온-프레미스 데이터 게이트웨이 크기 조정
이 문서는 온-프레미스 데이터 게이트웨이를 설치하고 관리해야 하는 Power BI 관리자를 대상으로 합니다.
게이트웨이는 Power BI가 인터넷을 통해 직접 액세스할 수 없는 데이터에 액세스해야 하는 경우에 필요합니다. 온-프레미스 서버에 설치하거나 VM에서 호스트되는 IaaS(서비스 제공 인프라)를 사용할 수 있습니다.
게이트웨이 워크로드
온-프레미스 데이터 게이트웨이는 두 가지 워크로드를 지원합니다. 게이트웨이 크기 조정 및 권장 사항에 대해 설명하기 전에 먼저 이러한 워크로드르 이해하는 것이 중요합니다.
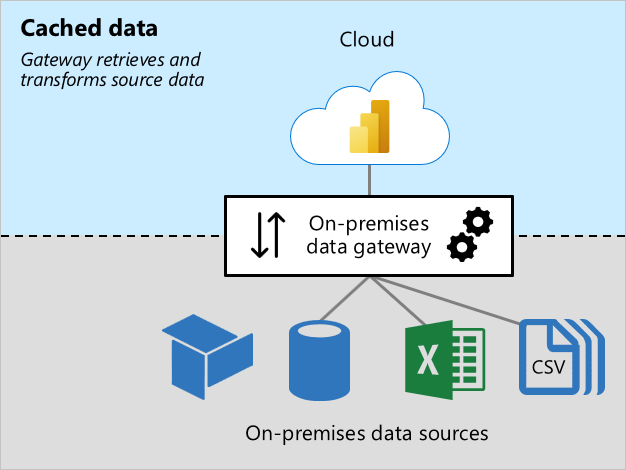
캐시된 데이터 워크로드
캐시된 데이터 워크로드는 Power BI 의미 체계 모델(이전 데이터 세트)에 로드하기 위해 원본 데이터를 검색하고 변환합니다. 이 작업은 세 단계로 수행됩니다.
- 연결: 게이트웨이가 원본 데이터에 연결합니다.
- 데이터 검색 및 변환: 데이터가 검색되고 필요한 경우 변환됩니다. 가능하면 파워 쿼리 매시업 엔진은 데이터 원본에 변환 단계를 푸시합니다. 이를 쿼리 폴딩이라고 합니다. 가능하지 않은 경우에는 게이트웨이에서 변환해야 합니다. 이 경우 게이트웨이는 더 많은 CPU 및 메모리 리소스를 사용합니다.
- 전송: 데이터가 Power BI 서비스로 전송됩니다. 특히 대용량 데이터 볼륨의 경우 안정적이고 빠른 인터넷 연결이 중요합니다.
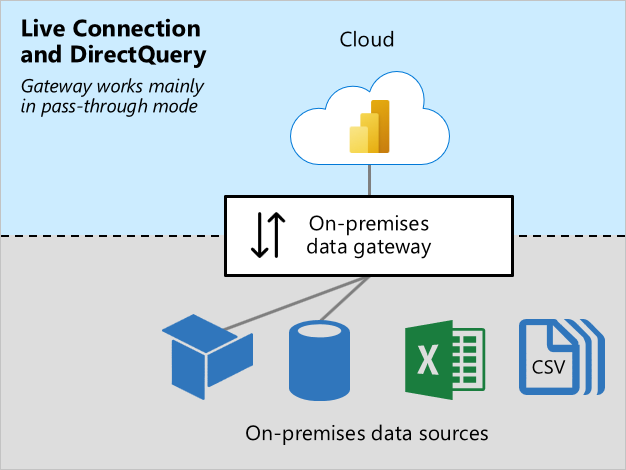
라이브 연결 및 DirectQuery 워크로드
라이브 연결 및 DirectQuery 워크로드는 대부분 통과 모드에서 작동합니다. Power BI 서비스는 쿼리를 전송하고 게이트웨이는 쿼리 결과를 사용하여 응답합니다. 일반적으로 쿼리 결과는 크기가 작습니다.
- 라이브 연결에 관한 자세한 내용은 Power BI 서비스의 의미 체계 모델(외부 호스트형 모델)을 참조하세요.
- DirectQuery에 관한 자세한 내용은 Power BI 서비스의 의미 체계 모델 모드(DirectQuery 모드)를 참조하세요.
이 워크로드를 수행하려면 쿼리 및 쿼리 결과를 라우팅하기 위한 CPU 리소스가 필요합니다. 특히 캐시를 위해 데이터를 변환해야 하는 경우, 일반적으로 캐시 데이터 워크로드에서 요구하는 것보다 훨씬 적은 CPU가 필요합니다.
보고서 사용자에게 응답성이 뛰어난 환경을 보장하기 위해 안정적이고 빠르고 일관된 연결이 중요합니다.
크기 조정 고려 사항
게이트웨이 컴퓨터의 올바른 크기를 결정하는 것은 다음 변수에 따라 달라질 수 있습니다.
- 캐시 데이터 워크로드의 경우:
- 동시 의미 체계 모델 새로 고침 수
- 데이터 원본 유형(관계형 데이터베이스, 분석 데이터베이스, 데이터 피드 또는 파일)
- 데이터 원본에서 검색할 데이터의 볼륨
- 파워 쿼리 매시업 엔진에서 수행해야 하는 모든 변환
- Power BI 서비스로 전송할 데이터의 볼륨
- 라이브 연결 및 DirectQuery 워크로드의 경우:
- 동시 보고서 사용자 수
- 보고서 페이지의 시각적 개체 수(각 시각적 개체는 하나 이상의 쿼리를 보냄)
- Power BI 대시보드 쿼리 캐시 업데이트의 빈도
- 자동 페이지 새로 고침 기능을 사용하는 실시간 보고서의 수
- 의미 체계 모델이 RLS(행 수준 보안)를 적용하는지 여부
일반적으로 라이브 연결 및 DirectQuery 워크로드에는 충분한 CPU가 필요하고, 캐시 데이터 워크로드에는 더 많은 CPU 및 메모리가 필요합니다. 두 워크로드 모두 Power BI 서비스 및 데이터 원본과의 양호한 연결이 필요합니다.
참고 항목
Power BI 용량은 모델 새로 고침 병렬 처리와 라이브 연결 및 DirectQuery 처리량에 제한을 부과합니다. 게이트웨이의 크기를 조정하더라도 Power BI 서비스에서 지원하는 것보다 많은 용량을 제공할 수는 없습니다. 제한은 프리미엄 SKU(및 이와 동일한 크기의 SKU)에 따라 달라집니다. 자세한 내용은 Microsoft Fabric 용량 라이선스 및 Power BI Premium이란? (용량 노드)를 참조하세요.
Important
경우에 따라 이 문서는 Power BI Premium 또는 해당 용량 구독(P SKU)을 참조합니다. Microsoft는 현재 구매 옵션을 통합하고 용량당 Power BI Premium SKU를 사용 중지하고 있습니다. 신규 및 기존 고객은 대신 용량 구독(F SKU)을 구매를 고려해야 합니다.
자세한 내용은 Power BI Premium 라이선스 관련 중요 업데이트 및 Power BI Premium FAQ를 참조하세요.
권장 사항
게이트웨이 크기 조정 권장 사항은 여러 변수에 따라 달라집니다. 이 섹션에서는 고려할 수 있는 일반적인 권장 사항을 소개합니다.
초기 크기 조정
올바른 크기를 정확하게 예측하기란 어려울 수 있습니다. 적어도 CPU 코어 8개, 8GB RAM 및 기가비트 네트워크 어댑터가 있는 컴퓨터에서 시작하는 것이 좋습니다. 그런 다음 CPU 및 메모리 시스템 카운터를 기록하여 일반적인 게이트웨이 워크로드를 측정할 수 있습니다. 자세한 내용은 온-프레미스 데이터 게이트웨이 성능 모니터링 및 최적화를 참조하세요.
연결
Power BI 서비스와 게이트웨이 그리고 게이트웨이와 데이터 원본 간의 최적 연결을 계획합니다.
- 안정성, 빠른 속도 및 낮고 일관성 있는 대기 시간을 위해 노력합니다.
- 게이트웨이와 데이터 원본 간의 컴퓨터 홉을 제거(또는 감소)합니다.
- 방화벽 프록시 계층에 의해 적용되는 모든 네트워크 제한을 제거합니다. Power BI 엔드포인트에 대한 자세한 내용은 허용 목록에 Power BI URL 추가를 참조하세요.
- Azure ExpressRoute를 설정하여 Power BI에 대하여 관리되는 프라이빗 연결을 설정합니다.
- Azure VM 내 데이터 원본의 경우 VM이 Power BI 서비스와 함께 배치되도록 합니다.
- 동적 RLS를 포함하는 SSAS(SQL Server Analysis Services)에 대한 라이브 연결 워크로드의 경우 게이트웨이 컴퓨터와 온-프레미스 Active Directory간에 적절한 연결을 보장합니다.
Clustering
대규모 배포의 경우에는 여러 클러스터 멤버를 포함하는 게이트웨이를 만들 수 있습니다. 클러스터는 단일 실패 지점이 발생하지 않으며 게이트웨이 간에 트래픽 부하를 분산할 수 있습니다. 다음이 가능합니다.
- 클러스터에 하나 이상의 게이트웨이를 설치합니다.
- 워크로드를 독립 실행형 게이트웨이 또는 게이트웨이 서버의 클러스터로 격리합니다.
자세한 내용은 온-프레미스 데이터 게이트웨이 고가용성 클러스터 및 부하 분산 관리를 참조하세요.
의미 체계 모델 디자인 및 설정
의미 체계 모델 디자인과 해당 설정은 게이트웨이 워크로드에 영향을 줄 수 있습니다. 게이트웨이 워크로드를 줄이기 위해 다음 조치를 고려할 수 있습니다.
의미 체계 모델 가져오기:
- 데이터 새로 고침을 더 낮은 빈도로 설정합니다.
- 증분 새로 고침을 전송할 데이터의 양을 최소화하도록 설정합니다.
- 가능하면 쿼리 폴딩이 발생하게 합니다.
- 특히 대용량 데이터 볼륨의 경우 또는 낮은 대기 시간 결과가 필요한 경우 디자인을 DirectQuery 또는 복합 모델로 변환합니다.
DirectQuery 의미 체계 모델:
- 데이터 원본, 모델 및 보고서 디자인을 최적화합니다(자세한 내용은 Power BI Desktop의 DirectQuery 모델 지침 참조).
- 집계를 만들어 더 상위 수준 결과를 캐시하여 DirectQuery 요청 수를 축소합니다.
- 보고서 디자인 및 용량 설정에서 자동 페이지 새로 고침 간격을 제한합니다.
- 특히 동적 RLS가 적용되는 경우 대시보드 캐시 업데이트 빈도를 제한합니다.
- 특히 더 작은 데이터 볼륨 또는 비휘발성 데이터의 경우 디자인을 가져오기 또는 복합 모델로 변환합니다.
라이브 연결 의미 체계 모델:
- 특히 동적 RLS가 적용되는 경우 대시보드 캐시 업데이트 빈도를 제한합니다.
관련 콘텐츠
이 문서와 관련된 보다 자세한 내용을 알아보려면 다음 리소스를 참조하세요.