데이터 통합을 위해 각 테이블의 중복을 제거합니다.
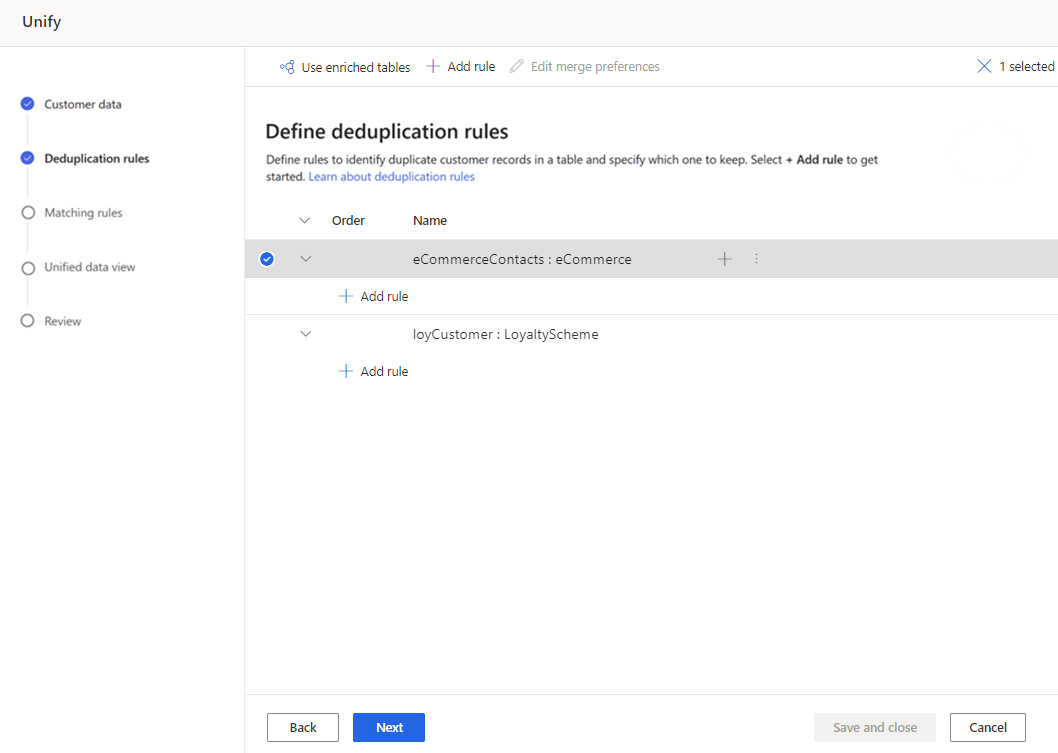
통합의 중복 제거 규칙 단계에서는 원본 테이블에서 고객에 대한 중복 레코드를 찾아서 제거하여 각 고객이 각 테이블의 단일 행으로 표시되도록 합니다. 각 테이블은 특정 고객에 대한 레코드를 식별하는 규칙을 사용하여 별도로 중복 제거됩니다.
규칙은 순서대로 처리됩니다. 테이블의 모든 레코드에 대해 모든 규칙이 실행되면 공통 행을 공유하는 일치 그룹이 단일 일치 그룹으로 결합됩니다.
중복 제거 규칙 정의
좋은 규칙은 고유한 고객을 식별합니다. 데이터를 고려합니다. 이메일 등의 필드를 기반으로 고객을 식별하는 것만으로도 충분할 수 있습니다. 그러나 이메일을 공유하는 고객을 구별하려는 경우 이메일 + 이름과 일치하는 두 가지 조건이 있는 규칙을 선택할 수 있습니다. 자세한 내용은 중복 제거 모범 사례를 참조하세요.
중복 제거 규칙 페이지에서 테이블을 선택하고 규칙 추가를 선택하여 중복 제거 규칙을 정의합니다.
팁
통합 결과를 개선하는 데 도움이 되도록 데이터 원본 수준에서 테이블을 보강한 경우 페이지 상단에서 보강 테이블 사용을 선택하세요. 자세한 내용은 데이터 원본 보강을 참조하세요.
규칙 추가 창에서 다음 정보를 입력합니다.
필드 선택: 중복 여부를 확인하려는 테이블의 사용 가능한 필드 목록에서 선택합니다. 모든 단일 고객에게 고유한 필드를 선택하십시오. 예를 들어 이메일 주소 또는 이름, 도시 및 전화번호의 조합입니다.
정규화: 열에 대한 정규화 옵션 을 선택합니다. 정규화는 일치 단계에만 영향을 미치며 데이터는 변경하지 않습니다.
- 숫자: 숫자를 나타내는 유니코드 기호를 간단한 숫자로 변환합니다.
- 기호: !"#$%&'()*+,-./:;<=>?와 같은 기호 및 특수 문자를 제거합니다. @[]^_`{|}~. 예를 들어 Head&Shoulder는 HeadShoulder가 됩니다.
- 텍스트를 소문자로: 대문자를 소문자로 변환합니다. "ALL CAPS and Title Case"는 "all caps and title case"가 됩니다.
- 유형(전화번호, 이름, 주소, 소속): 이름, 직위, 전화번호, 주소를 표준화합니다.
- 유니코드를 ASCII로: 유니코드 문자를 해당하는 ASCII 문자로 변환합니다. 예를 들어, 악센트가 있는 ề는 e 문자로 변환됩니다.
- 공백: 모든 공백을 제거합니다. Hello World는 HelloWorld가 됩니다.
- 별칭 매핑: 항상 정확히 일치하는 것으로 간주되어야 하는 문자열을 나타내기 위해 사용자 정의 문자열 쌍 목록을 업로드할 수 있습니다.
- 사용자 정의 우회: 일치해서는 안 되는 문자열을 나타내기 위해 사용자 정의 문자열 목록을 업로드할 수 있습니다.
정밀도: 정밀도 수준을 설정합니다. 정밀도는 정확한 일치와 퍼지 일치에 사용되며 닫기 두 문자열이 일치하는 것으로 간주되기 위해 필요한 방식을 결정합니다.
- 기본: 최저(30%), 보통(60%), 최고(80%), 및 정확(100%)에서 선택합니다. 정확히 일치를 선택하여 100% 일치하는 레코드만 일치시킵니다.
- 사용자 지정: 레코드가 일치해야 하는 비율을 설정합니다. 시스템은이 임계값을 통과하는 일치 레코드만 일치시킵니다.
이름: 규칙의 이름입니다.
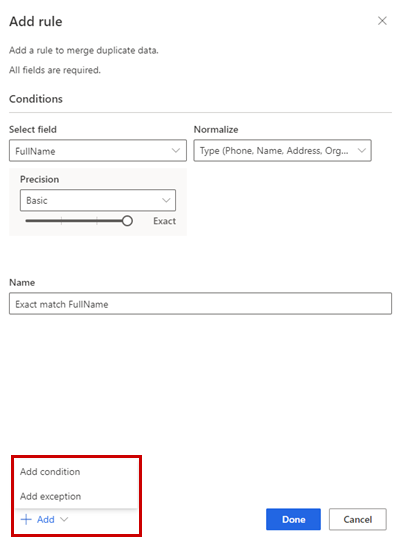
선택적으로 추가>조건 추가를 선택하여 규칙에 더 많은 조건을 추가합니다. 조건은 논리 AND 연산자로 연결되므로 모든 조건이 충족되는 경우에만 실행됩니다.
선택적으로, 추가>예외 추가를 규칙에 예외 추가합니다. 예외는 가양성 및 가음성의 드문 경우를 해결하는 데 사용됩니다.
완료를 선택하여 규칙을 생성합니다.
선택적으로 더 많은 규칙을 추가할 수 있습니다.
테이블을 선택한 다음 병합 기본 설정 편집을 선택합니다.
환경 설정 병합 창에서:
중복이 발견된 경우 보관할 레코드를 결정하려면 세 가지 옵션 중 하나를 선택합니다.
- 가장 많이 채워진: 가장 많이 채워진 열이 있는 레코드를 승자 레코드로 식별합니다. 기본 병합 옵션입니다.
- 가장 최근: 최신순으로 승자 기록을 식별합니다. 최신 성을 정의하려면 날짜 또는 숫자 필드가 필요합니다.
- 가장 최근: 최신순으로 승자 기록을 식별합니다. 최신성을 정의하려면 날짜 또는 숫자 필드가 필요합니다.
동점일 경우 승자 기록은 MAX(PK) 또는 더 큰 기본 키 값을 가진 레코드입니다.
선택적으로 테이블의 개별 열에 대한 병합 기본 설정을 정의하려면 창 하단에서 고급을 선택합니다. 예를 들어 가장 최근의 이메일과 다른 기록에서 가장 완전한 주소를 유지하도록 선택할 수 있습니다. 테이블을 확장하여 모든 열을 보고 개별 열에 사용할 옵션을 정의합니다. 최근성 기반 옵션을 선택하는 경우 최근성을 정의하는 날짜/시간 필드도 지정해야 합니다.
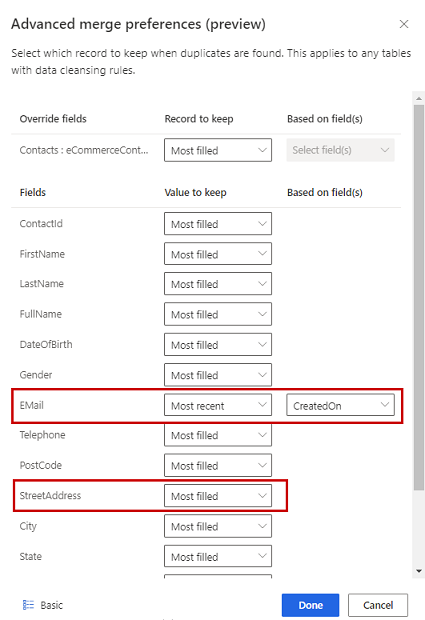
완료를 선택하여 병합 기본 설정을 적용합니다.
중복 제거 규칙 및 병합 기본 설정을 정의한 후 다음을 선택합니다.
