타일 사용
타일링을 사용하여 앱의 가속을 최대화할 수 있습니다. 타일링은 스레드를 동일한 사각형 하위 집합 또는 타일로 나눕니다. 적절한 타일 크기 및 바둑판식 알고리즘을 사용하는 경우 C++ AMP 코드에서 더 많은 가속을 얻을 수 있습니다. 타일링의 기본 구성 요소는 다음과 같습니다.
tile_static변수. 타일링의 주요 이점은 액세스로tile_static인한 성능 향상입니다. 메모리의tile_static데이터에 대한 액세스는 전역 공간(array또는array_view개체)의 데이터에 액세스하는 것보다 훨씬 빠를 수 있습니다. 변수의tile_static인스턴스는 각 타일에 대해 만들어지고 타일의 모든 스레드는 변수에 액세스할 수 있습니다. 일반적인 타일식 알고리즘에서 데이터는 전역 메모리에서 한 번 메모리로tile_static복사된 다음 메모리에서tile_static여러 번 액세스됩니다.tile_barrier::wait 메서드입니다. 동일한 타일의 모든 스레드가 호출에 도달할 때까지 현재 스레드 실행을 일시 중단하는
tile_barrier::wait호출tile_barrier::wait입니다. 스레드가 실행되는 순서를 보장할 수 없으며, 모든 스레드가 호출에 도달할 때까지 타일의 스레드가 호출tile_barrier::wait을 지나서 실행되지 않습니다. 즉, 메서드를tile_barrier::wait사용하여 스레드 단위가 아닌 타일 단위로 작업을 수행할 수 있습니다. 일반적인 타일링 알고리즘에는 전체 타일에 대한 메모리를tile_static초기화한 후 호출하는 코드가 있습니다tile_barrier::wait. 다음tile_barrier::wait코드에는 모든 값에 액세스해야 하는 계산이tile_static포함됩니다.로컬 및 전역 인덱싱. 전체
array_view또는array개체를 기준으로 하는 스레드의 인덱스와 타일을 기준으로 하는 인덱스에 액세스할 수 있습니다. 로컬 인덱스 사용으로 코드를 더 쉽게 읽고 디버그할 수 있습니다. 일반적으로 로컬 인덱싱을 사용하여 변수에 액세스tile_static하고 전역 인덱싱을 사용하여 액세스 및array_view변수에 액세스array합니다.tiled_extent 클래스 및 tiled_index 클래스입니다. 호출에서
tiled_extent개체 대신extent개체를parallel_for_each사용합니다. 호출에서tiled_index개체 대신index개체를parallel_for_each사용합니다.
타일링을 활용하려면 알고리즘이 컴퓨팅 작업을 타일로 분할한 다음기본 타일 데이터를 변수에 tile_static 복사하여 더 빠르게 액세스해야 합니다.
전역, 타일 및 로컬 인덱스의 예
참고 항목
C++ AMP 헤더는 Visual Studio 2022 버전 17.0부터 더 이상 사용되지 않습니다.
AMP 헤더를 포함하면 빌드 오류가 생성됩니다. 경고를 무음으로 표시하기 위해 AMP 헤더를 포함하기 전에 정의 _SILENCE_AMP_DEPRECATION_WARNINGS 합니다.
다음 다이어그램은 2x3 타일로 정렬된 데이터의 8x9 행렬을 나타냅니다.
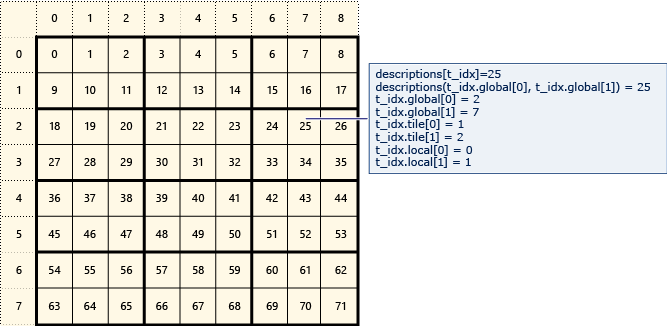
다음 예제에서는 이 타일 행렬의 전역, 타일 및 로컬 인덱스를 표시합니다. array_view 개체는 형식Description의 요소를 사용하여 만들어집니다. 행렬 Description 에 있는 요소의 전역, 타일 및 로컬 인덱스를 보유합니다. 각 요소의 전역, 타일 및 로컬 인덱스의 값을 설정하는 호출 parallel_for_each 의 코드입니다. 출력은 구조체의 값을 Description 표시합니다.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
예제의 기본 작업은 개체 정의 array_view 및 호출에 있습니다parallel_for_each.
구조체의
Description벡터는 8x9array_view개체로 복사됩니다.이
parallel_for_each메서드는 컴퓨팅처럼 개체를 사용하여 호출tiled_extent됩니다기본. 개체는tiled_extent변수의 메서드를extent::tile()호출하여 생성됩니다descriptions. 호출의 형식 매개 변수입니다. 2x3 타일이 만들어지도록extent::tile()<2,3>지정합니다. 따라서 8x9 행렬은 타일 12개, 행 4개, 열 3개로 바둑판식으로 표시됩니다.개체
parallel_for_each(t_idx)를 인덱스tiled_index<2,3>로 사용하여 메서드를 호출합니다. 인덱스의 형식 매개 변수(t_idx)는 컴퓨팅 수행기본(descriptions.extent.tile< 2, 3>())의 형식 매개 변수와 일치해야 합니다.각 스레드가 실행되면 인덱
t_idx스는 스레드가 있는 타일(속성) 및 타일(tiled_index::tiletiled_index::local속성) 내의 스레드 위치에 대한 정보를 반환합니다.
타일 동기화 - tile_static 및 tile_barrier::wait
이전 예제에서는 타일 레이아웃과 인덱스를 보여 주지만 그 자체로는 유용하지 않습니다. 타일이 알고리즘 및 악용 tile_static 변수에 필수적인 경우 타일링이 유용합니다. 타일의 모든 스레드는 변수에 tile_static 액세스할 수 있으므로 호출 tile_barrier::wait 은 변수에 대한 액세스를 동기화하는 tile_static 데 사용됩니다. 타일의 모든 스레드가 변수에 tile_static 액세스할 수 있지만 타일에서 스레드의 실행 순서는 보장되지 않습니다. 다음 예제에서는 변수와 tile_barrier::wait 메서드를 사용하여 tile_static 각 타일의 평균 값을 계산하는 방법을 보여 줍니다. 예제를 이해하기 위한 키는 다음과 같습니다.
rawData는 8x8 행렬에 저장됩니다.
타일 크기는 2x2입니다. 이렇게 하면 4x4 그리드의 타일이 만들어지고 개체를 사용하여
array평균을 4x4 행렬에 저장할 수 있습니다. AMP 제한 함수에서 참조로 캡처할 수 있는 형식의 수는 제한되어 있습니다.array클래스는 그 중 하나입니다.행렬 크기 및 샘플 크기는 문을 사용하여
#define정의됩니다. 왜냐하면 형식 매개 변수array는 <array_viewextenta0/>이고tiled_index상수 값이어야 하기 때문입니다. 선언을 사용할const int static수도 있습니다. 추가적인 이점으로 샘플 크기를 변경하여 평균 4x4 타일을 계산하는 것은 간단합니다.각 타일에
tile_static대해 2x2 배열의 float 값이 선언됩니다. 선언은 모든 스레드의 코드 경로에 있지만 행렬의 각 타일에 대해 하나의 배열만 생성됩니다.각 타일의 값을 배열에 복사하는 코드 줄이
tile_static있습니다. 각 스레드에 대해 값이 배열에 복사된 후에는 호출로 인해 스레드에서 실행이tile_barrier::wait중지됩니다.타일의 모든 스레드가 장벽에 도달하면 평균을 계산할 수 있습니다. 코드는 모든 스레드에 대해 실행되므로 한 스레드
if의 평균만 계산하는 문이 있습니다. 평균은 평균 변수에 저장됩니다. 장벽은 기본적으로 루프를 사용할 수 있는 것처럼 타일별로 계산을 제어하는 구문입니다for.변수의
averages데이터는 개체이므로array호스트에 다시 복사해야 합니다. 이 예제에서는 벡터 변환 연산자를 사용합니다.전체 예제에서는 SAMPLESIZE를 4로 변경할 수 있으며 코드는 다른 변경 없이 올바르게 실행됩니다.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
경합 조건
다음과 같이 각 스레드에 대해 해당 변수를 만들고 total 증가시키는 변수를 만들려고 tile_static 할 수 있습니다.
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
이 방법 tile_static 의 첫 번째 문제는 변수에 이니셜라이저를 사용할 수 없다는 것입니다. 두 번째 문제는 타일의 모든 스레드가 특정 순서 없이 변수에 액세스할 수 있기 때문에 할당 total에 경합 상태가 있다는 것입니다. 다음과 같이 각 장벽에서 하나의 스레드만 합계에 액세스할 수 있도록 알고리즘을 프로그래밍할 수 있습니다. 그러나 이 솔루션은 확장할 수 없습니다.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
메모리 펜스
동기화해야 하는 두 가지 종류의 메모리 액세스(전역 메모리 액세스 및 tile_static 메모리 액세스)가 있습니다. 개체는 concurrency::array 전역 메모리만 할당합니다. A는 concurrency::array_view 생성된 방법에 따라 전역 메모리, tile_static 메모리 또는 둘 다를 참조할 수 있습니다. 동기화해야 하는 두 가지 종류의 메모리가 있습니다.
전역 메모리
tile_static
메모리 펜스는 스레드 타일의 다른 스레드에서 메모리 액세스를 사용할 수 있고 프로그램 순서에 따라 메모리 액세스가 실행되도록 합니다. 이를 위해 컴파일러와 프로세서는 펜스 전체에서 읽기 및 쓰기를 다시 정렬하지 않습니다. C++ AMP에서는 다음 방법 중 하나를 호출하여 메모리 펜스를 만듭니다.
tile_barrier::wait 메서드: 전역 및
tile_static메모리 둘 다 주위에 울타리를 만듭니다.tile_barrier::wait_with_all_memory_fence 메서드: 전역 및
tile_static메모리 둘 다 주위에 울타리를 만듭니다.tile_barrier::wait_with_global_memory_fence 메서드: 전역 메모리 주위에 펜스를 만듭니다.
tile_barrier::wait_with_tile_static_memory_fence 메서드: 메모리 주위에만
tile_static펜스를 만듭니다.
필요한 특정 펜스를 호출하면 앱의 성능이 향상될 수 있습니다. 장벽 형식은 컴파일러 및 하드웨어가 문을 다시 정렬하는 방법에 영향을 줍니다. 예를 들어 전역 메모리 펜스를 사용하는 경우 전역 메모리 액세스에만 적용되므로 컴파일러와 하드웨어는 펜스 양쪽의 변수에 읽기 및 쓰기를 다시 정렬할 tile_static 수 있습니다.
다음 예제에서 장벽은 쓰기를 변수에 동기화합니다tileValuestile_static. 이 예제 tile_barrier::wait_with_tile_static_memory_fence 에서는 대신 호출됩니다 tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
참고 항목
C++ AMP(C++ Accelerated Massive Parallelism)
tile_static 키워드