다양한 데이터 원본에서 Machine Learning Studio(클래식)로 학습 데이터 가져오기
적용 대상:  Machine Learning Studio(클래식)
Machine Learning Studio(클래식)  Azure Machine Learning
Azure Machine Learning
Important
Machine Learning Studio(클래식)에 대한 지원은 2024년 8월 31일에 종료됩니다. 해당 날짜까지 Azure Machine Learning으로 전환하는 것이 좋습니다.
2021년 12월 1일부터 새로운 Machine Learning Studio(클래식) 리소스를 만들 수 없습니다. 2024년 8월 31일까지는 기존 Machine Learning Studio(클래식) 리소스를 계속 사용할 수 있습니다.
- ML Studio(클래식)에서 Azure Machine Learning으로 기계 학습 프로젝트 이동에 대한 정보를 참조하세요.
- Azure Machine Learning에 대해 자세히 알아보세요.
ML Studio(클래식) 설명서는 사용 중지되며 나중에 업데이트되지 않을 수 있습니다.
다음 데이터를 사용하면 Machine Learning Studio(클래식)에 사용자 고유의 데이터를 사용하여 예측 분석 솔루션을 개발 및 학습할 수 있습니다.
- 로컬 파일 - 하드 드라이브에서 미리 로컬 데이터를 로드하여 작업 영역에 데이터 세트 모듈 만들기
- 온라인 데이터 원본 - 데이터 가져오기 모듈을 사용하여 실험을 실행하는 동안 여러 온라인 원본 중 하나에서 데이터에 액세스합니다.
- Machine Learning Studio(클래식) 실험 - Machine Learning Studio(클래식)에서 데이터 세트로 저장된 데이터 사용
- SQL Server 데이터베이스 - 데이터를 수동으로 복사하지 않고도 SQL Server 데이터베이스의 데이터 사용
참고 항목
Machine Learning Studio(클래식)에는 학습 데이터에 사용할 수 있는 여러 샘플 데이터 세트가 있습니다. 이에 대한 자세한 내용은 Machine Learning Studio(클래식)의 샘플 데이터 세트 사용을 참조하세요.
데이터 준비
Machine Learning Studio(클래식)는 직사각형 또는 테이블 형식 데이터(예: 데이터베이스에서 구분되거나 구조화된 데이터)와 함께 작동하도록 설계되었지만 경우에 따라 직사각형이 아닌 데이터를 사용할 수 있습니다.
데이터를 Studio(클래식)로 가져오기 전에 비교적 깨끗한 경우 가장 좋습니다. 예를 들어 따옴표가 없는 문자열과 같은 문제를 처리할 수 있습니다.
그러나 Studio(클래식)에는 데이터를 가져온 후 실험에서 데이터를 조작할 수 있는 모듈도 있습니다. 사용할 기계 학습 알고리즘에 따라 누락된 값 및 스파스 데이터와 같은 데이터 구조적 문제를 처리하는 방법을 결정해야 할 수 있으며 이를 도울 수 있는 모듈이 있습니다. 모듈 팔레트의 데이터 변환 섹션에서 이러한 함수를 수행하는 모듈을 찾습니다.
실험의 어느 시점에서든 출력 포트를 클릭하여 모듈에서 생성된 데이터를 보거나 다운로드할 수 있습니다. 모듈에 따라 다양한 다운로드 옵션을 사용할 수 있거나 Studio(클래식)의 웹 브라우저 내에서 데이터를 시각화할 수 있습니다.
지원되는 데이터 형식 및 데이터 유형
데이터를 가져오는 데 사용하는 메커니즘과 데이터의 출처에 따라 실험에 여러 데이터 형식을 가져올 수 있습니다.
- 일반 텍스트(.txt)
- 헤더가 있거나(.csv) 없는(.nh.csv) 쉼표로 구분된 값(CSV)
- 헤더가 있거나(.tsv) 없는(.nh.tsv) 탭으로 구분된 값(TSV)
- Excel 파일
- Azure 테이블
- Hive 테이블
- SQL 데이터베이스 테이블
- OData 값
- SVMLight 데이터(.svmlight)(형식 정보는 SVMLight 정의 참조)
- ARFF(특성 관계 파일 형식) 데이터(.arff)(형식 정보는 ARFF 정의 참조)
- Zip 파일(.zip)
- R 개체 또는 작업 영역 파일(. RData)
메타데이터를 포함하는 ARFF와 같은 형식으로 데이터를 가져오는 경우 Studio(클래식)는 이 메타데이터를 사용하여 각 열의 제목 및 데이터 형식을 정의합니다.
이 메타데이터를 포함하지 않는 TSV 또는 CSV 형식과 같은 데이터를 가져오는 경우 Studio(클래식)는 데이터를 샘플링하여 각 열의 데이터 형식을 유추합니다. 데이터에 열 머리글도 없는 경우 Studio(클래식)는 기본 이름을 제공합니다.
메타데이터 편집 모듈을 사용하여 열의 제목 및 데이터 형식을 명시적으로 지정하거나 변경할 수 있습니다.
Studio(클래식)에서 인식되는 데이터 형식은 다음과 같습니다.
- 문자열
- 정수
- Double
- Boolean
- DateTime
- TimeSpan
Studio에서는 데이터 테이블이라는 내부 데이터 형식을 사용하여 모듈 간에 데이터를 전달합니다. 데이터 세트로 변환 모듈을 사용하여 데이터를 데이터 테이블 형식으로 명시적으로 변환할 수 있습니다.
데이터 테이블 이외의 형식을 허용하는 모든 모듈에서는 다음 모듈에 데이터를 전달하기 전에 데이터 테이블로 자동 변환합니다.
필요한 경우 다른 변환 모듈을 사용하여 데이터 테이블 형식을 CSV, TSV, ARFF 또는 SVMLight 형식으로 다시 변환할 수 있습니다. 모듈 팔레트의 데이터 형식 변환 섹션에서 이러한 함수를 수행하는 모듈을 찾습니다.
데이터 용량
Machine Learning Studio(클래식)의 모듈은 일반적인 사용 사례의 경우 최대 10GB 숫자 데이터의 데이터 세트를 지원합니다. 모듈이 둘 이상의 입력을 사용하는 경우 10GB 값은 모든 입력 크기의 합계입니다. Hive 또는 Azure SQL Database의 쿼리를 사용하여 더 큰 데이터 세트를 샘플링하거나 데이터를 가져오기 전에 Learning by Counts 전처리를 사용할 수 있습니다.
다음 유형의 데이터는 기능 정규화 중에 더 큰 데이터 세트로 확장될 수 있으며 10GB 미만으로 제한됩니다.
- 스파스
- 범주
- 문자열
- 이진 데이터
다음 모듈은 10GB 미만의 데이터 세트로 제한됩니다.
- 추천 모듈
- SMOTE(Synthetic Minority Oversampling Technique) 모듈
- 스크립팅 모듈: R, Python, SQL
- 출력 데이터 크기가 입력 데이터 크기보다 클 수 있는 모듈(예: 조인 또는 기능 해시)
- 반복 수가 매우 큰 경우 교차 유효성 검사, 모델 하이퍼 매개 변수 조정, 서수 회귀 및 One-vs-All 다중 클래스
몇 GB보다 큰 데이터 세트의 경우 로컬 파일에서 직접 업로드하는 대신 Azure Storage 또는 Azure SQL Database에 데이터를 업로드하거나 Azure HDInsight를 사용합니다.
이미지 가져오기 모듈 참조에서 이미지 데이터에 대한 정보를 확인할 수 있습니다.
로컬 파일에서 가져오기
하드 드라이브에서 데이터 파일을 업로드하여 Studio(클래식)에서 학습 데이터로 사용할 수 있습니다. 데이터 파일을 가져올 때 작업 영역의 실험에서 사용할 수 있는 데이터 세트 모듈을 만듭니다.
로컬 하드 드라이브에서 데이터를 가져오려면 다음을 수행합니다.
- Studio(클래식) 창 아래쪽에서 +새로 만들기를 클릭합니다.
- DATASET 및 FROM LOCAL FILE을 선택합니다.
- 새 데이터 세트 업로드 대화 상자에서 업로드할 파일을 찾습니다.
- 이름을 입력하고, 데이터 형식을 식별하며, 선택적으로 설명을 입력합니다. 설명이 권장됩니다. 나중에 데이터를 사용할 때 기억하려는 데이터에 대한 특성을 기록할 수 있습니다.
- 이 확인란은 기존 데이터 세트의 새 버전이므로 기존 데이터 세트를 새 데이터로 업데이트할 수 있습니다. 이렇게 하려면 이 확인란을 클릭한 다음 기존 데이터 세트의 이름을 입력합니다.
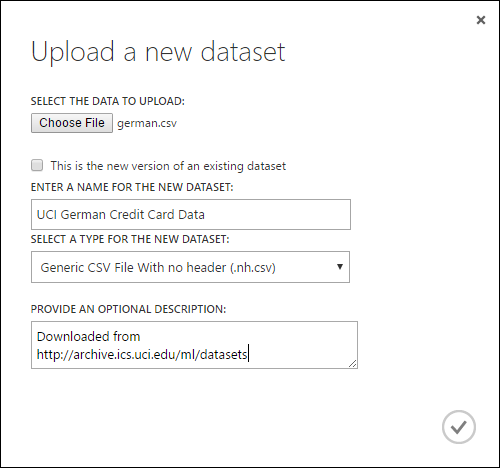
업로드 시간은 데이터의 크기와 서비스에 대한 연결 속도에 따라 달라집니다. 파일이 오래 걸리는 것을 알고 있는 경우 기다리는 동안 Studio(클래식) 내에서 다른 작업을 수행할 수 있습니다. 그러나 데이터 업로드가 완료되기 전에 브라우저를 닫으면 업로드가 실패합니다.
데이터가 업로드되면 데이터 세트 모듈에 저장되고 작업 영역의 모든 실험에서 사용할 수 있습니다.
실험을 편집할 때 모듈 팔레트의 저장된 데이터 세트 목록 아래에 있는 내 데이터 세트 목록에서 업로드한 데이터 세트를 찾을 수 있습니다. 추가 분석 및 기계 학습을 위해 데이터 세트를 사용하려고 할 때 데이터 세트를 실험 캔버스에 끌어서 놓을 수 있습니다.
온라인 데이터 원본에서 가져오기
데이터 가져오기 모듈을 사용하여 실험이 실행되는 동안 다양한 온라인 데이터 원본에서 데이터를 가져올 수 있습니다.
참고 항목
이 문서에서는 데이터 가져오기 모듈에 대한 일반적인 정보를 제공합니다. 액세스할 수 있는 데이터 형식, 형식, 매개 변수 및 일반적인 질문에 대한 답변에 대한 자세한 내용은 데이터 가져오기 모듈에 대한 모듈 참조 항목을 참조하세요.
데이터 가져오기 모듈을 사용하여 실험을 실행하는 동안 여러 온라인 데이터 원본 중 하나에서 데이터에 액세스할 수 있습니다.
- HTTP를 사용하는 웹 URL
- HiveQL을 사용하는 Hadoop
- Azure Blob Storage
- Azure 테이블
- Azure SQL Database. SQL Managed Instance 또는 SQL Server
- 데이터 피드 공급자, OData 현재
- Azure Cosmos DB
실험이 실행되는 동안 이 학습 데이터에 액세스하므로 해당 실험에서만 사용할 수 있습니다. 이에 비해 데이터 세트 모듈에 저장된 데이터는 작업 영역의 모든 실험에서 사용할 수 있습니다.
Studio(클래식) 실험에서 온라인 데이터 원본에 액세스하려면 데이터 가져오기 모듈을 실험에 추가합니다. 그런 다음, 속성 아래에서 데이터 가져오기 마법사를 선택하여 단계별 지침에 따라 데이터 원본을 선택하고 구성합니다. 또는 속성에서 데이터 원본을 수동으로 선택하여 데이터에 액세스하는 데 필요한 매개 변수를 제공할 수 있습니다.
지원되는 온라인 데이터 원본을 아래 표에 항목별로 나타냈습니다. 이 표에는 지원되는 파일 형식과 데이터에 액세스하는 데 사용되는 매개 변수도 요약되어 있습니다.
Important
현재 데이터 가져오기 및 데이터 내보내기 모듈은 클래식 배포 모델을 사용하여 만든 Azure Storage에서만 데이터를 읽고 쓸 수 있습니다. 즉, 핫 스토리지 액세스 계층 또는 쿨 스토리지 액세스 계층을 제공하는 새 Azure Blob Storage 계정 유형은 아직 지원되지 않습니다.
일반적으로 이 서비스 옵션을 사용할 수 있게 되기 전에 만든 Azure Storage 계정은 영향을 받지 않습니다. 새 계정을 만들려면 배포 모델에 대해 클래식을 선택하거나 Resource Manager를 사용하고 계정 종류에는 Blob Storage 대신 범용을 선택합니다.
자세한 내용은 Azure Blob Storage: 핫 및 쿨 스토리지 계층을 참조 하세요.
지원되는 온라인 데이터 원본
Machine Learning Studio(클래식) 데이터 가져오기 모듈은 다음 데이터 원본을 지원합니다.
| 데이터 원본 | 설명 | 매개 변수 |
|---|---|---|
| HTTP를 통한 웹 URL | HTTP를 사용하는 어떤 웹 URL에서도 데이터를 쉼표로 구분된 값(CSV), 탭으로 구분된 값(TSV), 특성-관계 파일 형식(ARFF) 및 지원 벡터 컴퓨터(SVM-light) 형식으로 읽습니다. | URL: 모든 확장명을 사용하여 사이트 URL 및 파일 이름을 포함하여 파일의 전체 이름을 지정합니다. 데이터 형식: 지원되는 데이터 형식: CSV, TSV, ARFF 또는 SVM-light 중 하나를 지정합니다. 데이터에 머리글 행이 있는 경우 해당 행을 사용하여 열 이름을 할당합니다. |
| Hadoop/HDFS | Hadoop의 분산 스토리지에서 데이터를 읽습니다. SQL과 유사한 쿼리 언어인 HiveQL을 사용하여 원하는 데이터를 지정합니다. 또한 HiveQL을 사용하여 Studio(클래식)에 데이터를 추가하기 전에 데이터를 집계하고 데이터 필터링을 수행할 수 있습니다. | Hive 데이터베이스 쿼리: 데이터를 생성하는 데 사용되는 Hive 쿼리를 지정합니다. HCatalog 서버 URI : 클러스터 이름.azurehdinsight.net 형식 <을 사용하여 클러스터의 이름을> 지정했습니다. Hadoop 사용자 계정 이름: 클러스터를 프로비전하는 데 사용되는 Hadoop 사용자 계정 이름을 지정합니다. Hadoop 사용자 계정 암호 : 클러스터를 프로비전할 때 사용되는 자격 증명을 지정합니다. 자세한 내용은 HDInsight에서 Hadoop 클러스터 만들기를 참조하세요. 출력 데이터 위치: 데이터가 HDFS(Hadoop 분산 파일 시스템) 또는 Azure에 저장되는지 여부를 지정합니다.
출력 데이터를 Azure에 저장하는 경우 Azure Storage 계정 이름, 스토리지 액세스 키 및 스토리지 컨테이너 이름을 지정해야 합니다. |
| SQL 데이터베이스 | Azure SQL Database, SQL Managed Instance 또는 Azure 가상 머신에서 실행되는 SQL Server 데이터베이스에 저장된 데이터를 읽습니다. | 데이터베이스 서버 이름: 데이터베이스가 실행 중인 서버의 이름을 지정합니다.
Azure 가상 머신에서 호스트되는 SQL Server인 경우 tcp:<가상 머신 DNS 이름>, 1433을 입력합니다. 데이터베이스 이름 : 서버에 있는 데이터베이스의 이름을 지정합니다. 서버 사용자 계정 이름: 데이터베이스에 대한 액세스 권한이 있는 계정의 사용자 이름을 지정합니다. 서버 사용자 계정 암호: 사용자 계정의 암호를 지정합니다. 데이터베이스 쿼리:읽을 데이터를 설명하는 SQL 문을 입력합니다. |
| 온-프레미스 SQL 데이터베이스 | SQL 데이터베이스에 저장된 데이터를 읽습니다. | 데이터 게이트웨이: SQL Server 데이터베이스에 액세스할 수 있는 컴퓨터에 설치된 데이터 관리 게이트웨이의 이름을 지정합니다. 게이트웨이 설정에 대한 자세한 내용은 SQL Server의 데이터를 사용하여 Machine Learning Studio(클래식)로 고급 분석 수행을 참조하세요. 데이터베이스 서버 이름: 데이터베이스가 실행 중인 서버의 이름을 지정합니다. 데이터베이스 이름 : 서버에 있는 데이터베이스의 이름을 지정합니다. 서버 사용자 계정 이름: 데이터베이스에 대한 액세스 권한이 있는 계정의 사용자 이름을 지정합니다. 사용자 이름 및 암호: 값 입력을 클릭하여 데이터베이스 자격 증명을 입력합니다. SQL Server가 구성된 방식에 따라 Windows 통합 인증 또는 SQL Server 인증을 사용할 수 있습니다. 데이터베이스 쿼리:읽을 데이터를 설명하는 SQL 문을 입력합니다. |
| Azure 테이블 | Azure Storage의 Table Service에서 데이터를 읽습니다. 대량의 데이터를 자주 읽지 않는 경우 Azure Table Service를 사용합니다. 이는 유연하고, 비관계형(NoSQL)이고, 확장성이 매우 뛰어나고, 저렴하고, 가용성이 높은 스토리지 솔루션을 제공합니다. |
데이터 가져오기의 옵션은 공용 정보에 액세스하는지 아니면 로그인 자격 증명이 필요한 프라이빗 스토리지 계정에 액세스하는지에 따라 변경됩니다. 이는 각각 고유한 매개 변수 집합이 있는 "PublicOrSAS" 또는 "계정" 값을 가질 수 있는 인증 유형에 따라 결정됩니다. 공용 또는 SAS(공유 액세스 서명) URI: 매개 변수는 다음과 같습니다.
속성 이름을 검색할 행을 지정합니다. 값 은 지정된 행 수를 검색하는 TopN 이거나 , ScanAll 을 사용하여 테이블의 모든 행을 가져옵니다. 데이터가 동질적이고 예측 가능한 경우 TopN을 선택하고 N에 숫자를 입력하는 것이 좋습니다. 큰 테이블의 경우 읽기 시간이 더 빨라질 수 있습니다. 데이터가 테이블의 깊이와 위치에 따라 달라지는 속성 집합으로 구조화되어 있는 경우 ScanAll 옵션을 선택하여 모든 행을 검색합니다. 이렇게 하면 결과 속성 및 메타데이터 변환의 무결성이 보장됩니다.
계정 키: 계정과 연결된 스토리지 키를 지정합니다. 테이블 이름: 읽을 데이터를 포함하는 테이블의 이름을 지정합니다. 속성 이름을 검색할 행: 값 은 지정된 행 수를 검색하는 TopN 이거나 , ScanAll 을 사용하여 테이블의 모든 행을 가져옵니다. 데이터가 동질적이고 예측 가능한 경우 TopN을 선택하고 N에 숫자를 입력하는 것이 좋습니다. 큰 테이블의 경우 읽기 시간이 더 빨라질 수 있습니다. 데이터가 테이블의 깊이와 위치에 따라 달라지는 속성 집합으로 구조화되어 있는 경우 ScanAll 옵션을 선택하여 모든 행을 검색합니다. 이렇게 하면 결과 속성 및 메타데이터 변환의 무결성이 보장됩니다. |
| Azure Blob Storage | 이미지, 구조화되지 않은 텍스트 또는 이진 데이터를 포함하여 Azure Storage의 Blob 서비스에 저장된 데이터를 읽습니다. 또한 Blob service를 사용하여 데이터를 공용으로 표시하거나 애플리케이션 데이터를 개인적으로 저장할 수 있습니다. HTTP 또는 HTTPS 연결을 사용하여 어디서나 데이터에 액세스할 수 있습니다. |
데이터 가져오기 모듈의 옵션은 공용 정보에 액세스하는지 로그인 자격 증명이 필요한 프라이빗 스토리지 계정에 액세스하는지에 따라 달라집니다. 이는 "PublicOrSAS" 또는 "계정" 중 하나의 값을 가질 수 있는 인증 유형에 따라 결정됩니다. 공용 또는 SAS(공유 액세스 서명) URI: 매개 변수는 다음과 같습니다.
파일 형식: Blob 서비스에서 데이터의 형식을 지정합니다. 지원되는 형식은 CSV, TSV 및 ARFF입니다.
계정 키: 계정과 연결된 스토리지 키를 지정합니다. 컨테이너, 디렉터리 또는 Blob 에 대한 경로: 읽을 데이터가 포함된 Blob의 이름을 지정합니다. Blob 파일 형식: Blob service의 데이터 형식을 지정합니다. 지원되는 데이터 형식은 CSV, TSV, ARFF, 지정된 인코딩이 있는 CSV 및 Excel입니다.
Excel 옵션을 사용하여 Excel 통합 문서에서 데이터를 읽을 수 있습니다. Excel 데이터 형식 옵션에서 데이터가 Excel 워크시트 범위에 있는지 아니면 Excel 표에 있는지를 나타냅니다. Excel 시트 또는 포함된 표 옵션에서 읽을 시트 또는 표의 이름을 지정합니다. |
| 데이터 피드 공급자 | 지원되는 피드 공급자에서 데이터를 읽습니다. 현재 OData(Open Data Protocol) 형식만 지원됩니다. | 데이터 콘텐츠 형식: OData 형식을 지정합니다. 원본 URL: 데이터 피드에 대한 전체 URL을 지정합니다. 예를 들어 다음 URL은 Northwind 샘플 데이터베이스에서 읽습니다. https://services.odata.org/northwind/northwind.svc/ |
다른 실험에서 가져오기
한 실험에서 중간 결과를 가져와서 다른 실험의 일부로 사용하려는 경우가 있습니다. 이렇게 하려면 모듈을 데이터 세트로 저장합니다.
- 데이터 세트로 저장할 모듈의 출력을 클릭합니다.
- 데이터 세트로 저장을 클릭합니다.
- 메시지가 표시되면 데이터 세트를 쉽게 식별할 수 있는 이름과 설명을 입력합니다.
- 확인 확인 표시를 클릭합니다.
저장이 완료되면 작업 영역의 모든 실험 내에서 데이터 세트를 사용할 수 있습니다. 모듈 팔레트의 저장된 데이터 세트 목록에서 찾을 수 있습니다.
다음 단계
데이터 가져오기 및 데이터 내보내기 모듈을 사용하는 Machine Learning Studio(클래식) 웹 서비스 배포