AI로 유사 고객 찾기(프리뷰)
[이 문서는 시험판 문서이며 변경될 수 있습니다.]
인공 지능을 사용하여 고객 기반에서 유사한 고객을 찾으십시오. 이 기능을 사용하려면 하나 이상의 세그먼트를 만들어야 합니다. 기존 세그먼트의 기준을 확장하면 해당 세그먼트와 유사한 고객을 찾을 수 있습니다.
노트
유사한 고객 찾기에서는 자동화된 수단을 사용하여 데이터를 평가하고 해당 데이터를 기반으로 예측합니다. 따라서 이 용어는 다양한 개인 정보 보호법 및 규정에 정의되어 있으므로 프로파일링 방법으로 사용할 수 있습니다. 고객이 데이터 처리를 위해 이 기능을 사용하는 경우 해당 법률 또는 규정이 적용될 수 있습니다. 귀하는 예측을 포함한 Dynamics 365 Customer Insights - Data 사용이 개인 정보 보호, 개인 데이터, 생체 인식 데이터, 데이터 보호 및 통신 기밀과 관련된 법률을 포함하여 모든 관련 법률 및 규정을 준수하는지 확인할 책임이 있습니다.
유사 고객 찾기
인사이트>세그먼트로 이동하고 새 세그먼트의 기반이 될 세그먼트를 선택합니다. 그것이 원본 세그먼트입니다.
유사 고객 찾기를 선택합니다.
새 세그먼트의 제안된 이름을 검토하고 필요한 경우 변경하십시오.
선택적으로 새 세그먼트에 태그를 추가합니다.
새 세그먼트를 정의하는 필드를 검토하십시오. 이 필드는 시스템이 원본 세그먼트와 유사한 고객을 찾으려고 하는 기초를 정의합니다. 시스템은 기본적으로 권장 필드를 선택합니다. 필요한 경우 필드를 더 추가합니다. 모델 성능을 크게 저하시킬 수 있는 필드는 자동으로 제외됩니다.
- StringType, BooleanType, CharType, LongType, IntType, DoubleType, FloatType, ShortType과 같은 데이터 유형이 있는 필드
- 카디널리티(필드의 요소 수)가 2보다 작거나 30보다 큰 필드
모든 고객 또는 새 세그먼트에서 다른 세그먼트의 고객만 포함하려면 선택하세요.
기본적으로 시스템은 출력에 대상 그룹 크기의 20%만 포함하도록 제안합니다. 필요에 따라 이 임계값을 편집하십시오. 임계값을 높이면 정밀도가 떨어집니다.
유사한 특성을 가진 고객 외에 소스 세그먼트의 구성원 포함 확인란을 선택하여 소스 세그먼트에 고객을 포함합니다.
페이지 하단에서 실행을 선택해 데이터 집합을 분석하는 이진 분류 작업(기계 학습의 방법)을 시작합니다.
유사한 세그먼트 보기
유사한 세그먼트를 처리한 후 새로운 세그먼트가 확장 유형과 함께 인사이트>세그먼트 페이지에 표시됩니다.
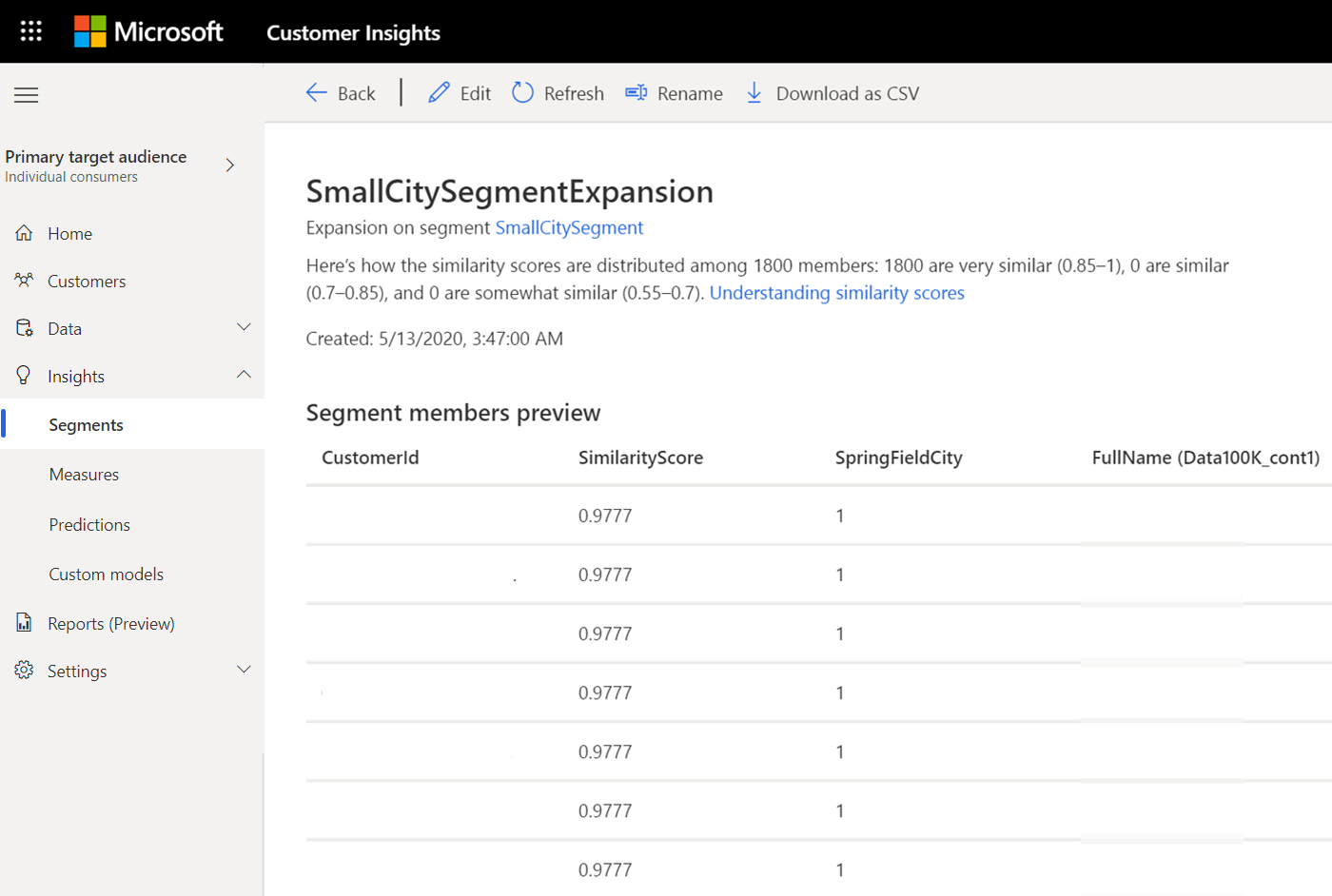
보기를 선택하여 세그먼트 구성원 프리뷰에서 유사성 점수 및 유사성 점숫값 전반의 결과 분포를 확인합니다.
유사한 세그먼트 관리
다른 세그먼트와 마찬가지로 유사한 세그먼트로 작업 및 관리할 수 있습니다. 예를 들어, 세그먼트를 내보내거나 측정값을 작성하십시오.
유사한 세그먼트를 편집, 새로 고침, 이름 변경, 다운로드, 삭제합니다. 유사한 세그먼트를 수정하면 데이터가 다시 처리됩니다. 이전에 생성된 세그먼트는 새로 고친 데이터로 업데이트됩니다.
유사성 점수 정보
이진 분류 기계 학습 모델은 유사한 세그먼트의 고객에게 점수를 할당합니다. 점수는 원본세그먼트의 고객과의 유사성을 기반으로 합니다.
- 0.55 미만의 유사성 점수는 시스템이 원본 세그먼트의 고객과 비슷하지 않다고 분류한 고객입니다.
- 0.55 – 0.7 사이의 유사성 점수는 다소 유사로 분류됩니다.
- 0.7 – 0.85 사이의 유사성 점수는 유사로 분류됩니다.
- 0.85 – 1 사이의 유사성 점수는 시스템이 매우 유사로 분류한 고객입니다.
유사성 점수가 0.4 미만인 고객은 모델 출력에 포함되지 않습니다. 시스템은 이를 원본 세그먼트와 비슷한 것으로 간주하지 않습니다.