레이크 데이터베이스
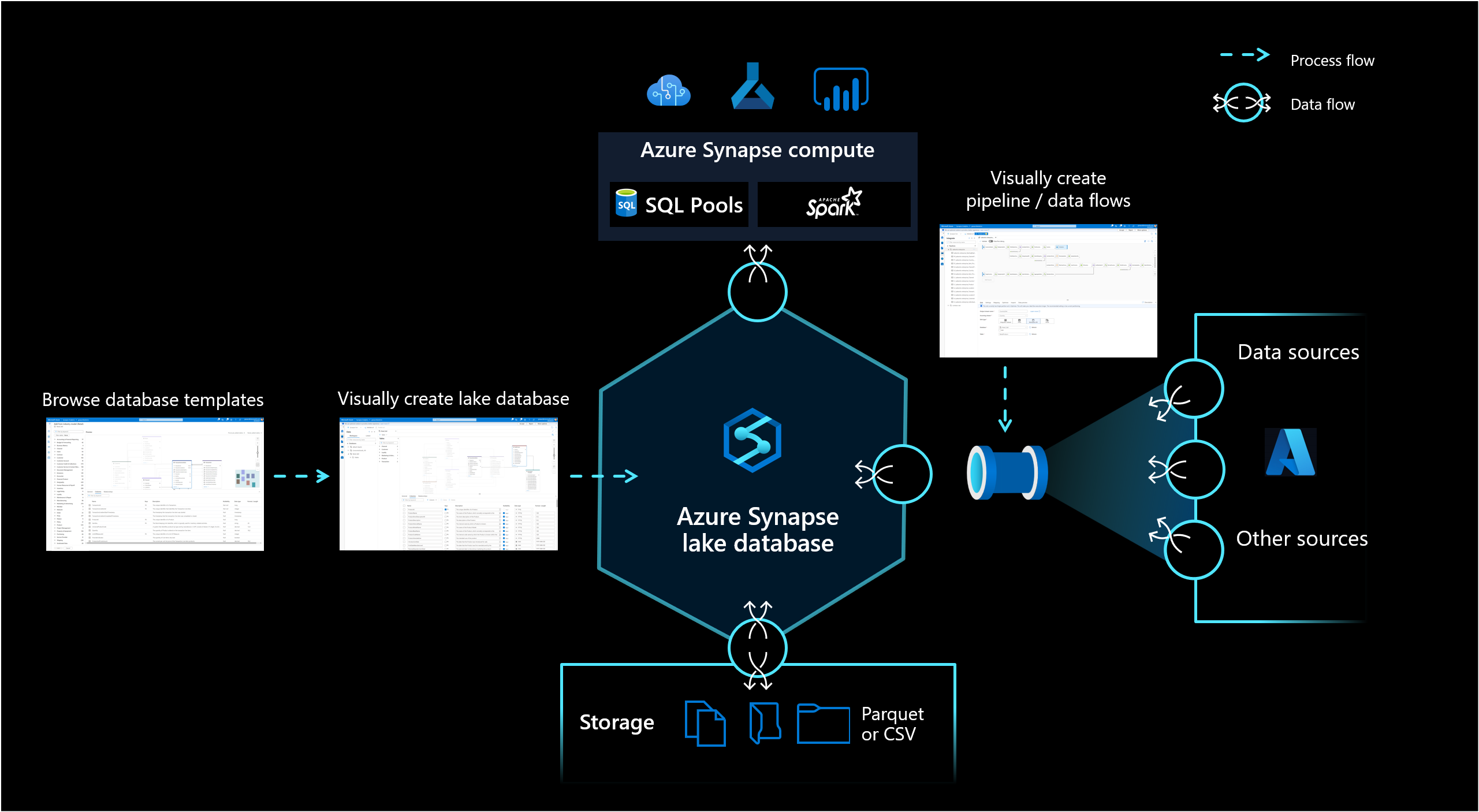
Azure Synapse Analytics의 레이크 데이터베이스를 사용하면 고객은 데이터베이스 디자인, 저장된 데이터에 대한 메타 정보를 확인하고 데이터를 저장해야 하는 방법 및 위치를 설명할 수 있습니다. 레이크 데이터베이스는 데이터가 구조화되는 방식을 이해하기 어려운 오늘날의 데이터 레이크 문제를 해결합니다.
데이터베이스 디자이너
Synapse Studio의 새 데이터베이스 디자이너를 사용하면 레이크 데이터베이스에 대한 데이터 모델을 만들고 추가 정보를 추가할 수 있습니다. 모든 엔터티 및 특성을 설명하여 엔터티뿐만 아니라 관계도 포함하는 모델에 대한 자세한 정보를 제공할 수 있습니다. 특히 관계를 모델링할 수 없다는 점은 데이터 레이크에서 상호 작용에 대한 도전 과제였습니다. 이 문제는 이제 레이크가 아닌 데이터베이스에서 사용할 수 있도록 지원하는 통합 디자이너를 통해 해결되었습니다. 또한 모델에 설명 및 가능한 데모 값을 추가할 수 있으므로 나중에 모델과 상호 작용하는 사용자가 데이터를 보다 잘 이해하는 데 필요한 정보를 얻을 수 있습니다.
데이터 저장소
레이크 데이터베이스는 Azure Storage 계정의 데이터 레이크를 사용하여 데이터베이스의 데이터를 저장합니다. 데이터는 Parquet, Delta 또는 CSV 형식으로 저장할 수 있으며, 다양한 설정을 사용하여 스토리지를 최적화할 수 있습니다. 모든 레이크 데이터베이스는 연결된 서비스를 사용하여 루트 데이터 폴더의 위치를 정의합니다. 모든 엔터티에 대해 기본적으로 데이터 레이크의 이 데이터베이스 폴더 내에 별도의 폴더가 만들어집니다. 기본적으로 레이크 데이터베이스 내의 모든 테이블은 동일한 형식을 사용하지만 요청된 경우 엔터티별로 데이터의 형식과 위치를 변경할 수 있습니다.
참고 항목
레이크 데이터베이스를 게시해도 Spark 또는 SQL에서 데이터를 쿼리하는 데 필요한 기본 구조나 스키마는 만들어지지 않습니다. 게시한 후 파이프라인을 사용하여 레이크 데이터베이스에 데이터를 로드하여 쿼리를 시작합니다.
현재 레이크 데이터베이스에 대한 델타 형식 지원은 Synapse Studio에서 지원되지 않습니다.
스토리지와 Synapse 간의 레이크 데이터베이스 개체 동기화는 단방향입니다. Synapse Studio의 데이터베이스 디자이너를 사용하여 레이크 데이터베이스 개체의 생성 또는 스키마 수정을 수행해야 합니다. 대신 Spark에서 또는 스토리지에서 직접 변경하면 레이크 데이터베이스의 정의가 동기화되지 않게 됩니다. 이런 일이 발생하면 데이터베이스 디자이너에서 이전 레이크 데이터베이스 정의를 볼 수 있습니다. 레이크 데이터베이스를 다시 동기화하려면 데이터베이스 디자이너에서 이러한 변경 내용을 복제하고 게시해야 합니다.
데이터베이스 컴퓨팅
레이크 데이터베이스는 Synapse SQL 서버리스 SQL 풀 및 Apache Spark에 노출되며 사용자에게 컴퓨팅에서 스토리지를 분리하는 기능을 제공합니다. 레이크 데이터베이스와 연결된 메타데이터를 사용하면 다양한 여러 컴퓨팅 엔진이 통합된 환경을 쉽게 제공할 뿐만 아니라 원래 데이터 레이크에서 지원되지 않는 추가 정보(예: 관계)를 사용할 수 있습니다.
다음 단계
아래 링크를 사용하여 데이터베이스 디자이너 기능을 계속 탐색합니다.