리드 순위 지정에 제공되는 BM25 순위 지정 결과를 높이거나 낮출 수 있습니다.
"search" 및 "VectorQueries" 구성 요소를 모두 포함하는 하이브리드 요청에서만 이 속성을 설정할 수 있습니다.
이 매개 변수는 아직 미리 보기 단계에 있습니다. 미리 보기 REST API 버전 2024-05-01-preview를 사용하는 것이 좋습니다.
자세한 내용은 maxTextRecallSize 설정 - 하이브리드 쿼리 만들기를 참조하세요.
다음 단계
다음 단계로, Python, C# 또는 JavaScript의 벡터 쿼리 코드 예를 검토합니다.