기계 학습 모델의 결과
이 문서에서는 ML(기계 학습) 모델의 혼동 행렬, 분류 문제 및 정확도에 대해 설명합니다. ML 예측 결과의 정확성에 대한 이해를 높이는 것이 목적입니다. 대상 대상 그룹에는 데이터 과학에 대한 지식과 기술을 구축하려는 엔지니어, 분석가 및 관리자가 포함됩니다.
혼동 행렬
감독된 ML 문제가 일련의 기록 데이터에 대해 훈련된 후 훈련 프로세스에서 보류된 데이터를 사용하여 테스트됩니다. 이러한 방식으로 훈련된 모델의 예측을 실제 값과 비교할 수 있습니다. 혼동 행렬은 분류 문제가 얼마나 성공적인지, 어디에서 실수를 범하는지(즉, "혼란"되는 위치) 평가하는 수단을 제공합니다.
예를 들어, 목표는 일부 신체적 및 행동적 특성을 기반으로 애완동물이 개인지 고양이인지 예측하는 것입니다. 30마리의 개와 20마리의 고양이가 포함된 테스트 데이터 세트가 있는 경우 혼동 행렬은 다음 그림과 유사할 수 있습니다.

녹색 셀의 숫자는 정확한 예측을 나타냅니다. 보시다시피, 모델은 실제 고양이의 더 높은 비율을 정확하게 예측했습니다. 모델의 전체 정확도는 계산하기 쉽습니다. 이 경우 42 ÷ 50 또는 0.84입니다.
혼동 행렬의 다중 클래스 분류기
혼동 행렬에 대한 대부분의 논의는 앞의 예에서와 같이 이진 분류기에 초점을 맞춥니다. 이 경우는 민감도 및 재현율과 같은 다른 메트릭을 고려할 수 있는 특별한 경우입니다.
다음으로 세 가지 상태가 있는 재무 시나리오에 대한 분류 문제를 고려할 것입니다. 이 모델은 고객 송장이 제시간에 지불될 것인지, 늦게 지불될 것인지 또는 매우 늦게 지불될 것인지 예측합니다. 예를 들어, 테스트 송장 100개 중 50개는 정시에 지불되고 35개는 늦게 지불되고 15개는 매우 늦게 지불됩니다. 이 경우 모델은 다음 그림과 유사한 혼동 행렬을 생성할 수 있습니다.
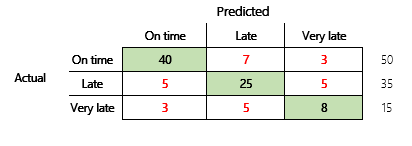 ]
]
혼동 행렬은 단순한 정확도 메트릭보다 훨씬 더 많은 정보를 제공합니다. 하지만 그래도 비교적 이해하기 쉽습니다. 혼동 행렬은 출력 클래스가 유사한 개수를 갖는 균형 잡힌 데이터 세트가 있는지 여부를 알려줍니다. 다중 클래스 시나리오의 경우 고객 지불에 대한 앞의 예에서와 같이 출력 클래스가 서수일 때 예측이 얼마나 멀리 떨어져 있는지 알려줍니다.
모델 정확도
다양한 정확도 메트릭은 모델 품질을 정량화하는 이점이 있습니다.
정확도는 이해하기 쉬운 메트릭이므로 다른 사람, 특히 데이터 과학자가 아닌 모델 사용자에게 모델을 설명하기 위한 좋은 출발점입니다. 모델의 정확도를 이해하기 위해 통계에 대한 이해가 필요하지 않습니다. 혼동 행렬을 사용할 수 있는 경우 모델 성능에 대한 추가 인사이트를 제공합니다.
그러나 보다 철저한 이해를 위해서는 정확성과 관련된 몇 가지 문제에 유의해야 합니다. 메트릭의 유용성은 문제의 컨텍스트에 따라 다릅니다. 모델 성능과 관련하여 자주 제기되는 질문은 "모델이 얼마나 좋은가?"입니다. 그러나 이 질문에 대한 답이 반드시 간단한 것은 아닙니다. 다음 혼동 행렬(모델 2)을 고려하십시오.
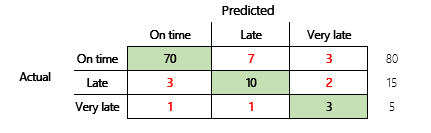
빠른 계산으로 이 모델의 정확도가 (70 + 10 + 3) ÷ 100 또는 0.83임을 알 수 있습니다. 표면적으로 이 결과는 정확도가 0.73인 이전의 다중 클래스 모델(모델 1)의 결과보다 나은 것처럼 보입니다. 하지만 더 나은가요?
이 질문을 해결하려면 단순 추측의 정확도를 고려하십시오. 분류 문제의 경우 간단한 추측은 항상 가장 일반적인 클래스를 예측합니다. 모델 1의 경우 해당 추측은 "정시" 이며 정확도는 0.50이 될 것입니다. 모델 2의 추측도 "정시"가 될 것이며, 정확도는 0.80이 될 것입니다. 모델 1은 단순 추측에서 0.73 – 0.50 = 0.23 향상되지만 모델 2는 단순 추측에서 0.83 – 0.80 = 0.03 향상되기 때문에 모델 1은 정확도가 낮지만 더 나은 모델입니다. 계산에 따르면 모델 품질을 효과적으로 평가하려면 정확도 값보다 더 많은 컨텍스트가 필요합니다.
또 다른 측면은 주목할 가치가 있습니다. 환자의 질병을 감지하는 데 의료 검사를 사용하는 시나리오를 고려하십시오. 이 문제는 양성 결과가 환자에게 질병이 있음을 나타내는 이진 분류 문제입니다. 이 시나리오에서는 다음 오류의 영향을 고려해야 합니다.
- 가양성은 검사에서 환자에게 질병이 있다고 표시되지만 환자는 실제로 질병에 걸리지 않습니다.
- 가음성은 검사에서 환자에게 질병이 없다고 표시되지만 환자는 실제로는 병에 걸렸습니다.
분명히 두 가지 유형의 오류 모두 바람직하지 않지만 어느 것이 더 나쁠까요? 다시 말하지만, 상황에 따라 다릅니다. 빠른 치료가 필요한 생명을 위협하는 질병의 경우 가음성의 최소화(추후 추가 검사)가 우선시됩니다. 덜 위험한 다른 상황에서는 모델 작성자가 대신 가양성을 최소화할 수 있습니다. 어쨌든 합리적인 결론은 모델의 품질을 효과적으로 결정하려면 정확도 메트릭이 제공하는 것보다 더 많은 정보가 있어야 한다는 것입니다.
추천 제품
정확도는 통계에 익숙하지 않은 도메인 전문가와 의사 소통하기 위한 중요한 도구입니다. 그러나 정보를 유용하게 만들려면 정확도 값과 함께 추가 컨텍스트를 제공하는 것이 중요합니다.
지불 예측 시나리오의 경우 다양한 지불 행동의 요소를 포함하는 ML 모델의 대상을 설정할 수 있습니다. 목표는 모델이 오답의 수를 최소 50% 줄여서 단순 추측을 개선해야 한다는 것입니다. 즉, 단순 추측의 정확도와 100% 사이의 차이를 분할하는 목표 정확도를 원합니다.
다음 표에는 이 문서의 혼동 행렬에 대한 이 원칙이 요약되어 있습니다.
| 모델 | 단순 추측 | 대상 | 모델 정확도 | 목표가 달성되었습니까? |
|---|---|---|---|---|
| 모델 1 | 0.50 | 0.75 | 0.73 | 거의. 이 모델은 추측을 크게 향상시킵니다. |
| 모델 2 | 0.80 | 0.90 | 0.83 | 번호 개선이 필요합니다. |
분류 F1 정확도
이 문서의 마지막 고려 사항은 F1 정확도라고 하는 분류 ML 성능의 고급 측정값입니다.
F1 정확도를 정의하기 전에 정밀도와 재현율이라는 두 가지 추가 메트릭을 소개해야 합니다. 정밀도는 양성으로 지정된 총 예측 수 중 올바르게 할당된 수를 나타냅니다. 이 메트릭은 양성 예측값이라고도 합니다. 재현율은 올바르게 예측된 실제 양성 사례의 총 수입니다. 이 메트릭은 민감도라고도 합니다.
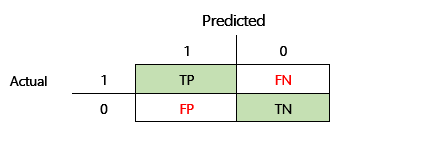
이전 그림의 혼동 행렬에서 이러한 메트릭은 다음과 같은 방식으로 계산됩니다.
- 정밀도 = TP ÷ (TP + FP)
- 재현율 = TP ÷ (TP + FN)
F1 측정은 정밀도와 재현율을 결합합니다. 결과는 두 값의 조화 평균입니다. 다음과 같은 방식으로 계산됩니다.
- F1 = 2 × (정밀도 × 재현율) ÷ (정밀도 + 재현율)
구체적인 예를 보겠습니다. 이 기사의 앞부분에는 동물이 개인지 고양이인지 예측하는 모델의 예가 있었습니다. 그림은 여기에서 반복됩니다.
다음은 "개"를 양성 답변으로 사용한 경우의 결과입니다.
- 정밀도 = 24 ÷ (24 + 2) = 0.9231
- 재현율 = 24 ÷ (24 + 6) = 0.8
- F1 = 2 × (0.9231 × 0.8) ÷ (0.9231 + 0.8) = 0.8572
보시다시피 F1 값은 정밀도와 재현율 사이에 있습니다.
F1 정확도는 이해하기 쉽지 않지만 기본 정확도 수치에 뉘앙스를 추가합니다. 다음 토론에서 볼 수 있듯이 불균형 데이터 세트에도 도움이 될 수 있습니다.
이 문서의 모델 정확도 섹션에서는 다음 두 가지 혼동 행렬을 비교했습니다. 첫 번째 모델은 정확도가 낮았지만 정시 지불의 기본 추측보다 개선 사항이 더 많이 나타났기 때문에 더 유용한 모델로 간주되었습니다.
F1 점수가 사용될 때 이 두 모델이 어떻게 비교되는지 봅시다. F1 점수는 각 상태에 대한 정밀도 및 재현율을 고려하며 F1 매크로 계산은 전체 F1 점수를 결정하기 위해 상태 전체의 F1 점수를 평균화합니다. 다른 F1 변형이 있지만 세 가지 상태 모두에 동일한 고려 사항이 주어지면 매크로 버전을 고려하는 것이 더 중요합니다.
계산을 단순화하기 위해 실제 값 및 예측 값과 일치하도록 샘플 배열을 구축했습니다. 이 배열은 값을 계산하기 위해 Python에서 sklearn의 메트릭 라이브러리를 사용했습니다. 결과는 다음과 같습니다.
| 모델 | 단순 추측 | 정확성 | F1 매크로 |
|---|---|---|---|
| 모델 1 | 0.5 | 0.73 | 0.67 |
| 모델 2 | 0.80 | 0.83 | 0.66 |
이 계산 방식에 대한 자세한 내용은 모델 1에 대한 sklearn.metrics 분류 보고서를 참조하세요. "정시", "지연" 및 "매우 지연"의 세 가지 상태는 각각 1, 2 및 3으로 레이블이 지정된 행으로 표시됩니다. 매크로 평균은 "f1-점수" 열의 평균입니다.
| 정밀도 | 재현율 | f1-점수 | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
이 결과에서 알 수 있듯이 두 모델은 F1 매크로 정확도 점수가 거의 동일합니다. 이 경우 및 다른 많은 경우에 F1 정확도는 모델의 기능에 대한 더 나은 지표를 제공합니다. 정확도와 관련하여 결과를 해석하려면 모델에서 고려해야 할 가장 중요한 것이 무엇인지 이해해야 합니다.