고객 평생 가치(CLV) 예측
개별 활성 고객이 정의된 미래 기간 동안 비즈니스에 가져올 잠재적 가치(수익)를 예측합니다. 이 예측은 다음을 수행하는 데 도움이 됩니다.
- 가치 높은 고객 고객을 식별하고 해당 인사이트를 처리합니다.
- 잠재 가치를 기반으로 전략적인 고객 세그먼트를 만들어 타겟팅된 판매, 마케팅 및 지원 노력을 통해 개인화된 캠페인을 실행합니다.
- 고객 가치를 높이는 기능에 집중하여 제품 개발을 지원합니다.
- 영업 또는 마케팅 전략을 최적화하고 고객 지원을 위해 더 정확하게 예산을 할당합니다.
- 로열티 또는 보상 프로그램을 통해 가치 높은 고객 고객을 인식하고 보상합니다.
비즈니스에 CLV가 의미하는 바를 판단하십시오. 당사는 트랜잭션 기반 CLV 예측을 지원합니다. 고객의 예측 가치는 비즈니스 트랜잭션을 기반으로 합니다. 다양한 입력 선호 설정으로 여러 모델을 만들고 모델 결과를 비교하여 비즈니스 요구에 가장 적합한 모델 시나리오를 확인하십시오.
팁
샘플 데이터 고객 평생 가치(CLV) 예측 샘플 가이드를 사용하여 CLV 예측을 시도하십시오.
필수 조건
- 최소한 기여자 권한이 있어야 합니다
- 원하는 예측 기간 내에 최소 1,000개의 고객 프로필
- 고객 식별자, 트랜잭션을 개별 고객과 일치시키는 고유 식별자
- 최소 1년의 거래 내역, 가급적이면 2~3년의 거래 내역이 필요합니다. 이상적으로, 고객 ID당 최소 2~3건의 트랜잭션, 여러 날짜에 걸친 트랜잭션이 좋습니다. 트랜잭션 기록에는 다음이 포함되어야 합니다.
- 트랜잭션 ID: 각 트랜잭션의 고유 식별자
- 트랜잭션 날짜: 각 트랜잭션의 날짜 또는 타임 스탬프
- 트랜잭션 amount: 각 트랜잭션의 금전적 가치(예: 수익 또는 이익률)
- 반품에 할당된 레이블: 트랜잭션이 반환인지 여부를 나타내는 부울 참/거짓 값
- 제품 ID: 트랜잭션에 관련된 제품의 제품 ID
- 고객 활동에 대한 데이터:
- 기본 키: 활동의 고유 식별자
- 타임스탬프: 기본 키로 식별된 이벤트 날짜 및 시간
- 이벤트(활동 이름): 사용하려는 이벤트의 이름
- 세부 정보(금액 또는 가치): 고객 활동에 대한 세부 정보
- 추가 데이터의 예:
- 웹 활동: 웹 사이트 방문 기록 또는 이메일 기록
- 로열티 활동: 로열티 보상 포인트 적립 및 사용 기록
- 고객 서비스 로그: 서비스 요청, 불만 또는 반품 기록
- 고객 프로필 정보
- 필수 필드에서 누락된 값이 20% 미만
노트
하나의 트랜잭션 기록 테이블만 구성할 수 있습니다. 구매 또는 트랜잭션 테이블이 여러 개인 경우 데이터 수집 전에 Power Query에서 이를 결합합니다.
고객 평생 가치 예측 만들기
언제든지 임시 저장을 선택하여 예측을 초안으로 저장합니다. 초안 예측은 내 예측 탭에 표시됩니다.
인사이트>예측으로 이동합니다.
만들기 탭의 고객 평생 가치 타일에서 모델 사용을 선택합니다.
시작하기를 선택합니다.
이 모델 이름 및 출력 테이블 이름을 지정하여 다른 모델이나 테이블과 구별합니다.
다음을 선택합니다.
모델 선호 설정 정의
예측 기간을 설정하여 CLV를 예측하려는 미래를 정의합니다. 기본적으로 단위는 월로 설정됩니다.
팁
설정된 기간 동안 CLV를 정확하게 예측하려면 비교 가능한 기간의 과거 데이터가 필요합니다. 예를 들어, 향후 12개월 동안 CLV를 예측하려면 최소 18~24개월의 과거 데이터가 있어야 합니다.
고객이 활성으로 간주되는 트랜잭션이 하나 이상 있어야 하는 시간 프레임을 설정하십시오. 이 모델은 활성 고객에 대한 CLV만 예측합니다.
- 모델이 구매 간격을 계산하도록 함(권장): 모델은 데이터를 분석하고 과거 구매를 기반으로 기간을 결정합니다.
- 수동으로 간격 설정: 활성 고객을 정의하는 기간입니다.
고가치 고객의 백분위수를 정의합니다.
- 모델 계산(권장): 모델은 80/20 규칙을 사용합니다. 과거 기간 동안 비즈니스에 대한 누적 수익의 80%에 기여한 고객의 비율이 가치 높은 고객 고객으로 간주됩니다. 일반적으로 30-40% 미만의 고객이 누적 수익의 80%에 기여합니다. 그러나 이 숫자는 비즈니스 및 산업에 따라 다를 수 있습니다.
- 상위 활성 고객 비율: 가치가 높은 고객에 대한 특정 백분위수. 예를 들어 25를 입력하여 고가치 고객을 미래의 유료 고객 중 상위 25%로 정의합니다.
비즈니스에서 가치 높은 고객 고객을 다른 방식으로 정의한다면, 듣고 싶으니 알려주십시오.
다음을 선택합니다.
필수 데이터 추가
고객 트랜잭션 기록에 대해 데이터 추가를 선택합니다.
거래 기록이 포함된 의미 활동 유형 SalesOrder 또는 SalesOrderLine를 선택합니다. 활동이 설정되지 않은 경우 여기를 선택하여 생성합니다.
활동에서, 활동이 생성될 때 활동 특성이 의미적으로 매핑된 경우 계산에 집중할 특정 특성 또는 테이블을 선택합니다. 매핑이 발생하지 않은 경우 편집을 선택하고 데이터를 의미 매핑합니다.
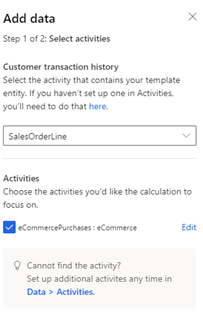
다음을 선택하고 이 모델에 필요한 속성을 검토합니다.
저장을 선택합니다.
활동을 더 추가하거나 다음을 선택합니다.
활동 데이터 추가(선택 사항)
주요 고객 상호 작용(웹, 고객 서비스 및 이벤트 로그)을 반영하는 데이터는 트랜잭션 레코드에 컨텍스트를 추가합니다. 고객 활동 데이터에서 더 많은 패턴을 발견하면 예측의 정확성을 높일 수 있습니다.
추가 활동 데이터로 모델 인사이트 향상에서 데이터 추가를 선택합니다.
추가하는 고객 활동 유형과 일치하는 활동 유형을 선택하십시오. 활동이 설정되지 않은 경우 여기를 선택하여 생성합니다.
활동에서, 활동이 생성될 때 활동 특성이 매핑된 경우 계산에 집중할 특정 특성 또는 테이블을 선택합니다. 매핑이 발생하지 않은 경우 편집을 선택하고 데이터를 매핑합니다.
다음을 선택하고 이 모델에 필요한 속성을 검토합니다.
저장을 선택합니다.
다음을 선택합니다.
선택적 고객 데이터 추가 또는 다음을 선택하고 업데이트 일정 설정으로 이동합니다.
고객 데이터 추가(선택 사항)
모델에 대한 입력값으로 포함할 일반적으로 사용되는 18개의 고객 프로필 특성 중에서 선택합니다. 이러한 특성은 비즈니스 사용 사례에서 더 개인 설정되고 관련성이 있으며 실행 가능한 모델 결과로 이어질 수 있습니다.
예: Contoso Coffee는 새로운 에스프레소 머신 출시와 관련된 개인 설정된 제안을 통해 가치가 높은 고객을 대상으로 고객 평생 가치를 예측하려고 합니다. Contoso는 CLV 모델을 사용하고 18개의 고객 프로필 특성을 모두 추가하여 가장 가치 있는 고객에게 영향을 미치는 요소를 확인합니다. 이 회사는 고객 위치가 이러한 고객에게 가장 영향력 있는 요소라는 사실을 알게 되었습니다. 이 정보를 바탕으로 에스프레소 머신 출시를 위한 지역 행사를 조직하고 지역 공급업체와 협력하여 개인 설정된 제안과 행사에서의 특별한 경험을 제공하게 되었습니다. 이 정보가 없었다면 Contoso는 일반적인 마케팅 이메일만 보냈을 것이고 가치가 높은 고객의 이 지역 세그먼트를 개인 설정할 기회를 놓쳤을 것입니다.
추가 고객 데이터로 모델 인사이트 더욱 향상에서 데이터 추가를 선택합니다.
테이블에 고객 : CustomerInsights를 선택하여 고객 특성 데이터에 매핑되는 통합 고객 프로필을 선택합니다. 고객 ID의 경우 System.Customer.CustomerId를 선택합니다.
통합 고객 프로필에서 데이터를 사용할 수 있는 경우 더 많은 필드를 매핑합니다.
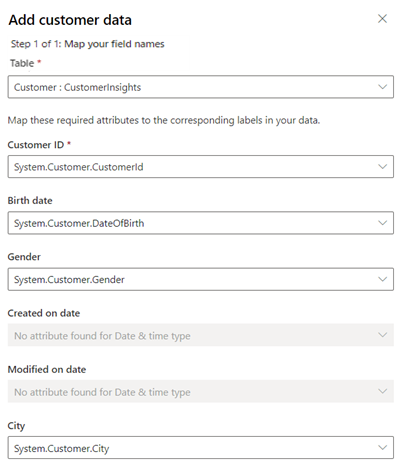
저장을 선택합니다.
다음을 선택합니다.
업데이트 일정 설정
최신 데이터를 기반으로 모델을 재교육할 빈도를 선택합니다. 이 설정은 새 데이터가 수집될 때 예측의 정확성을 업데이트하는 데 중요합니다. 대부분의 비즈니스는 한 달에 한 번 재교육을 받고 예측의 정확도를 높일 수 있습니다.
다음을 선택합니다.
모델 구성 검토 및 실행
검토 및 실행 단계는 구성 요약을 보여주고 예측을 만들기 전에 변경할 수 있는 기회를 제공합니다.
검토하고 변경할 단계에서 편집을 선택합니다.
선택에 만족하면 저장 및 실행을 선택하여 모델 실행을 시작합니다. 완료를 선택합니다. 예측이 생성되는 동안 내 예측 탭이 표시됩니다. 예측에 사용된 데이터 양에 따라 프로세스를 완료하는 데 몇 시간이 걸릴 수 있습니다.
팁
작업 및 프로세스에 대한 상태가 있습니다. 대부분의 프로세스는 데이터 원본 및 데이터 프로파일링 새로 고침과 같은 다른 업스트림 프로세스에 의존합니다.
상태를 선택하여 진행 세부 정보 창을 열고 작업 진행 상황을 봅니다. 작업을 취소하려면 창 하단에서 작업 취소를 선택합니다.
각 작업 아래에서 처리 시간, 마지막 처리 날짜, 작업 또는 프로세스와 관련된 해당 오류 및 경고와 같은 자세한 진행 정보를 보려면 세부 정보 보기를 선택합니다. 시스템의 다른 프로세스를 보려면 패널 하단에서 시스템 상태 보기를 선택합니다.
예측 결과 보기
인사이트>예측으로 이동합니다.
내 예측 탭에서 보려는 예측을 선택합니다.
결과 페이지에는 세 가지 기본 데이터 섹션이 있습니다.
학습 모델 성능: A, B 또는 C 등급은 예측의 성능을 나타내며 출력 테이블에 저장된 결과를 사용하기로 결정하는 데 도움이 될 수 있습니다.
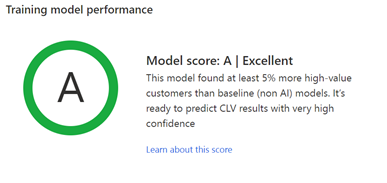
시스템은 기준 모델과 비교하여 가치가 높은 고객을 예측하는 데 AI 모델이 어떻게 수행되었는지 평가합니다.
등급은 다음 규칙에 따라 결정됩니다.
- 모델이 기준 모델에 비해 가치 높은 고객 고객을 5% 이상 정확하게 예측한 경우 A입니다.
- 모델이 기준 모델에 비해 가치 높은 고객 고객을 0~5% 더 정확하게 예측한 경우 B입니다.
- 모델이 기준 모델에 비해 더 적은 수의 가치 높은 고객 고객을 정확하게 예측한 경우 C입니다.
이 점수에 대해 알아보기를 선택하여 AI 모델 성능 및 기준 모델에 대한 추가 세부 정보를 표시하는 모델 평가 창을 엽니다. 기본 모델 성능 메트릭과 최종 모델 성능 등급이 어떻게 도출되었는지 더 잘 이해하는 데 도움이 됩니다. 기준 모델은 AI 기반이 아닌 접근 방식을 사용하여 주로 고객이 구매한 기록을 기반으로 고객 평생 가치를 계산합니다.
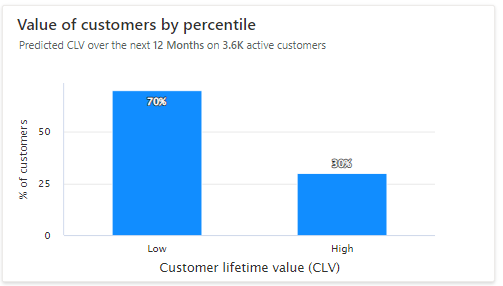
백분위수별 고객 가치: 가치가 낮은 고객과 가치가 높은 고객을 차트로 표시합니다. 히스토그램의 막대 위로 마우스를 가져가면 각 그룹의 고객 수와 해당 그룹의 평균 CLV를 볼 수 있습니다. 선택적으로 CLV 예측을 기반으로 고객 세그먼트를 생성합니다.
가장 영향력 있는 요소: AI 모델에 제공된 입력 데이터를 기반으로 CLV 예측을 생성할 때 다양한 요소를 고려합니다. 각 요인은 모형이 생성하는 집계된 예측에 대해 중요도가 계산됩니다. 이러한 요소를 사용하여 예측 결과를 검증합니다. 이러한 요소는 또한 모든 고객의 CLV 예측에 기여한 가장 영향력 있는 요소에 대한 더 많은 인사이트를 제공합니다.

점수에 대해 알아보기
기준 모델이 CLV를 계산하는 데 사용하는 표준 공식:
각 고객의 CLV = 활성 고객 창에서 고객이 구매한 월평균 구매 * CLV 예측 기간의 개월 수 * 모든 고객의 전체 재방문 주기율
AI 모델은 두 가지 모델 성능 메트릭을 기반으로 기준 모델과 비교됩니다.
가치 높은 고객 예측 성공률
기준 모델과 비교하여 AI 모델을 사용한 가치 높은 고객 예측의 차이점을 확인하십시오. 예를 들어 84%의 성공률은 교육 데이터의 모든 가치 높은 고객 중에서 AI 모델이 84%를 정확하게 포착할 수 있음을 의미합니다. 그런 다음 이 성공률을 기준 모델의 성공률과 비교하여 상대적 변화를 보고합니다. 이 값은 모델에 등급을 지정하는 데 사용됩니다.
오류 메트릭
미래 값 예측의 오류 측면에서 모델의 전체 성능을 확인합니다. 이 오류를 평가하기 위해 전체 평균 제곱근 오차(RMSE) 메트릭을 사용합니다. RMSE는 정량적 데이터를 예측할 때 모델의 오류를 측정하는 표준 방법입니다. AI 모델의 RMSE는 기준 모델의 RMSE와 비교되고 상대적 차이가 보고됩니다.
AI 모델은 고객이 비즈니스에 제공하는 가치에 따라 정확한 고객 순위를 우선으로 합니다. 따라서 가치 높은 고객 예측의 성공률만이 최종 모델 등급을 도출하는 데 사용됩니다. RMSE 메트릭은 이상값에 민감합니다. 매우 높은 구매 값을 가진 고객 비율이 적은 시나리오에서는 전체 RMSE 메트릭이 모델 성능에 대한 전체 그림을 제공하지 못할 수 있습니다.