테이블 디자인 패턴
이 아티클에서는 Table service 솔루션에서 사용하기에 적합한 몇 가지 패턴에 대해 알아봅니다. 또한 다른 Table Storage 디자인 아티클에서 설명한 문제 및 장단점 중 일부를 실용적으로 해결할 수 있는 방법도 확인합니다. 다음 다이어그램에는 서로 다른 패턴 간의 관계가 요약되어 있습니다.
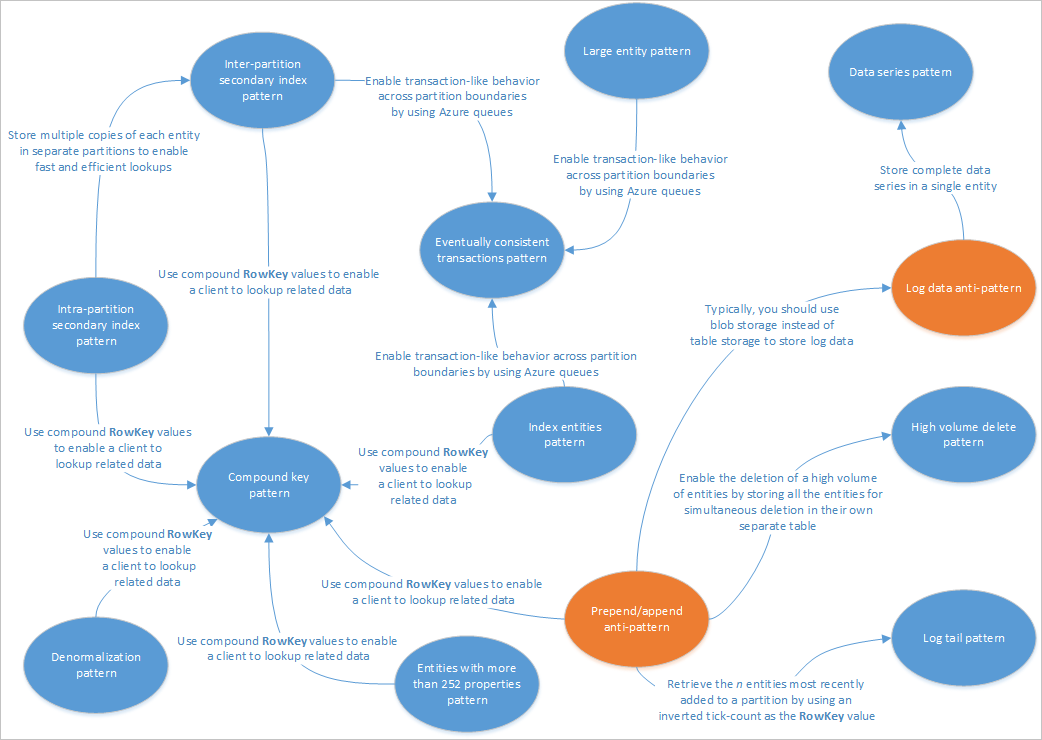
위 패턴 맵에는 이 가이드에 설명된 패턴(파란색)과 안티패턴(주황색) 간의 몇 가지 관계가 강조되어 있습니다. 고려할 가치가 있는 다른 많은 패턴이 있습니다. 예를 들어 Table service의 주요 시나리오 중 하나는 CQRS(Command Query Responsibility Segregation) 패턴에서 구체화된 뷰 패턴을 사용하는 것입니다.
파티션 간 보조 인덱스 패턴
서로 다른 RowKey 값(동일한 파티션에서)을 사용하여 각 엔터티의 여러 복사본을 저장하여 빠르고 효율적인 조회를 지원하며, 서로 다른 RowKey 값을 사용하여 대체 정렬 순서를 허용합니다. EGT(엔티티 그룹 트랜잭션)를 사용하여 복사본 간의 업데이트를 일관되게 유지할 수 있습니다.
컨텍스트 및 문제점
Table service는 PartitionKey 및 RowKey 값을 사용하여 엔터티를 자동으로 인덱싱합니다. 따라서 클라이언트 애플리케이션이 이러한 값을 사용하여 엔터티를 효율적으로 검색할 수 있습니다. 예를 들어 아래에 표시된 테이블 구조를 사용할 경우 클라이언트 애플리케이션은 지점 쿼리를 사용하여 부서 이름 및 직원 ID(PartitionKey 및 RowKey 값)로 개별 직원 엔터티를 검색할 수 있습니다. 또한 클라이언트는 각 부서 내에서 직원 ID별로 정렬된 엔터티를 검색할 수 있습니다.

전자 메일 주소와 같은 다른 속성 값으로 기반으로 직원 엔터티를 찾을 수 있도록 하려면 비효율적인 파티션 검색을 사용하여 일치하는 항목을 찾아야 합니다. 테이블 서비스에서는 보조 인덱스를 제공하지 않기 때문입니다. 또한 RowKey 와 다른 순서로 정렬된 직원 목록을 요청하는 옵션도 없습니다.
솔루션
보조 인덱스가 없는 문제를 해결하려면 각 엔터티의 여러 복사본을 다른 RowKey 값을 사용하는 각 복사본과 함께 저장하면 됩니다. 아래에 표시된 구조로 엔터티를 저장하면 이메일 주소 또는 직원 ID를 기반으로 직원 엔터티를 효율적으로 검색할 수 있습니다. RowKey의 접두사 값 "empid_" 및 "email_"은 이메일 주소 또는 직원 ID의 범위를 사용하여 단일 직원 또는 직원 범위를 쿼리할 수 있도록 해줍니다.

다음 두 필터 조건(직원 ID로 조회하는 필터와 이메일 주소로 조회하는 필터)은 모두 지점 쿼리를 지정합니다.
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'email_jonesj@contoso.com')
직원 엔터티 범위를 쿼리하는 경우 RowKey의 해당 접두사로 엔터티를 쿼리하여 직원 ID 순으로 정렬된 범위 또는 이메일 주소 순으로 정렬된 범위를 지정할 수 있습니다.
영업 부서에서 직원 ID 범위가 000100~000199인 모든 직원을 찾으려면 다음을 사용합니다. $filter=(PartitionKey eq 'Sales') 및 (RowKey ge 'empid_000100') 및 (RowKey le 'empid_000199')
Sales 부서에서 이메일 주소가 'a'로 시작하는 모든 직원을 찾으려면 다음을 사용합니다. $filter=(PartitionKey eq 'Sales') and (RowKey ge 'email_a') and (RowKey lt 'email_b')
위 예제에 사용된 필터 구문은 Table service REST API에서 가져온 것입니다(자세한 내용은 엔터티 쿼리 참조).
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
Table Storage는 비교적 저렴하게 사용할 수 있으므로 중복 데이터 저장에 대한 비용 오버헤드가 주요 관심사여서는 안 됩니다. 그러나 항상 예상된 스토리지 요구 사항을 기반으로 디자인 비용을 평가하고, 클라이언트 애플리케이션에서 실행할 쿼리를 지원하는 데 필요한 경우에만 중복 엔터티를 추가해야 합니다.
보조 인덱스 엔터티는 원래 엔터티와 동일한 파티션에 저장되므로 개별 파티션의 확장성 목표를 초과하지 않도록 해야 합니다.
EGT를 사용하여 엔터티의 두 복사본을 원자성으로 업데이트하는 방식으로 중복 엔터티를 서로 일관성 있게 유지할 수 있습니다. 이는 엔터티의 모든 복사본을 동일한 파티션에 저장해야 함을 의미합니다. 자세한 내용은 엔터티 그룹 트랜잭션 사용섹션을 참조하세요.
RowKey 에 사용된 값은 각 엔터티마다 고유해야 합니다. 복합 키 값을 사용하는 것이 좋습니다.
RowKey 의 숫자 값을 채우면(예: 직원 ID 000223) 상한 및 하한에 따라 올바르게 정렬 및 필터링됩니다.
엔터티의 모든 속성을 복제할 필요는 없습니다. 예를 들어 RowKey에서 이메일 주소를 사용하여 엔터티를 조회하는 쿼리에 직원의 나이가 필요 없는 경우 이러한 엔터티의 구조는 다음과 같을 수 있습니다.

일반적으로 중복 데이터를 저장하고 단일 쿼리로 필요한 모든 데이터를 검색할 수 있도록 하는 것이 하나의 쿼리를 사용하여 엔터티를 찾고 다른 쿼리를 사용하여 필요한 데이터를 조회하는 것보다 좋습니다.
이 패턴을 사용해야 하는 경우
클라이언트 애플리케이션에서 다양한 키를 사용하여 엔터티를 검색해야 하는 경우, 클라이언트에서 다른 정렬 순서로 엔터티를 검색해야 하는 경우, 다양한 고유 값을 사용하여 각 엔터티를 식별할 수 있는 경우 등에 이 패턴을 사용합니다. 그러나 다른 RowKey 값을 사용하여 엔터티 조회를 수행할 때는 파티션 확장성 제한을 초과하지 않도록 해야 합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 파티션 내 보조 인덱스 패턴
- 복합 키 패턴
- 엔터티 그룹 트랜잭션
- 유형이 다른 엔터티 유형 작업
파티션 간 보조 인덱스 패턴
서로 다른 RowKey 값을 사용하여 각 엔터티의 여러 복사본을 별도의 파티션 또는 별도의 테이블에 저장하여 빠르고 효율적인 조회를 지원하며, 서로 다른 RowKey 값을 사용하여 대체 정렬 순서를 허용합니다.
컨텍스트 및 문제점
Table service는 PartitionKey 및 RowKey 값을 사용하여 엔터티를 자동으로 인덱싱합니다. 따라서 클라이언트 애플리케이션이 이러한 값을 사용하여 엔터티를 효율적으로 검색할 수 있습니다. 예를 들어 아래에 표시된 테이블 구조를 사용할 경우 클라이언트 애플리케이션은 지점 쿼리를 사용하여 부서 이름 및 직원 ID(PartitionKey 및 RowKey 값)로 개별 직원 엔터티를 검색할 수 있습니다. 또한 클라이언트는 각 부서 내에서 직원 ID별로 정렬된 엔터티를 검색할 수 있습니다.

전자 메일 주소와 같은 다른 속성 값으로 기반으로 직원 엔터티를 찾을 수 있도록 하려면 비효율적인 파티션 검색을 사용하여 일치하는 항목을 찾아야 합니다. 테이블 서비스에서는 보조 인덱스를 제공하지 않기 때문입니다. 또한 RowKey 와 다른 순서로 정렬된 직원 목록을 요청하는 옵션도 없습니다.
이러한 엔터티에 대한 트랜잭션 볼륨이 클 것으로 예상되는 경우 클라이언트를 제한하여 Table service의 위험을 최소화할 수 있습니다.
솔루션
보조 인덱스가 없는 문제를 해결하려면 각 엔터티의 여러 복사본을 다른 PartitionKey 및 RowKey 값을 사용하는 각 복사본과 함께 저장하면 됩니다. 아래에 표시된 구조로 엔터티를 저장하면 이메일 주소 또는 직원 ID를 기반으로 직원 엔터티를 효율적으로 검색할 수 있습니다. PartitionKey의 접두사 값 "empid_" 및 "email_"은 쿼리에 사용할 수 있는 인덱스를 구분할 수 있도록 해줍니다.
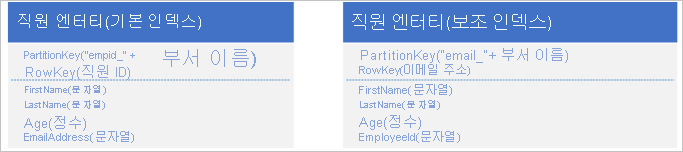
다음 두 필터 조건(직원 ID로 조회하는 필터와 이메일 주소로 조회하는 필터)은 모두 지점 쿼리를 지정합니다.
- $filter=(PartitionKey eq 'empid_Sales') and (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') and (RowKey eq 'jonesj@contoso.com')
직원 엔터티 범위를 쿼리하는 경우 RowKey의 해당 접두사로 엔터티를 쿼리하여 직원 ID 순으로 정렬된 범위 또는 이메일 주소 순으로 정렬된 범위를 지정할 수 있습니다.
- 영업 부서에서 직원 ID 순으로 정렬하여 직원 ID 범위가 000100~000199인 모든 직원을 찾으려면 다음을 사용합니다. $filter=(PartitionKey eq 'empid_Sales') 및 (RowKey ge '000100') 및 (RowKey le '000199')
- Sales 부서에서 직원 이메일 주소순으로 정렬하여 이메일 주소가 'a'로 시작하는 모든 직원을 찾으려면 다음을 사용합니다. $filter=(PartitionKey eq 'email_Sales') and (RowKey ge 'a') and (RowKey lt 'b')
위 예제에 사용된 필터 구문은 Table service REST API에서 가져온 것입니다(자세한 내용은 엔터티 쿼리 참조).
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
결과적으로 일관성 있는 트랜잭션 패턴 을 사용하여 주 인덱스 엔터티 및 보조 인덱스 엔터티를 유지 관리함으로써 중복 엔터티를 서로 일관성 있게 유지할 수 있습니다.
Table Storage는 비교적 저렴하게 사용할 수 있으므로 중복 데이터 저장에 대한 비용 오버헤드가 주요 관심사여서는 안 됩니다. 그러나 항상 예상된 스토리지 요구 사항을 기반으로 디자인 비용을 평가하고, 클라이언트 애플리케이션에서 실행할 쿼리를 지원하는 데 필요한 경우에만 중복 엔터티를 추가해야 합니다.
RowKey 에 사용된 값은 각 엔터티마다 고유해야 합니다. 복합 키 값을 사용하는 것이 좋습니다.
RowKey 의 숫자 값을 채우면(예: 직원 ID 000223) 상한 및 하한에 따라 올바르게 정렬 및 필터링됩니다.
엔터티의 모든 속성을 복제할 필요는 없습니다. 예를 들어 RowKey에서 이메일 주소를 사용하여 엔터티를 조회하는 쿼리에 직원의 나이가 필요 없는 경우 이러한 엔터티의 구조는 다음과 같을 수 있습니다.

일반적으로 중복 데이터를 저장하고 단일 쿼리로 필요한 모든 데이터를 검색할 수 있도록 하는 것이 하나의 쿼리를 사용하여 보조 인덱스에서 엔터티를 찾고 다른 쿼리를 사용하여 기본 인덱스에서 필요한 데이터를 조회하는 것보다 좋습니다.
이 패턴을 사용해야 하는 경우
클라이언트 애플리케이션에서 다양한 키를 사용하여 엔터티를 검색해야 하는 경우, 클라이언트에서 다른 정렬 순서로 엔터티를 검색해야 하는 경우, 다양한 고유 값을 사용하여 각 엔터티를 식별할 수 있는 경우 등에 이 패턴을 사용합니다. 다른 RowKey 값을 사용하여 엔터티 조회를 수행할 때는 파티션 확장성 제한을 초과하지 않도록 하려는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 결과적으로 일관성 있는 트랜잭션 패턴
- 파티션 간 보조 인덱스 패턴
- 복합 키 패턴
- 엔터티 그룹 트랜잭션
- 유형이 다른 엔터티 유형 작업
결과적으로 일관성 있는 트랜잭션 패턴
Azure 큐를 사용하여 파티션 경계 또는 스토리지 시스템 경계 간에 결과적으로 일관성 있는 동작을 지원합니다.
컨텍스트 및 문제점
EGT는 동일한 파티션 키를 공유하는 여러 엔터티 간의 원자성 트랜잭션을 지원합니다. 성능 및 확장성 때문에, 일관성 요구 사항이 있는 엔터티를 별도의 파티션 또는 별도의 스토리지 시스템에 저장해야 할 수 있습니다. 이 시나리오에서는 EGT를 사용하여 일관성을 유지할 수 없습니다. 예를 들어 다음 엔터티 간에 결과적 일관성을 유지해야 하는 요구 사항이 있을 수 있습니다.
- 동일한 테이블, 서로 다른 테이블 또는 서로 다른 스토리지 계정의 두 파티션에 저장된 엔터티
- Table service에 저장된 엔터티와 Blob service에 저장된 Blob
- Table service에 저장된 엔터티와 파일 서비스에 저장된 파일
- Azure Cognitive Search 서비스를 사용하여 아직 인덱싱되지 않은 Table service에 저장된 엔터티.
솔루션
Azure 큐를 사용하면 둘 이상의 파티션 또는 스토리지 시스템 간에 결과적 일관성을 유지하는 솔루션을 구현할 수 있습니다. 이 접근 방식을 설명하기 위해 이전 직원 엔터티를 보관할 수 있어야 하는 요구 사항이 있는 것으로 가정합니다. 이전 직원 엔터티는 거의 쿼리되지 않으므로 현재 직원을 다루는 활동에서 제외해야 합니다. 이 요구 사항을 구현하기 위해 현재 직원을 현재 테이블에 저장하고 이전 직원을 보관 테이블에 저장합니다. 직원을 보관하려면 현재 테이블에서 해당 엔터티를 삭제하고 보관 테이블에 엔터티를 추가해야 하지만 EGT를 사용하여 이 두 작업을 수행할 수는 없습니다. 오류로 인해 하나의 엔터티가 두 테이블 모두에 표시되거나 아무 테이블에도 표시되지 않는 위험을 방지하려면 보관 작업이 결과적으로 일관성이 있어야 합니다. 다음 시퀀스 다이어그램에 이 작업의 단계가 요약되어 있습니다. 다음 텍스트에 예외 경로에 대한 자세한 정보가 나와 있습니다.
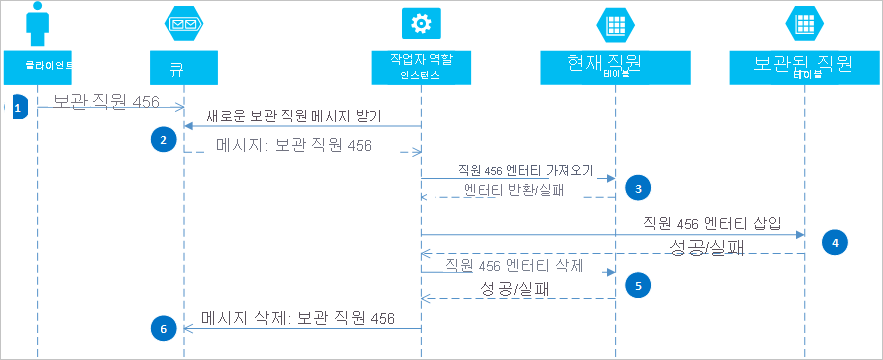
클라이언트가 메시지를 Azure 큐에 추가하여 보관 작업을 시작합니다(이 예제의 경우 employee #456 보관). 작업자 역할이 새 메시지에 대해 큐를 폴링합니다. 새 메시지를 찾은 경우 메시지를 읽고 숨겨진 복사본을 큐에 남겨 둡니다. 작업자 역할이 현재 테이블에서 엔터티의 복사본을 가져와 보관 테이블에 삽입한 다음 현재 테이블에서 원래 엔터티를 삭제합니다. 마지막으로 이전 단계에서 오류가 발생하지 않은 경우 작업자 역할이 큐에서 숨겨진 메시지를 삭제합니다.
이 예제의 4단계에서는 직원을 보관 테이블에 삽입합니다. Blob service의 Blob 또는 파일 시스템의 파일에 직원을 추가할 수도 있습니다.
오류 복구
작업자 역할이 보관 작업을 다시 시작해야 하는 것일 경우 4단계 및 5단계의 작업은 멱등원이어야 하는 것이 중요합니다. Table service를 사용하는 경우 4단계에서는 "삽입 또는 바꾸기" 작업을 사용하고, 5단계에서는 사용 중인 클라이언트 라이브러리에서 "있는 경우 삭제" 작업을 사용해야 합니다. 다른 스토리지 시스템을 사용하는 경우에는 적절한 idempotent 작업을 사용해야 합니다.
작업자 역할이 6단계를 완료하지 못한 경우에는 시간 초과 후 작업자 역할이 작업을 다시 처리할 수 있도록 준비된 큐에 메시지가 다시 나타납니다. 작업자 역할은 큐의 메시지를 읽은 횟수를 확인할 수 있으며, 필요한 경우 별도의 큐로 보내 조사할 수 있도록 "포이즌" 메시지라는 플래그를 지정할 수 있습니다. 큐 메시지 읽기 및 큐에서 제거한 횟수 확인에 대한 자세한 내용은 메시지 가져오기를 참조하세요.
테이블 및 큐 서비스의 일부 오류는 일시적 오류이므로 클라이언트 애플리케이션에 이를 처리할 수 있는 적절한 재시도 논리가 있어야 합니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 이 솔루션은 트랜잭션 격리를 제공하지 않습니다. 예를 들어 작업자 역할이 4단계와 5단계 사이에 있을 때 클라이언트가 현재 및 보관 테이블을 읽으면 일관성 없는 데이터 뷰가 표시될 수 있습니다. 결국 데이터는 일관성 있게 유지됩니다.
- 결과적 일관성을 유지하려면 4단계와 5단계가 idempotent여야 합니다.
- 여러 큐 및 작업자 역할 인스턴스를 사용하여 솔루션을 확장할 수 있습니다.
이 패턴을 사용해야 하는 경우
서로 다른 파티션 또는 테이블에 있는 엔터티 간의 결과적 일관성을 보장하려는 경우에 이 패턴을 사용합니다. 이 패턴을 확장하여 Table service와 Blob service 및 Azure가 아닌 다른 Storage 데이터 원본(예: 데이터베이스 또는 파일 시스템) 간의 작업에 대한 결과적 일관성을 유지할 수 있습니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 엔터티 그룹 트랜잭션
- 병합 또는 바꾸기
참고 항목
트랜잭션 격리가 솔루션에 중요한 경우 EGT를 사용할 수 있도록 테이블을 다시 디자인해야 합니다.
인덱스 엔터티 패턴
인덱스 엔터티를 유지 관리하여 엔터티 목록을 반환하는 효율적인 검색을 지원합니다.
컨텍스트 및 문제점
Table service는 PartitionKey 및 RowKey 값을 사용하여 엔터티를 자동으로 인덱싱합니다. 따라서 클라이언트 애플리케이션이 지점 쿼리를 사용하여 엔터티를 효율적으로 검색할 수 있습니다. 예를 들어 아래에 표시된 테이블 구조를 사용할 경우 클라이언트 애플리케이션은 부서 이름 및 직원 ID(PartitionKey 및 RowKey)를 사용하여 개별 직원 엔터티를 효율적으로 검색할 수 있습니다.

이름과 같은 고유하지 않은 다른 속성 값을 기반으로 직원 엔터티 목록을 검색할 수 있도록 하려는 경우에는 인덱스를 사용하여 직접 조회하지 말고 비효율적인 파티션 검색을 사용하여 일치하는 항목을 찾아야 합니다. 테이블 서비스에서는 보조 인덱스를 제공하지 않기 때문입니다.
솔루션
위에 표시된 엔터티 구조에서 성으로 조회할 수 있도록 하려면 직원 ID 목록을 유지 관리해야 합니다. 특정 성(예: Jones)을 가진 직원 엔터티를 검색하려면 먼저 직원 ID 목록에서 성이 Jones인 직원을 찾은 다음 해당 직원 엔터티를 검색해야 합니다. 직원 ID 목록을 저장하는 기본 옵션에는 다음 세 가지가 있습니다.
- Blob Storage 사용
- 직원 엔터티와 동일한 파티션에 인덱스 엔터티 만들기
- 별도의 파티션 또는 테이블에 인덱스 엔터티 만들기
옵션 #1: Blob Storage 사용
첫 번째 옵션의 경우 모든 고유한 성에 대한 Blob을 만들고, 각 Blob에 해당 성을 가진 직원의 PartitionKey(부서) 및 RowKey(직원 ID) 값 목록을 저장합니다. 직원을 추가하거나 삭제할 때는 관련 Blob의 내용이 직원 엔터티와 결과적으로 일관성이 있어야 합니다.
옵션 #2: 동일한 파티션에 인덱스 엔터티 만들기
두 번째 옵션의 경우 다음 데이터를 저장하는 인덱스 엔터티를 사용합니다.

EmployeeIDs 속성은 RowKey에 저장된 성을 가진 직원의 직원 ID 목록을 포함합니다.
다음 단계에서는 두 번째 옵션을 사용하는 경우 새 직원을 추가할 때 따라야 하는 프로세스를 간략하게 설명합니다. 이 예제에서는 ID가 000152이고 성이 Jones인 직원을 Sales 부서에 추가합니다.
- PartitionKey 값 "Sales"와 RowKey 값 "Jones"를 사용하여 인덱스 엔터티를 검색합니다. 이 엔터티의 ETag를 2단계에서 사용하기 위해 저장합니다.
- 새 직원 ID를 EmployeeIDs 필드의 목록에 추가하여 새 직원 엔터티(PartitionKey 값 "Sales" 및 RowKey 값 "000152")를 삽입하고 인덱스 엔터티(PartitionKey 값 "Sales" 및 RowKey 값 "Jones")를 업데이트하는 엔터티 그룹 트랜젝션(즉 배치 작업)을 만듭니다. 엔터티 그룹 트랜잭션에 대한 자세한 내용은 엔터티 그룹 트랜잭션을 참조하세요.
- 낙관적 동시성 오류(다른 사람이 인덱스 엔터티를 방금 수정한 경우)로 인해 엔터티 그룹 트랜잭션에 실패한 경우 1단계부터 다시 시작해야 합니다.
두 번째 옵션을 사용하는 경우 이와 유사한 접근 방식을 사용하여 직원을 삭제할 수 있습니다. 직원의 성을 변경하는 것은 조금 더 복잡합니다. 세 엔터티, 즉 직원 엔터티, 이전 성의 인덱스 엔터티 및 새 성의 인덱스 엔터티를 업데이트하는 엔터티 그룹 트랜잭션를 실행해야 하기 때문입니다. 낙관적 동시성을 사용하여 업데이트를 수행하는 데 사용할 수 있는 ETag 값을 검색하려면 먼저 변경하기 전에 각 엔터티를 검색해야 합니다.
다음 단계에서는 두 번째 옵션을 사용하는 경우 부서에서 지정된 성을 가진 모든 직원을 조회할 때 따라야 하는 프로세스를 간략하게 설명합니다. 이 예제에서는 Sales 부서에서 성이 Jones인 모든 직원을 조회합니다.
- PartitionKey 값 "Sales"와 RowKey 값 "Jones"를 사용하여 인덱스 엔터티를 검색합니다.
- EmployeeIDs 필드에서 직원 ID 목록을 구문 분석합니다.
- 이러한 각 직원에 대한 추가 정보(예: 전자 메일 주소)가 필요한 경우 2단계에서 가져온 직원 목록에서 PartitionKey 값 "Sales" 및 RowKey 값을 사용하여 각 직원 엔터티를 검색합니다.
옵션 3: 별도의 파티션 또는 테이블에 인덱스 엔터티 만들기
세 번째 옵션의 경우 다음 데이터를 저장하는 인덱스 엔터티를 사용합니다.

EmployeeDetails 속성에는 성이 RowKey에 저장된 직원의 직원 ID 및 부서 이름 쌍 목록이 포함됩니다.
세 번째 옵션을 사용하는 경우에는 인덱스 엔터티가 직원 엔터티와 별도의 파티션에 있기 때문에 EGT를 사용하여 일관성을 유지할 수 없습니다. 인덱스 엔터티와 직원 엔터티가 결과적으로 일관성이 있도록 해야 합니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 이 솔루션에서는 쿼리를 두 번 이상 실행하여 일치하는 엔터티를 검색해야 합니다. 즉, 인덱스 엔터티를 쿼리하여 RowKey 값 목록을 가져온 다음, 목록의 각 엔터티를 검색하는 쿼리를 실행합니다.
- 개별 엔터티의 최대 크기가 1MB인 경우 이 솔루션의 옵션 2와 옵션 3에서는 지정된 성에 대한 직원 ID 목록이 1MB를 초과하지 않는 것으로 가정합니다. 직원 ID 목록이 1MB를 초과할 가능성이 있는 경우에는 옵션 1을 사용하여 인덱스 데이터를 Blob Storage에 저장합니다.
- 옵션 2(EGT를 사용하여 직원 추가 및 삭제, 직원의 성 변경 처리)를 사용하는 경우 트랙잭션 볼륨이 지정된 파티션의 확장성 제한에 근접하는지 평가해야 합니다. 이 경우 큐를 사용하여 업데이트 요청을 처리하고, 인덱스 엔터티를 직원 엔터티와 별도의 파티션에 저장할 수 있도록 해주는 결과적으로 일관성 있는 솔루션(옵션 1 또는 옵션 3)을 고려해야 합니다.
- 이 솔루션의 옵션 2에서는 부서 내에서 성으로 조회할 것으로 가정합니다. 예를 들어 Sales 부서에서 성이 Jones인 직원 목록을 검색할 수 있습니다. 전체 조직에서 성이 Jones인 모든 직원을 조회할 수 있도록 하려면 옵션 1 또는 옵션 3을 사용합니다.
- 결과적 일관성을 제공하는 큐 기반 솔루션을 구현할 수 있습니다. 자세한 내용은 결과적으로 일관성 있는 트랜잭션 패턴을 참조하세요.
이 패턴을 사용해야 하는 경우
모두 공통된 속성 값(예: 성이 Jones인 모든 직원)을 공유하는 엔터티 세트를 조회하려는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 복합 키 패턴
- 결과적으로 일관성 있는 트랜잭션 패턴
- 엔터티 그룹 트랜잭션
- 유형이 다른 엔터티 유형 작업
비정규화 패턴
관련 데이터를 단일 엔터티에 함께 통합하여 단일 지점 쿼리로 필요한 모든 데이터를 검색할 수 있습니다.
컨텍스트 및 문제점
관계형 데이터베이스에서는 일반적으로 데이터를 정규화하여 중복을 제거함으로써 여러 테이블에서 데이터를 검색하는 쿼리를 실행합니다. Azure 테이블의 데이터를 정규화한 경우 클라이언트와 버 간에 여러 번 왕복하여 관련 데이터를 검색해야 합니다. 예를 들어 아래 표시된 테이블 구조에서 부서에 대한 세부 정보를 검색하려면 두 번 왕복해야 합니다. 즉, 관리자 ID가 포함된 부서 엔터티를 가져온 다음, 다른 요청을 통해 직원 엔터티에서 관리자의 세부 정보를 가져와야 합니다.

솔루션
두 개의 별도 엔터티에 데이터를 저장하는 대신 데이터를 비정규화하여 부서 엔터티에 관리자 세부 정보의 복사본을 유지합니다. 예시:

이러한 속성이 저장된 부서 엔터티의 경우 이제 지점 쿼리를 사용하여 부서에 대한 모든 세부 정보를 검색할 수 있습니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 일부 데이터를 두 번 저장하는 것과 관련된 약간의 비용 오버헤드가 있습니다. 그러나 일반적으로 성능 이점(스토리지 서비스에 대한 요청 수 감소로 인한 이점)이 스토리지 비용(이 비용은 부서 세부 정보를 가져오는 데 필요한 트랜잭션 수의 감소로 인해 부분적으로 상쇄됨)을 훨씬 능가합니다.
- 관리자에 대한 정보를 저장하는 두 엔터티의 일관성을 유지해야 합니다. EGT를 사용하여 여러 엔터티를 단일 원자성 트랜잭션에서 업데이트하는 방식으로 일관성 문제를 처리할 수 있습니다. 이 경우 부서 엔터티와 부서 관리자에 대한 직원 엔터티는 동일한 파티션에 저장됩니다.
이 패턴을 사용해야 하는 경우
관련 정보를 자주 조회해야 하는 경우에 이 패턴을 사용합니다. 이 패턴은 클라이언트에서 필요한 데이터를 검색하기 위해 실행해야 하는 쿼리 수를 줄여 줍니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 복합 키 패턴
- 엔터티 그룹 트랜잭션
- 유형이 다른 엔터티 유형 작업
복합 키 패턴
복합 RowKey 값을 사용하여 클라이언트에서 단일 지점 쿼리로 관련 데이터를 조회하도록 할 수 있습니다.
컨텍스트 및 문제점
관계형 데이터베이스에서는 쿼리에서 조인을 사용하여 관련 데이터 조각을 단일 쿼리의 클라이언트로 반환하는 것이 자연스러운 일입니다. 예를 들어 직원 ID를 사용하여 해당 직원에 대한 성과 및 검토 데이터가 포함된 관련 엔터티 목록을 조회할 수 있습니다.
다음 구조를 사용하여 직원 엔터티를 Table service에 저장하는 경우를 가정해 보겠습니다.

또한 매년 직원이 조직을 위해 일한 성과 및 검토와 관련된 기록 데이터를 저장하고 연도별로 이 정보에 액세스할 수 있어야 합니다. 한 가지 옵션은 다음 구조로 엔터티를 저장하는 다른 테이블을 만드는 것입니다.
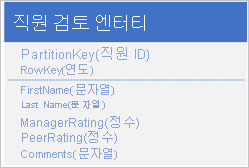
이 접근 방식을 사용하면 일부 정보(예: 이름 및 성)를 새 엔터티에 복제하여 단일 요청으로 데이터를 검색할 수 있습니다. 그러나 EGT를 사용하여 두 엔터티를 원자성으로 업데이트할 수 없기 때문에 강력한 일관성을 유지할 수 없습니다.
솔루션
다음 구조의 엔터티를 사용하여 새 엔터티 유형을 원래 테이블에 저장합니다.

이제 RowKey는 직원 ID와 검토 데이터의 연도로 구성된 복합 키이며 이 키를 사용하여 단일 엔터티에 대한 단일 요청으로 직원의 성과 및 검토 데이터를 검색할 수 있습니다.
다음 예제에서는 특정 직원(예: Sales 부서의 직원 000123)에 대한 모든 검토 데이터를 검색할 수 있는 방법을 간략하게 설명합니다.
$filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000123') and (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- RowKey 값을 쉽게 구문 분석할 수 있는 적절한 구분 기호 문자(예: 000123_2012)를 사용해야 합니다.
- 또한 이 엔터티를 동일한 직원에 대한 관련 데이터가 포함된 다른 엔터티와 동일한 파티션에 저장합니다. 이렇게 하면 EGT를 사용하여 강력한 일관성을 유지할 수 있습니다.
- 이 패턴이 적절한지 확인하기 위해 데이터를 쿼리할 빈도를 고려해야 합니다. 예를 들어 검토 데이터에는 자주 액세스하지 않고 기본 직원 데이터에는 자주 액세스하는 경우 이를 별도의 엔터티로 유지해야 합니다.
이 패턴을 사용해야 하는 경우
자주 쿼리하는 하나 이상의 관련 엔터티를 저장해야 하는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 엔터티 그룹 트랜잭션
- 유형이 다른 엔터티 유형 작업
- 결과적으로 일관성 있는 트랜잭션 패턴
로그 테일 패턴
날짜 및 시간 역순으로 정렬된 RowKey 값을 사용하여 가장 최근에 파티션에 추가된 n 개의 엔터티를 검색합니다.
컨텍스트 및 문제점
일반적인 요구 사항은 가장 최근에 생성된 엔터티(예: 직원이 제출한 가장 최근 비용 청구 10개)를 검색할 수 있는 것입니다. 테이블 쿼리는 집합에서 첫 번째 엔터티를 반환하는 $top 쿼리 작업을 지원합니다. 집합에 있는 마지막 n개의 엔터티를 반환하는 동등한 쿼리 작업은 없습니다.
솔루션
가장 최근 항목이 항상 테이블의 첫 번째 항목이 되도록 날짜/시간 역순으로 자연스럽게 정렬하는 RowKey 를 사용하여 엔터티를 정렬합니다.
예를 들어 직원이 제출한 가장 최근 비용 청구 10개를 검색하려면 현재 날짜/시간에서 파생된 역방향 틱 값을 사용하면 됩니다. 다음 C# 코드 샘플은 가장 최근 항목부터 가장 오래된 항목까지 정렬하는 RowKey 에 대한 적절한 "반전된 틱" 값을 만드는 한 가지 방법을 보여 줍니다.
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
다음 코드를 사용하여 날짜/시간 값을 되돌릴 수 있습니다.
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
테이블 쿼리는 다음과 같습니다.
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 문자열 값이 예상대로 정렬되도록 하려면 선행 0으로 역방향 틱 값을 채워야 합니다.
- 파티션 수준의 확장성 목표를 알아야 합니다. 핫스폿 파티션을 만들지 않도록 주의하세요.
이 패턴을 사용해야 하는 경우
날짜/시간 역순으로 엔터티에 액세스해야 하는 경우 또는 가장 최근에 추가된 엔터티에 액세스해야 하는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
대용량 삭제 패턴
동시 삭제할 모든 엔터티를 고유한 별도의 테이블에 저장하여 대용량 엔터티 삭제를 지원합니다. 테이블을 삭제하면 엔터티가 삭제됩니다.
컨텍스트 및 문제점
대부분의 애플리케이션은 클라이언트 애플리케이션에서 더 이상 사용할 필요가 없거나 애플리케이션이 다른 스토리지 매체에 보관한 경우 이전 데이터를 삭제합니다. 일반적으로 이러한 데이터는 날짜로 식별합니다. 예를 들어 60일이 지난 모든 로그인 요청에 대한 레코드를 삭제해야 할 수 있습니다.
한 가지 가능한 디자인은 RowKey에서 로그인 요청 날짜 및 시간을 사용하는 것입니다.

이 접근 방식을 사용하면 애플리케이션이 각 사용자에 대한 로그인 엔터티를 별도의 파티션에 삽입하고 삭제할 수 있기 때문에 파티션 핫스폿이 방지됩니다. 그러나 이 접근 방식은 엔터티 수가 많은 경우 삭제할 모든 엔터티를 식별하기 위해 먼저 테이블 검색을 수행한 다음 각 이전 엔터티를 삭제해야 하기 때문에 시간과 비용이 많이 들 수 있습니다. 여러 삭제 요청을 EGT로 일괄 처리하면 이전 엔터티를 삭제하는 데 필요한 서버 왕복 횟수를 줄일 수 있습니다.
솔루션
각 로그인 시도 날짜에 별도의 테이블을 사용합니다. 위의 엔터티 디자인을 사용하면 엔터티를 삽입할 때 핫스폿을 방지할 수 있으며, 매일 수십만 개의 개별 로그인 엔터티를 찾아서 삭제하는 대신 매일 하나의 테이블만 삭제하면 되므로(단일 스토리지 작업) 이전 엔터티 삭제가 간편해집니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 디자인이 애플리케이션에서 데이터를 사용하는 다른 방식(예: 특정 엔터티 조회, 다른 데이터와 연결 또는 집계 정보 생성)을 지원하나요?
- 디자인이 새 엔터티를 삽입할 때 핫스폿을 방지하나요?
- 테이블을 삭제한 후 동일한 테이블 이름을 다시 사용하려는 경우 지연이 발생할 수 있습니다. 항상 고유한 테이블 이름을 사용하는 것이 좋습니다.
- 새 테이블을 처음 사용할 때 Table service에서 액세스 패턴을 학습하고 노드 간에 파티션을 분산하는 동안 일부 제한이 발생할 수 있습니다. 새 테이블을 만들어야 하는 빈도를 고려해야 합니다.
이 패턴을 사용해야 하는 경우
동시에 삭제해야 하는 엔터티가 많은 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 엔터티 그룹 트랜잭션
- 엔터티 수정
데이터 계열 패턴
전체 데이터 계열을 단일 엔터티에 저장하여 요청 수를 최소화합니다.
컨텍스트 및 문제점
일반적인 시나리오에서 애플리케이션은 보통 모든 엔터티를 동시에 검색하는 데 필요한 데이터 계열을 저장합니다. 예를 들어 애플리케이션은 각 직원이 매시간 보내는 IM 메시지 수를 기록한 다음, 이 정보를 사용하여 각 사용자가 이전 24시간 동안 보낸 메시지 수를 표시할 수 있습니다. 한 가지 디자인은 각 직원에 대한 24개의 엔터티를 저장하는 것입니다.
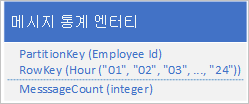
이 디자인을 사용하면 애플리케이션이 메시지 수 값을 업데이트해야 할 때마다 각 직원에 대한 엔터티를 쉽게 찾아서 업데이트할 수 있습니다. 그러나 이전 24시간 동안의 활동에 대한 차트를 그리기 위해 정보를 검색하려면 24개의 엔터티를 검색해야 합니다.
솔루션
개별 속성과 함께 다음 디자인을 사용하여 각 시간에 대한 메시지 수를 저장합니다.

이 디자인을 사용하면 병합 작업을 통해 특정 시간 동안 각 직원의 메시지 수를 업데이트할 수 있습니다. 이제 단일 엔터티에 대한 요청을 사용하여 차트를 그리는 데 필요한 모든 정보를 검색할 수 있습니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 전체 데이터 계열을 단일 엔터티에 포함할 수 없는 경우(하나의 엔터티가 최대 252개의 속성을 유지할 수 있음) Blob와 같은 다른 데이터 저장소를 사용합니다.
- 여러 클라이언트에서 동시에 엔터티를 업데이트하는 경우 ETag 를 사용하여 낙관적 동시성을 구현해야 합니다. 여러 클라이언트가 있는 경우 높은 경합이 발생할 수 있습니다.
이 패턴을 사용해야 하는 경우
개별 엔터티와 연관된 데이터 계열을 업데이트하고 검색해야 하는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 큰 엔터티 패턴
- 병합 또는 바꾸기
- 결과적으로 일관성 있는 트랜잭션 패턴 (데이터 계열을 Blob에 저장하는 경우)
넓은 엔터티 패턴
여러 실제 엔터티를 사용하여 속성이 252개가 넘는 논리적 엔터티를 저장합니다.
컨텍스트 및 문제점
개별 엔터티는 252개가 넘는 속성(필수 시스템 속성 제외)을 가질 수 없으며, 총 1MB가 넘는 데이터를 저장할 수 없습니다. 관계형 데이터베이스는 일반적으로 새 테이블을 추가하고 일대일 관계를 적용하여 행 크기에 대한 제한을 피합니다.
솔루션
Table service를 사용하면 여러 엔터티를 저장하여 252개가 넘는 속성을 가진 대규모 단일 비즈니스 개체를 나타낼 수 있습니다. 예를 들어 각 직원이 지난 365일 동안 보낸 IM 메시지 수를 저장하려는 경우 스키마가 서로 다른 두 개의 엔터티를 사용하는 다음 디자인을 사용할 수 있습니다.

서로 동기화된 상태로 유지하기 위해 두 엔터티를 모두 업데이트해야 하는 변경 내용을 적용하려는 경우 EGT를 사용할 수 있습니다. 그렇지 않으면 단일 병합 작업을 사용하여 특정 날짜의 메시지 수를 업데이트할 수 있습니다. 개별 직원에 대한 모든 데이터를 검색하려면 PartitionKey 및 RowKey 값을 둘 다 사용하는 두 가지 효율적인 요청으로 이 작업을 수행할 수 있는 엔터티를 모두 검색해야 합니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 전체 논리적 엔터티를 검색하는 데에는 적어도 두 개의 스토리지 트랜잭션이 필요합니다. 그 중 하나는 각 실제 엔터티를 검색합니다.
이 패턴을 사용해야 하는 경우
속성의 크기 또는 개수가 Table service의 개별 엔터티에 대한 제한을 초과하는 엔터티를 저장해야 하는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
- 엔터티 그룹 트랜잭션
- 병합 또는 바꾸기
큰 엔터티 패턴
Blob Storage를 사용하여 큰 속성 값을 저장합니다.
컨텍스트 및 문제점
개별 엔터티는 총 1MB가 넘는 데이터를 저장할 수 없습니다. 하나 이상의 속성에 엔터티의 총 크기가 이 값을 초과하게 만드는 값이 저장된 경우에는 Table service에 전체 엔터티를 저장할 수 없습니다.
솔루션
하나 이상의 속성에 많은 데이터가 포함되어 있어 엔터티의 크기가 1MB를 초과하는 경우 Blob service에 데이터를 저장한 다음 엔터티의 속성에 해당 Blob의 주소를 저장할 수 있습니다. 예를 들어 직원의 사진을 Blob Storage에 저장하고 해당 사진의 링크를 직원 엔터티의 사진 속성에 저장할 수 있습니다.

문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- Table service의 엔터티와 Blob service의 데이터 간에 결과적 일관성을 유지하려면 결과적으로 일관성 있는 트랜잭션 패턴 을 사용하여 엔터티를 유지합니다.
- 전체 엔터티를 검색하는 데에는 적어도 두 개의 스토리지 트랜잭션이 필요합니다. 그 중 하나는 엔터티를 검색하고, 또 하나는 Blob 데이터를 검색합니다.
이 패턴을 사용해야 하는 경우
크기가 Table service의 개별 엔터티에 대한 제한을 초과하는 엔터티를 저장해야 하는 경우에 이 패턴을 사용합니다.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
앞에 추가/뒤에 추가 안티패턴
대용량 삽입이 있는 경우 여러 파티션 간에 삽입을 분산하여 확장성을 높입니다.
컨텍스트 및 문제점
저장된 엔터티 앞 또는 뒤에 엔터티를 추가하면 일반적으로 애플리케이션에서 파티션 시퀀스의 첫 번째 또는 마지막 파티션에 새 엔터티를 추가합니다. 이 경우 지정된 시간의 모든 삽입이 동일한 파티션에서 발생하므로 테이블 서비스에서 여러 노드 간에 삽입 부하를 분산할 수 없는 핫스폿이 생성되며, 애플리케이션이 파티션의 확장성 목표에 도달하게 될 수 있습니다. 예를 들어 직원의 네트워크 및 리소스 액세스를 기록하는 애플리케이션이 있는 경우 아래 표시된 엔터티 구조에서는 트랜잭션 볼륨이 개별 파티션의 확장성 목표에 도달하면 현재 시간의 파티션이 핫스폿이 될 수 있습니다.

솔루션
다음 대체 엔터티 구조는 애플리케이션에서 이벤트를 기록할 때 특정 파티션의 핫스폿을 방지합니다.

이 예제에서는 PartitionKey와 RowKey가 복합 키입니다. PartitionKey는 부서 및 직원 ID를 모두 사용하여 여러 파티션 간에 로깅을 분산합니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
- 삽입 시 핫 파티션 생성을 효율적으로 방지하는 대체 키 구조가 클라이언트 애플리케이션의 쿼리를 지원하나요?
- 예상한 트랜잭션 볼륨이 개별 파티션에 대한 확장성 목표에 도달하고 스토리지 서비스에 의해 제한될 가능성이 있음을 의미하나요?
이 패턴을 사용해야 하는 경우
핫 파티션에 액세스할 때 트랜잭션 볼륨으로 인해 스토리지 서비스에 의한 제한이 발생할 수 있을 때는 앞에 추가/뒤에 추가 안티패턴을 사용하지 마세요.
관련 패턴 및 지침
이 패턴을 구현할 때 다음 패턴 및 지침도 관련이 있을 수 있습니다.
로그 데이터 안티패턴
일반적으로 Table service 대신 Blob service를 사용하여 로그 데이터를 저장해야 합니다.
컨텍스트 및 문제점
로그 데이터의 일반적인 사용 사례는 특정 날짜/시간 범위의 선택적 로그 항목을 검색하는 것입니다. 예를 들어 애플리케이션이 특정 날짜의 15:04에서 15:06 사이에 기록한 모든 오류 및 중요 메시지를 찾을 수 있습니다. 로그 엔터티를 저장한 파티션을 확인하는 데에는 로그 메시지의 날짜 및 시간을 사용하지 않습니다. 메시지의 날짜 및 시간을 사용하면 지정된 시간에 모든 로그 엔터티가 동일한 PartitionKey 값을 공유하기 때문에 핫 파티션이 발생합니다(앞에 추가/뒤에 추가 안티패턴 섹션 참조). 예를 들어 로그 메시지에 대한 다음 엔터티 스키마의 경우 애플리케이션이 현재 날짜 및 시간에 대한 모든 로그 메시지를 파티션에 쓰기 때문에 핫 파티션이 발생합니다.

이 예제에서 RowKey는 로그 메시지가 날짜/시간 순으로 정렬되어 저장되도록 해당 로그 메시지의 날짜 및 시간을 포함하며, 여러 로그 메시지에서 동일한 날짜 및 시간을 공유하는 경우의 메시지 ID를 포함합니다.
또 다른 접근 방식은 애플리케이션이 파티션 범위에 메시지를 쓰도록 하는 PartitionKey 를 사용하는 것입니다. 예를 들어 로그 메시지의 원본이 여러 파티션 간에 메시지를 분산할 수 있는 방법을 제공하는 경우 다음 엔터티 스키마를 사용할 수 있습니다.

그러나 이 스키마의 문제점은 특정 시간대의 모든 로그 메시지를 검색하려면 테이블의 모든 파티션을 검색해야 한다는 점입니다.
솔루션
이전 섹션에서는 Table service를 사용하여 로그 항목을 저장하려는 경우의 문제점을 설명하고 불만족스러운 두 가지 디자인을 제시했습니다. 한 가지 솔루션은 로그 메시지 작성 성능의 저하 위험으로 인해 핫 파티션이 발생했으며, 다른 솔루션은 특정 시간대의 로그 메시지를 검색하려면 테이블의 모든 파티션을 검색해야 하기 때문에 쿼리 성능이 저하되었습니다. Blob 스토리지는 이 유형의 시나리오에 보다 효율적인 솔루션을 제공하며, Azure Storage Analytics에서는 수집한 로그 데이터를 이 방법으로 저장합니다.
이 섹션에서는 일반적으로 범위로 쿼리한 데이터를 저장하는 접근 방식을 보여 주면서 Storage Analytics가 로그 데이터를 Blob 스토리지에 저장하는 방법을 간략하게 설명합니다.
Storage Analytics는 로그 메시지를 구분 기호로 분리된 형식으로 여러 Blob에 저장합니다. 구분 기호로 분리된 형식을 사용하면 클라이언트 애플리케이션에서 로그 메시지의 데이터를 쉽게 구문 분석할 수 있습니다.
Storage Analytics는 검색할 로그 메시지가 포함된 Blob를 찾을 수 있도록 Blob에 대한 명명 규칙을 사용합니다. 예를 들어 "queue/2014/07/31/1800/000001.log"라는 Blob에는 2014년 7월 31일 오후 6시 이후의 큐 서비스와 관련된 로그 메시지가 들어 있습니다. "000001"은 이것이 이 기간 동안의 첫 번째 로그 파일임을 나타냅니다. 또한 Storage Analytics는 파일에 저장된 첫 번째 및 마지막 로그 메시지의 타임스탬프를 Blob 메타데이터의 일부로 기록합니다. Blob Storage용 API를 사용하면 이름 접두사를 기반으로 컨테이너에서 Blob를 찾을 수 있습니다. 오후 6시 이후의 큐 로그 데이터가 들어 있는 모든 Blob를 찾으려면 접두사 "queue/2014/07/31/1800"을 사용하면 됩니다.
Storage Analytics는 로그 메시지를 내부적으로 버퍼한 다음 해당 Blob를 주기적으로 업데이트하거나 최신 로그 항목 집합으로 새 Blob를 만듭니다. 이는 Blob 서비스에 수행해야 하는 쓰기 수를 줄여 줍니다.
사용자 고유의 애플리케이션에서 이와 유사한 솔루션을 구현하는 경우 안정성(모든 로그 항목을 Blob Storage에 쓰기), 비용 및 확장성(애플리케이션의 업데이트 버퍼링 및 Blob Storage에 일괄 작업으로 쓰기) 간의 장단점을 관리할 방법을 고려해야 합니다.
문제 및 고려 사항
로그 데이터를 저장할 방법을 결정할 때 다음 사항을 고려하세요.
- 잠재적 핫 파티션을 방지하는 테이블 디자인을 만든 경우 로그 데이터에 효율적으로 액세스할 수 없는 경우가 있을 수 있습니다.
- 로그 데이터를 처리하기 위해 클라이언트에서 많은 레코드를 로드해야 하는 경우가 종종 있습니다.
- 로그 데이터는 구조화된 경우가 많지만 Blob Storage가 더 나은 솔루션일 수 있습니다.
구현 고려 사항
이 섹션에서는 이전 섹션에 설명된 패턴을 구현할 때 염두에 두어야 하는 몇 가지 고려 사항을 알아봅니다. 이 섹션에서는 대부분 Storage 클라이언트 라이브러리(이 문서 작성 당시 버전 4.3.0)를 사용하는 C#으로 작성된 예제를 사용합니다.
엔터티 검색
쿼리를 위한 디자인섹션에 설명된 대로 가장 효율적인 쿼리는 지점 쿼리입니다. 그러나 일부 시나리오에서는 여러 엔터티를 검색해야 할 수 있습니다. 이 섹션에서는 Storage 클라이언트 라이브러리를 사용하여 엔터티를 검색하는 몇 가지 일반적인 접근 방식을 설명합니다.
Storage 클라이언트 라이브러리를 사용하여 지점 쿼리 실행
지점 쿼리를 실행하는 가장 간편한 방법은 PartitionKey 값이 "Sales"이고 RowKey 값이 "212"인 엔터티를 검색하는 GetEntityAsync 메서드를 다음 C# 코드 조각에 표시된 대로 사용하는 것입니다.
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
이 예제에서는 검색할 엔터티의 형식이 EmployeeEntity인 것으로 가정합니다.
LINQ를 사용하여 여러 엔터티 검색
LINQ를 사용하여 Microsoft Azure Cosmos DB 테이블 표준 라이브러리로 작업할 때 Table service에서 여러 엔터티를 검색할 수 있습니다.
dotnet add package Azure.Data.Tables
아래 예제가 작동하려면 네임스페이스를 포함해야 합니다.
using System.Linq;
using Azure.Data.Tables
여러 엔터티를 검색하고 filter 절로 쿼리를 지정하여 수행합니다. 테이블 스캔을 방지하려면 항상 filter 절에 PartitionKey 값을 포함해야 하며, 가능한 경우 RowKey 값을 포함하여 테이블 및 파티션 스캔을 방지해야 합니다. 테이블 서비스에서는 filter 절에 사용할 수 있는 비교 연산자 세트(보다 큼, 보다 크거나 같음, 보다 작음, 보다 작거나 같음, 같음 및 같지 않음)가 제한되어 있습니다.
다음 예시에서 employeeTable은 TableClient 개체입니다. 다음 예시는 영업 부서(PartitionKey에 부서 이름이 저장되어 있는 것으로 가정)에서 성이 "B"(RowKey에 성이 저장되어 있는 것으로 가정)로 시작하는 모든 직원을 찾습니다.
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
더 나은 성능을 위해 쿼리에서 RowKey 및 PartitionKey를 둘 다 지정합니다.
다음 코드 샘플에서는 LINQ 구문을 사용하지 않고도 동일한 기능을 보여줍니다.
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
참고 항목
이 샘플 Query 메서드에는 세 가지 필터 조건이 포함됩니다.
쿼리에서 여러 엔터티 검색
최적의 쿼리는 PartitionKey 값과 RowKey 값을 기반으로 개별 엔터티를 반환합니다. 그러나 일부 시나리오에서는 동일한 파티션 또는 여러 파티션에서 여러 엔터티를 반환해야 하는 요구 사항이 있을 수 있습니다.
이러한 시나리오에서는 항상 애플리케이션의 성능을 철저히 테스트해야 합니다.
테이블 서비스에 대한 쿼리는 한 번에 최대 1,000개의 엔터티를 반환할 수 있으며, 최대 5초 동안 실행할 수 있습니다. 결과 집합에 1,000개가 넘는 엔터티가 포함되거나, 쿼리가 5초 이내에 완료되지 않거나, 쿼리가 파티션 경계를 넘은 경우 Table 서비스는 클라이언트 애플리케이션이 다음 엔터티 집합을 요청할 수 있도록 연속 토큰을 반환합니다. 연속 토큰의 작동 방식에 대한 자세한 내용은 쿼리 제한 시간 및 페이지 번호 매김을 참조하세요.
Azure 테이블 클라이언트 라이브러리를 사용하는 경우 테이블 서비스에서 엔터티를 반환할 때 연속 토큰을 자동으로 처리할 수 있습니다. 테이블 클라이언트 라이브러리를 사용하는 다음 C# 코드 예제는 테이블 서비스가 응답으로 반환하는 연속 토큰을 자동으로 처리합니다.
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
페이지당 반환되는 최대 엔터티 수를 지정할 수도 있습니다. 다음 예제에서는 maxPerPage로 엔티티를 쿼리하는 방법을 보여 줍니다.
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
고급 시나리오에서는 코드가 다음 페이지를 가져올 때 정확하게 제어할 수 있도록 서비스에서 반환된 연속 토큰을 저장할 수 있습니다. 다음 예제에서는 토큰을 가져와서 페이지를 매긴 결과에 적용하는 방법에 대한 기본 시나리오를 보여줍니다.
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
연속 토큰을 명시적으로 사용하면 애플리케이션이 데이터의 다음 세그먼트를 검색하는 시점을 제어할 수 있습니다. 예를 들어 클라이언트 애플리케이션이 테이블에 저장된 엔터티의 페이징을 지원하는 경우, 사용자는 쿼리에서 검색된 일부 엔터티를 페이징하지 않도록 결정하여 현재 세그먼트의 모든 엔터티에 대한 페이징을 완료했을 때 애플리케이션이 연속 토큰만을 사용하여 다음 세그먼트를 검색하도록 할 수 있습니다. 이 접근 방식에는 몇 가지 이점이 있습니다.
- Table service에서 검색할 데이터의 양을 제한하고 네트워크를 통해 이동할 수 있습니다.
- .NET에서 비동기 IO를 수행할 수 있습니다.
- 연속 토큰을 영구 스토리지에 직렬화하여 애플리케이션의 작동이 중단된 경우에도 작업을 계속할 수 있습니다.
참고 항목
일반적으로 연속 토큰은 1,000개(이보다 적을 수도 있음)의 엔터티가 포함된 세그먼트를 반환합니다. 이는 수행을 사용해 쿼리에서 반환되는 항목 수를 제한하여 조회 조건과 일치하는 첫 번째 n개의 엔터티를 반환하도록 한 경우에도 마찬가지입니다. Table service는 나머지 엔터티를 검색할 수 있도록 연속 토큰과 함께 n개 미만의 엔터티가 포함된 세그먼트를 반환할 수 있습니다.
서버 쪽 프로젝션
단일 엔터티는 최대 255개의 속성을 가질 수 있으며, 크기가 최대 1MB일 수 있습니다. 테이블을 쿼리하여 엔터티를 검색할 때 필요 없는 속성을 제외하여 데이터가 불필요하게 전송되는 것을 방지할 수 있습니다(이 경우 대기 시간이 단축되고 비용이 절감됨). 서버 쪽 프로젝션을 사용하여 필요한 속성만 전송할 수 있습니다. 다음 예제에서는 쿼리에서 선택한 엔터티에서 Email 속성만(PartitionKey, RowKey, Timestamp 및 ETag와 함께) 검색합니다.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
RowKey 값은 검색할 속성 목록에 포함되지 않은 경우에도 사용할 수 있습니다.
엔터티 수정
스토리지 클라이언트 라이브러리를 사용하면 엔터티를 삽입, 삭제 및 업데이트하여 테이블 서비스에 저장된 엔터티를 수정할 수 있습니다. EGT를 사용하면 여러 삽입, 업데이트 및 삭제 작업을 일괄적으로 수행하여 필요한 왕복 횟수를 줄이고 솔루션의 성능을 향상시킬 수 있습니다.
스토리지 클라이언트 라이브러리에서 EGT를 실행할 때 발생하는 예외에는 일반적으로 일괄 처리가 실패하도록 하는 엔터티의 인덱스가 포함됩니다. 이는 EGT를 사용하는 코드를 디버그할 때 유용합니다.
디자인이 클라이언트 애플리케이션에서 동시성 및 업데이트 작업을 처리하는 방법에 어떤 영향을 미치는지도 고려해야 합니다.
동시성 관리
기본적으로 클라이언트가 Table service에서 이러한 확인을 강제로 무시하도록 할 수도 있지만 Table service는 개별 엔터티 수준에서 삽입, 병합 및 삭제 작업에 대한 낙관적 동시성 확인을 구현합니다. 테이블 서비스에서 동시성을 관리하는 방법에 대한 자세한 내용은 Microsoft Azure Storage에서 동시성 관리를 참조하세요.
병합 또는 바꾸기
TableOperation 클래스의 바꾸기 메서드는 항상 Table service의 전체 엔터티를 바꿉니다. 저장된 엔터티에 존재하는 속성을 포함하지 않으면 요청 시 저장된 엔터티에서 해당 속성이 제거됩니다. 저장된 엔터티에서 속성을 명시적으로 제거하지 않은 한 모든 속성을 요청에 포함해야 합니다.
엔터티를 업데이트할 때 TableOperation 클래스의 병합 메서드를 사용하여 Table service로 보낼 데이터의 양을 줄일 수 있습니다. 병합 메서드는 저장된 엔터티의 모든 속성을 요청에 포함된 엔터티의 속성 값으로 바꾸지만 요청에 포함되지 않은 속성은 저장된 엔터티에 그대로 유지합니다. 이는 엔터티가 많을 때 요청에서 소수의 속성만 업데이트해야 하는 경우에 유용합니다.
참고 항목
엔터티가 존재하지 않으면 바꾸기 및 병합 메서드가 실패합니다. 또는 엔터티가 존재하지 않는 경우 새 엔터티를 만드는 InsertOrReplace 및 InsertOrMerge 메서드를 사용할 수 있습니다.
유형이 다른 엔터티 유형 작업
Table service는 스키마가 없는 테이블 저장소이며 이는 단일 테이블이 뛰어난 디자인 유연성을 제공하는 여러 형식의 엔터티를 저장할 수 있다는 것을 의미합니다. 다음 예제에서는 직원 및 부서 엔터티를 모두 저장하는 테이블을 보여 줍니다.
| PartitionKey | RowKey | 타임스탬프 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
각 엔터티에 여전히 PartitionKey, RowKey 및 Timestamp 값이 있어야 하지만 다른 속성 집합은 원하는 대로 포함할 수 있습니다. 또한 해당 정보를 저장하도록 선택하지 않은 경우 엔터티 유형을 나타내는 항목이 없습니다. 엔터티 유형을 식별하는 두 가지 옵션이 있습니다.
- RowKey(또는 PartitionKey) 앞에 엔터티 형식을 추가합니다. RowKey 값을 예로 들어 EMPLOYEE_000123 또는 DEPARTMENT_SALES하십시오.
- 아래 표에 표시된 대로 별도의 속성을 사용하여 엔터티 유형을 기록합니다.
| PartitionKey | RowKey | 타임스탬프 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
RowKey앞에 엔터티 유형을 추가하는 첫 번째 옵션은 유형이 서로 다른 두 엔터티의 키 값이 동일할 수 있는 경우에 유용합니다. 또한 이 옵션은 동일한 유형의 엔터티를 파티션에서 그룹화합니다.
이 아티클에 설명된 기술은 특히 관계 모델링 아티클의 이 가이드 앞부분에 나오는 상속 관계 설명과 관련이 있습니다.
참고 항목
클라이언트 애플리케이션이 POCO 개체를 구체화하고 여러 버전에서 작동하도록 하려면 엔터티 유형 값에 버전 번호를 포함해야 합니다.
이 섹션의 나머지 부분에서는 동일한 테이블의 여러 엔터티 유형으로 작업하는 데 용이한 스토리지 클라이언트 라이브러리의 몇 가지 기능에 대해 설명합니다.
서로 다른 엔터티 유형 검색
테이블 클라이언트 라이브러리를 사용하는 경우 여러 엔터티 유형으로 작업하는 세 가지 옵션이 있습니다.
특정 RowKey 및 PartitionKey 값과 함께 저장된 엔터티의 유형을 알고 있는 경우에는 유형이 EmployeeEntity인 엔터티를 검색하는 이전 두 예제(Storage 클라이언트 라이브러리를 사용하여 지점 쿼리 실행 및 LINQ를 사용하여 여러 엔터티 검색)와 같이 엔터티를 검색할 때 엔터티 유형을 지정할 수 있습니다.
두 번째 옵션은 구체적 POCO 엔터티 형식 대신 TableEntity 형식(속성 모음)을 사용하는 것입니다(이 옵션을 사용하면 엔터티를 .NET 형식으로 직렬화 및 역직렬화할 필요가 없으므로 성능이 향상될 수도 있습니다). 다음 C# 코드는 잠재적으로 테이블에서 다양한 형식의 여러 엔터티를 검색하지만 모든 엔터티를 TableEntity 인스턴스로 반환합니다. 그런 다음 EntityType 속성을 사용하여 각 엔터티의 형식을 확인합니다.
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
다른 속성을 검색하려면 TableEntity 클래스의 엔터티에서 GetString 메서드를 사용해야 합니다.
서로 다른 엔터티 유형 수정
엔터티를 삭제할 때는 엔터티 유형을 몰라도 되지만 엔터티를 삽입할 때는 항상 엔터티 유형을 알아야 합니다. 그러나 TableEntity 형식을 사용하면 형식을 모르는 경우에도 POCO 엔터티 클래스를 사용하지 않고 엔터티를 업데이트할 수 있습니다. 다음 코드 샘플에서는 단일 엔터티를 검색하여 업데이트하기 전에 EmployeeCount 속성이 있는지 확인합니다.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
공유 액세스 서명을 사용하여 액세스 제어
코드에 스토리지 계정 키가 포함되지 않아도 SAS(공유 액세스 서명) 토큰을 사용하여 클라이언트 애플리케이션에서 테이블 엔터티를 수정(및 쿼리)할 수 있게 합니다. 일반적으로 애플리케이션응에서 SAS를 사용할 경우 세 가지 주요 이점이 있습니다.
- 해당 디바이스가 Table service의 엔터티에 액세스하고 수정할 수 있도록 하기 위해 보안되지 않는 플랫폼(예: 모바일 디바이스)에 스토리지 계정 키를 배포할 필요가 없습니다.
- 웹 및 작업자 역할이 엔터티를 관리하면서 수행하는 일부 작업을 최종 사용자 컴퓨터 및 모바일 디바이스와 같은 클라이언트 디바이스로 오프로드할 수 있습니다.
- 제약적이고 시간 제한된 권한 집합(예: 특정 리소스에 대한 읽기 전용 액세스 허용)을 클라이언트에 할당할 수 있습니다.
Table service에서 SAS 토큰 사용에 대한 자세한 내용은 SAS(공유 액세스 서명) 사용을 참조하세요.
그러나 클라이언트 애플리케이션에 테이블 서비스의 엔터티에 대한 권한을 부여하는 SAS 토큰을 여전히 생성해야 합니다. 스토리지 계정 키에 대한 보안 액세스가 있는 환경에서 이렇게 해야 합니다. 일반적으로 웹 또는 작업자 역할을 사용하여 SAS 토큰을 생성하고 엔터티에 액세스해야 하는 클라이언트 애플리케이션에 이를 제공합니다. SAS 토큰을 생성하여 클라이언트에 제공하는 작업과 관련된 오버헤드가 여전히 있으므로 특히 대용량 시나리오에서 이 오버헤드를 줄일 수 있는 최상의 방법을 고려해야 합니다.
테이블에 있는 엔터티의 하위 집합에 대한 액세스 권한을 부여하는 SAS 토큰을 생성할 수 있습니다. 기본적으로 전체 테이블에 대한 SAS 토큰을 만들지만 이 SAS 토큰이 PartitionKey 값 범위 또는 PartitionKey 및 RowKey 값 범위에 대한 액세스 권한을 부여하도록 지정할 수도 있습니다. 각 사용자의 SAS 토큰이 Table service에 있는 해당 사용자의 고유 엔터티에 대한 액세스만 허용하도록 시스템의 개별 사용자에 대한 SAS 토큰을 생성할 수 있습니다.
비동기 및 병렬 작업
여러 파티션에 요청을 분산하는 경우 비동기 또는 병렬 쿼리를 사용하여 처리량 및 클라이언트 응답성을 향상시킬 수 있습니다. 예를 들어 둘 이상의 작업자 역할 인스턴스에서 테이블에 병렬로 액세스하는 경우가 있을 수 있습니다. 특정 파티션 집합을 담당하는 개별 작업자 역할을 두거나, 여러 작업자 역할 인스턴스에서 각각 테이블의 모든 파티션에 액세스할 수 있도록 할 수 있습니다.
클라이언트 인스턴스 내에서 스토리지 작업을 비동기식으로 실행하여 처리량을 향상시킬 수 있습니다. Storage 클라이언트 라이브러리를 사용하면 비동기 쿼리 및 수정 사항을 쉽게 작성할 수 있습니다. 예를 들어 다음 C# 코드와 같이 파티션의 모든 엔터티를 검색하는 동기 메서드로 시작할 수 있습니다.
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
그런 다음 쿼리가 비동기식으로 실행되도록 아래와 같이 이 코드를 쉽게 수정할 수 있습니다.
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
이 비동기 예제에서는 동기 버전에서 다음 사항이 변경된 것을 확인할 수 있습니다.
- 이제 메서드 서명은 async 수정자를 포함하고 Task 인스턴스를 반환합니다.
- Query 메서드를 호출하여 결과를 검색하는 대신, 이제 메서드에서 QueryAsync 메서드를 호출하고 await 한정자를 사용하여 결과를 비동기식으로 검색합니다.
클라이언트 애플리케이션은(서로 다른 department 매개 변수 값)이 메서드를 여러 번 호출할 수 있으며, 각 쿼리는 별도의 스레드에서 실행됩니다.
엔터티를 비동기식으로 삽입, 업데이트 및 삭제할 수도 있습니다. 다음 C# 예제에서는 직원 엔터티를 삽입하거나 바꾸는 간단한 동기 메서드를 보여 줍니다.
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
업데이트가 비동기식으로 실행되도록 아래와 같이 이 코드를 쉽게 수정할 수 있습니다.
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
이 비동기 예제에서는 동기 버전에서 다음 사항이 변경된 것을 확인할 수 있습니다.
- 이제 메서드 서명은 async 수정자를 포함하고 Task 인스턴스를 반환합니다.
- Execute 메서드를 호출하여 엔터티를 업데이트하는 대신, 이제 메서드에서 ExecuteAsync 메서드를 호출하고 await 한정자를 사용하여 결과를 비동기식으로 검색합니다.
클라이언트 애플리케이션은 이와 같은 여러 비동기 메서드를 호출할 수 있으며, 각 메서드 호출은 별도의 스레드에서 실행됩니다.