빠른 R-CNN을 사용하여 개체 감지
목차
요약

이 자습서에서는 CNTK Python API에서 빠른 R-CNN을 사용하는 방법을 설명합니다. BrainScript 및 cnkt.exe 사용하는 빠른 R-CNN은 여기에 설명되어 있습니다.
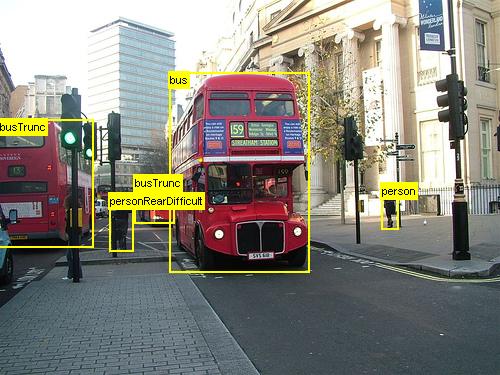
위의 예제는 이 자습서에 사용된 식료품 데이터 집합(왼쪽) 및 Pascal VOC 데이터 집합(오른쪽)에 대한 이미지 및 개체 주석입니다.
빠른 R-CNN 은 2015년 Ross Girshick 이 제안한 개체 감지 알고리즘입니다. 이 문서는 ICCV 2015에 허용되고 보관됩니다 https://arxiv.org/abs/1504.08083. 빠른 R-CNN은 깊은 나선형 네트워크를 사용하여 개체 제안을 효율적으로 분류하기 위해 이전 작업을 기반으로 합니다. 이전 작업과 비교하여 Fast R-CNN은 나선형 계층의 계산 을 다시 사용할 수 있는 관심 풀링 구성표를 사용합니다.
설치 프로그램
이 예제에서 코드를 실행하려면 CNTK Python 환경이 필요합니다(설치 도움말은 여기 참조). cntk Python 환경에 다음 추가 패키지를 설치하세요.
pip install opencv-python easydict pyyaml dlib
경계 상자 회귀 및 최대값이 아닌 표시 안 함을 위해 미리 컴파일된 이진 파일
폴더 Examples\Image\Detection\utils\cython_modules 에는 빠른 R-CNN을 실행하는 데 필요한 미리 컴파일된 이진 파일이 포함되어 있습니다. 현재 리포지토리에 포함된 버전은 Windows용 Python 3.5 및 Linux용 Python 3.5, 3.6, 모두 64비트입니다. 다른 버전이 필요한 경우 에 설명된 단계에 따라 컴파일할 수 있습니다.
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
생성된 cython_bbox 이진 파일 및(및 cpu_nms /또는 gpu_nms) 이진 파일을 $FRCN_ROOT/lib/utils 복사합니다 $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules.
예제 데이터 및 기준 모델
사전 학습된 AlexNet 모델을 Fast-R-CNN 학습의 기초로 사용합니다(VGG 또는 다른 기본 모델의 경우 다른 기본 모델 사용 참조). 예제 데이터 세트와 미리 학습된 AlexNet 모델은 모두 FastRCNN 폴더에서 다음 Python 명령을 실행하여 다운로드할 수 있습니다.
python install_data_and_model.py
- 다른 기본 모델을 사용하는 방법 알아보기
- Pascal VOC 데이터에서 빠른 R-CNN을 실행하는 방법 알아보기
- 사용자 고유의 데이터에서 빠른 R-CNN을 실행하는 방법 알아보기
토이 예제 실행
빠른 R-CNN 실행을 학습하고 평가하려면
python run_fast_rcnn.py
기본 모델로 AlexNet을 사용하여 식료품점에서 2000 ROI를 학습하는 결과는 다음과 유사합니다.
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
폴더에서 FastRCNN 열린 FastRCNN_config.py 이미지의 예측 경계 상자 및 레이블을 시각화하고 설정하려면
__C.VISUALIZE_RESULTS = True
를 실행python run_fast_rcnn.py하면 이미지가 폴더에 FastRCNN/Output/Grocery/ 저장됩니다.
파스칼 VOC에서 학습
Pascal 데이터를 다운로드하고 CNTK 형식으로 Pascal에 대한 주석 파일을 만들려면 다음 스크립트를 실행합니다.
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
의 dataset_cfg 메서드 run_fast_rcnn.py 를 get_configuration() 변경합니다.
from utils.configs.Pascal_config import cfg as dataset_cfg
이제 을 사용하여 python run_fast_rcnn.pyPascal VOC 2007 데이터를 학습하도록 설정되었습니다. 학습하는 데 시간이 걸릴 수 있습니다.
사용자 고유의 데이터 학습
사용자 지정 데이터 세트 준비
옵션 #1: 시각적 개체 태그 지정 도구(권장)
VOTT(Visual Object Tagging Tool)는 비디오 및 이미지 자산에 태그를 지정하기 위한 플랫폼 간 주석 도구입니다.

VOTT는 다음과 같은 기능을 제공합니다.
- Camshift 추적 알고리즘을 사용하여 비디오에서 개체의 컴퓨터 지원 태그 지정 및 추적
- 개체 검색 모델을 학습하기 위해 태그 및 자산을 CNTK Fast-RCNN 형식으로 내보냅니다.
- 새 비디오에서 학습된 CNTK 개체 검색 모델을 실행하고 유효성을 검사하여 더 강력한 모델을 생성합니다.
VOTT에 주석을 추가하는 방법:
옵션 #2: 주석 스크립트 사용
사용자 고유의 데이터 집합에서 CNTK Fast R-CNN 모델을 학습하기 위해 이미지의 사각형 영역에 주석을 달고 이러한 지역에 레이블을 할당하는 두 개의 스크립트를 제공합니다.
스크립트는 빠른 R-CNN(A1_GenerateInputROIs.py)을 실행하는 첫 번째 단계에서 요구하는 대로 주석을 올바른 형식으로 저장합니다.
먼저 다음 폴더 구조에 이미지를 저장합니다.
<your_image_folder>/negative- 개체를 포함하지 않는 학습에 사용되는 이미지<your_image_folder>/positive- 개체를 포함하는 학습에 사용되는 이미지<your_image_folder>/testImages- 개체를 포함하는 테스트에 사용되는 이미지
음수 이미지의 경우 주석을 만들 필요가 없습니다. 다른 두 폴더의 경우 제공된 스크립트를 사용합니다.
- 실행
C1_DrawBboxesOnImages.py하여 이미지에 경계 상자를 그립니다.- 실행하기 전에 스크립트 집합
imgDir = <your_image_folder>(/positive또는/testImages)에서 - 마우스 커서를 사용하여 주석을 추가합니다. 이미지의 모든 개체에 주석이 추가되면 키 'n'을 누르면 .bboxes.txt 파일이 기록되고 다음 이미지로 이동하면 'u'는 마지막 사각형을 실행 취소(즉, 제거)하고 'q'는 주석 도구를 종료합니다.
- 실행하기 전에 스크립트 집합
- 실행
C2_AssignLabelsToBboxes.py하여 경계 상자에 레이블을 할당합니다.- 실행하기 전에 스크립트 집합
imgDir = <your_image_folder>(/positive또는/testImages)에서... - ... 개체 범주를 반영하도록 스크립트의 클래스 를 조정합니다. 예를 들면 다음과 같습니다
classes = ("dog", "cat", "octopus"). - 스크립트는 각 이미지에 대해 수동으로 주석이 추가된 사각형을 로드하고, 하나씩 표시하며, 창 왼쪽에 있는 해당 단추를 클릭하여 개체 클래스를 제공하도록 사용자에게 요청합니다. "미정" 또는 "제외"로 표시된 지상 진리 주석은 추가 처리에서 완전히 제외됩니다.
- 실행하기 전에 스크립트 집합
사용자 지정 데이터 세트 학습
설명된 폴더 구조에 이미지를 저장하고 주석을 추가한 후 실행하세요.
python Examples/Image/Detection/utils/annotations/annotations_helper.py
스크립트의 폴더를 데이터 폴더로 변경한 후 마지막으로, 기존 예제에 utils\configs 따라 폴더에 만듭니 MyDataSet_config.py 다.
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
__C.CNTK.PROPOSAL_LAYER_SCALES 빠른 R-CNN에는 사용되지 않으며 더 빠른 R-CNN에만 사용됩니다.
데이터에 dataset_cfgget_configuration() 대한 빠른 R-CNN을 학습하고 평가하려면 다음 방법에서 run_fast_rcnn.py
from utils.configs.MyDataSet_config import cfg as dataset_cfg
를 실행 python run_fast_rcnn.py합니다.
기술 세부 정보
빠른 R-CNN 알고리즘은 CNTK Python API에서 구현되는 방법에 대한 개략적인 개요와 함께 알고리즘 세부 정보 섹션에 설명되어 있습니다. 이 섹션에서는 빠른 R-CNN 구성과 다양한 기본 모델을 사용하는 방법에 중점을 둡니다.
매개 변수
매개 변수는 다음 세 부분으로 그룹화됩니다.
- 탐지기 매개 변수(참조
FastRCNN/FastRCNN_config.py) - 데이터 집합 매개 변수(예
utils/configs/Grocery_config.py: 참조) - 기본 모델 매개 변수(예
utils/configs/AlexNet_config.py: 참조)
세 부분이 로드되고 메서드에서 get_configuration() 병합됩니다 run_fast_rcnn.py. 이 섹션에서는 탐지기 매개 변수를 다룹니다. 데이터 세트 매개 변수는 여기에서 기본 모델 매개 변수에 대해 설명 합니다. 다음에서는 .에서 가장 중요한 매개 변수를 살펴봅합니다 FastRCNN_config.py. 모든 매개 변수도 파일에 주석으로 추가됩니다. 구성은 중 EasyDict 첩된 사전에 쉽게 액세스할 수 있는 패키지를 사용합니다.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
ROI 제안은 패키지의 선택적 검색 구현을 사용하여 첫 번째 Epoch에서 즉석에서 dlib 계산됩니다. 생성된 제안의 수는 매개 변수에 의해 __C.NUM_ROI_PROPOSALS 제어됩니다. 약 2000개 제안을 사용하는 것이 좋습니다. 회귀 헤드는 적어도 __C.BBOX_THRESH지면 진리 상자가 있는 IoU(겹침)가 있는 IOI에 대해서만 학습됩니다.
__C.INPUT_ROIS_PER_IMAGE 는 이미지당 최대 접지 진리 주석 수를 지정합니다. CNTK는 현재 최대 수를 설정해야 합니다. 주석이 적으면 내부적으로 패딩됩니다. __C.IMAGE_WIDTH 입력 __C.IMAGE_HEIGHT 이미지의 크기를 조정하고 패딩하는 데 사용되는 차원입니다.
__C.TRAIN.USE_FLIPPED = True 는 다른 모든 Epoch의 모든 이미지를 대칭 이동하여 학습 데이터를 보강합니다. 즉, 첫 번째 epoch에는 모든 일반 이미지가 있고, 두 번째 epoch에는 모든 이미지가 대칭 이동됩니다. __C.TRAIN_CONV_LAYERS 는 입력에서 나선형 기능 맵에 이르는 나선형 계층이 학습되거나 수정될지 여부를 결정합니다. conv 계층 가중치를 수정하면 학습 중에 기본 모델의 가중치가 수행되고 수정되지 않습니다. 학습할 conv 계층 수를 지정할 수도 있습니다. 다른 기본 모델 사용 섹션을 참조하세요.
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD 는 평가에서 겹치는 예측 경계 상자를 삭제하는 데 사용되는 NMS 임계값입니다. 임계값이 낮을수록 제거가 줄어들므로 최종 출력에서 더 많은 예측 경계 상자가 생성됩니다. 설정한 __C.USE_PRECOMPUTED_PROPOSALS = True 경우 판독기는 텍스트 파일에서 미리 계산된 ROI를 읽습니다. 예를 들어 Pascal VOC 데이터에 대한 학습에 사용됩니다. 파일 이름 __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE 이며 __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE .에 Examples/Image/Detection/utils/configs/Pascal_config.py지정됩니다.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
위의 매개 변수는 dlib의 선택적 검색을 구성합니다. 자세한 내용은 dlib 홈페이지를 참조하세요. 다음 추가 매개 변수는 생성된 ROI(최소 및 최대 측면 길이, 영역 및 가로 세로 비율)를 필터링하는 데 사용됩니다.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
선택적 검색이 요청된 것보다 더 많은 ROI를 반환하는 경우 임의로 샘플링됩니다. 더 적은 수의 ROI가 반환되는 경우 지정된 __C.roi_grid_aspect_ratios값을 사용하여 일반 그리드에서 추가 ROI가 생성됩니다.
다른 기본 모델 사용
다른 기본 모델을 사용하려면 메서드에서 다른 모델 구성을 get_configuration()run_fast_rcnn.py선택해야 합니다. 다음 두 가지 모델이 즉시 지원됩니다.
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
VGG16 모델을 다운로드하려면 다음의 다운로드 스크립트를 사용하세요.<cntkroot>/PretrainedModels
python download_model.py VGG16_ImageNet_Caffe
다른 다른 기본 모델을 사용하려면 구성 파일을 utils/configs/VGG16_config.py 복사하고 기본 모델에 따라 수정해야 합니다.
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
기본 모델의 노드 이름을 조사하려면 .에서 cntk.logging.graph메서드를 plot() 사용할 수 있습니다. CNTK의 roi 풀링이 아직 roi 평균 풀링을 지원하지 않으므로 ResNet 모델은 현재 지원되지 않습니다.
알고리즘 세부 정보
빠른 R-CNN
개체 감지를 위한 R-CNN은 2014년 Ross Girshick 등에서 처음 발표되었으며, 파스칼 VOC라는 분야의 주요 개체 인식 과제 중 하나에서 이전의 최첨단 접근 방식을 능가하는 것으로 나타났습니다. 그 이후, 두 개의 후속 논문은 상당한 속도 향상을 포함 출판되었다: 빠른 R-CNN 과 빠른 R-CNN.
R-CNN의 기본 개념은 원래 수백만 개의 주석이 추가된 이미지를 사용하여 이미지 분류를 위해 학습된 심층 신경망을 사용하고 개체 감지를 위해 수정하는 것입니다. 첫 번째 R-CNN 논문의 기본 아이디어는 아래 그림에 나와 있습니다(논문에서 가져온):(1) 입력 이미지를 감안할 때, (2) 첫 번째 단계에서 많은 지역 제안이 생성됩니다. (3) 이러한 지역 제안 또는 ROI(Regions-of-Interests)는 각 ROI에 대해 4096 부동 소수점 값의 벡터를 출력하는 네트워크를 통해 독립적으로 전송됩니다. 마지막으로, (4) 4096 float ROI 표현을 입력으로 사용하고 각 ROI에 레이블과 신뢰도를 출력하는 분류자를 학습합니다.

이 방법은 정확도 측면에서 잘 작동하지만 신경망을 각 ROI에 대해 평가해야 하므로 컴퓨팅 비용이 매우 많이 듭니다. 빠른 R-CNN은 이미지당 단일 시간(특정: 나선형 계층)의 대부분만 평가하여 이러한 단점을 해결합니다. 저자에 따르면, 이것은 테스트 하는 동안 213 배 속도 및 정확도의 손실 없이 훈련 하는 동안 9 배 속도. 이는 ROI를 나선형 기능 맵에 투사하고 최대 풀링을 수행하여 다음 계층에서 예상하는 원하는 출력 크기를 생성하는 ROI 풀링 계층을 사용하여 수행됩니다.
이 자습서에 사용된 AlexNet 예제에서 ROI 풀링 계층은 마지막 나선형 계층과 첫 번째 완전히 연결된 계층 사이에 배치됩니다. 아래에 표시된 CNTK Python API 코드에서는 네트워크의 두 부분인 conv_layers 네트워크와 fc_layers을 복제하여 이를 실현합니다. 그런 다음 입력 이미지가 먼저 정규화되고, roipooling 계층을 fc_layers 통해 conv_layers푸시되고, 마지막으로 예측 및 회귀 헤드가 추가되어 각각 후보 ROI당 클래스 레이블 및 회귀 계수를 예측합니다.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
R-CNN 논문에 사용된 원래 Caffe 구현은 GitHub: RCNN, Fast R-CNN 및 더 빠른 R-CNN에서 찾을 수 있습니다.
SVM 및 NN 학습
Patrick Buehler는 CNTK Fast R-CNN 출력(마지막으로 완전히 연결된 계층의 4096 기능 사용)에서 SVM을 학습하는 방법에 대한 지침과 여기에서 장단점을 설명합니다.
선택적 검색
선택적 검색 은 실제 개체의 클래스와 관계없이 이미지에서 가능한 개체 위치의 큰 집합을 찾는 방법입니다. 이미지 픽셀을 세그먼트로 클러스터링한 다음 계층적 클러스터링을 수행하여 동일한 개체의 세그먼트를 개체 제안으로 결합하는 작업을 수행합니다.



선택적 검색에서 검색된 ROI를 보완하기 위해 여러 눈금 및 가로 세로 비율로 이미지를 균일하게 커버하는 ROI를 추가합니다. 왼쪽 이미지는 선택적 검색의 예제 출력을 보여 하며, 각 가능한 개체 위치는 녹색 사각형으로 시각화됩니다. 너무 작고 너무 큰 ROI는 삭제되고(가운데) 마지막으로 이미지를 균일하게 덮는 ROI가 추가됩니다(오른쪽). 그런 다음 이러한 사각형은 R-CNN 파이프라인에서 ROI(Regions-of-Interests)로 사용됩니다.
ROI 생성의 목표는 이미지에서 가능한 한 많은 개체를 단단히 덮는 작은 ROI 집합을 찾는 것입니다. 이 계산은 충분히 빨라야 하며 동시에 서로 다른 눈금 및 가로 세로 비율로 개체 위치를 찾습니다. 선택적 검색은 이 작업에 대해 잘 수행되는 것으로 나타났으며, 절전 모드의 속도를 높이기 위해 정확도가 우수합니다.
NMS(최대 비표시)
개체 검색 방법은 이미지에서 동일한 개체를 완전히 또는 부분적으로 포함하는 여러 검색을 출력하는 경우가 많습니다.
개체 수를 계산하고 이미지에서 정확한 위치를 가져오려면 이러한 ROI를 병합해야 합니다.
이 작업은 일반적으로 NMS(Non Maximum Suppression)라는 기술을 사용하여 수행됩니다. 사용하는 NMS 버전(R-CNN 게시에서도 사용됨)은 ROI를 병합하지 않고 개체의 실제 위치를 가장 잘 다루는 ROI를 식별하여 다른 모든 ROI를 삭제합니다. 이는 신뢰도가 가장 높은 ROI를 반복적으로 선택하고 이 ROI와 상당히 겹치고 동일한 클래스로 분류되는 다른 모든 ROI를 제거하여 구현됩니다. 겹침에 대한 임계값을 설정할 PARAMETERS.py 수 있습니다(세부 정보).
검색 결과 앞(왼쪽) 및 후(오른쪽) 최대값이 아닌 표시 안 함:


mAP(평균 평균 정밀도)
일단 학습되면 정밀도, 재현율, 정확도, 영역 하부 곡선 등과 같은 다양한 조건을 사용하여 모델의 품질을 측정할 수 있습니다. Pascal VOC 개체 인식 챌린지에 사용되는 일반적인 메트릭은 각 클래스에 대한 AP(Average Precision)를 측정하는 것입니다. 평균 정밀도에 대한 다음 설명은 Everingham et. al에서 가져옵니다. 평균 평균 정밀도(mAP)는 모든 클래스의 평균을 계산하여 계산됩니다.
지정된 작업 및 클래스의 경우 정밀도/재현율 곡선은 메서드의 순위가 지정된 출력에서 계산됩니다. 재현율은 지정된 순위보다 높은 모든 긍정 예제의 비율로 정의됩니다. 전체 자릿수는 양수 클래스의 순위 위에 있는 모든 예제의 비율입니다. AP는 정밀도/재현율 곡선의 모양을 요약하고, 동일한 간격의 11개 재현율 수준[0,0.1] 집합에서 평균 정밀도로 정의됩니다. . . ,1]:
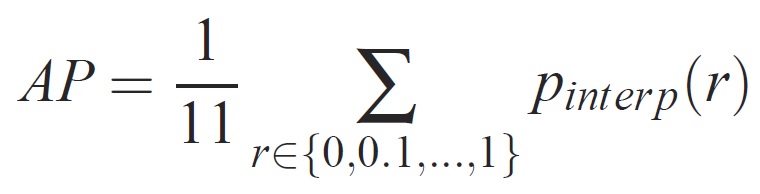
각 회수 수준 r의 정밀도는 해당 회수가 r을 초과하는 메서드에 대해 측정된 최대 정밀도를 사용하여 보간됩니다.
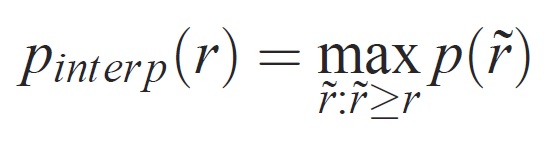
여기서 p(1r)는 리콜 시 측정된 정밀도입니다. 이러한 방식으로 정밀도/재현율 곡선을 보간하려는 의도는 예제 순위의 작은 변화로 인해 정밀도/재현율 곡선에서 "흔들기"의 영향을 줄이는 것입니다. 높은 점수를 얻으려면 메서드가 모든 수준의 리콜에서 정밀도를 가져야 합니다. 이렇게 하면 정밀도가 높은 예제의 하위 집합(예: 자동차의 측면 보기)만 검색하는 메서드가 불이익을 받습니다.