데이터 분석 워크로드에서 Azure Data Lake Storage Gen2 사용
Azure Data Lake Store Gen2는 여러 데이터 분석 사용 사례에 사용할 수 있는 기술입니다. 몇 가지 일반적인 유형의 분석 워크로드를 살펴보고 Azure Data Lake Storage Gen2가 다른 Azure 서비스와 함께 작동하여 이를 지원하는 방법을 알아보겠습니다.
빅 데이터 처리 및 분석
빅 데이터 시나리오는 일반적으로 빠른 속도로 처리해야 하는 다양한 형식의 대규모 데이터(소위 "3개의 v")를 포함하는 분석 워크로드를 참조합니다. Azure Data Lake Storage Gen 2는 Azure Synapse Analytics, Azure Databricks 및 Azure HDInsight와 같은 빅 데이터 서비스가 Apache Spark, Hive 및 Hadoop과 같은 데이터 처리 프레임워크를 적용할 수 있는 확장 가능하고 안전한 분산 데이터 저장소를 제공합니다. 스토리지 및 처리 컴퓨팅의 분산 특성을 통해 작업을 병렬로 수행할 수 있으므로 대량의 데이터를 처리하는 경우에도 고성능 및 확장성이 향상됩니다.
데이터 웨어하우징
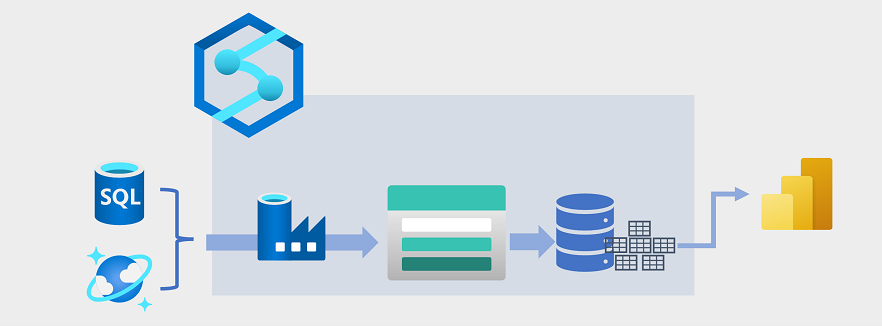
데이터 웨어하우징은 데이터 레이크에 파일로 저장된 대량의 데이터를 데이터 웨어하우스의 관계형 테이블과 통합하기 위해 최근 몇 년 동안 발전해 왔습니다. 데이터 웨어하우징 솔루션의 일반적인 예에서 데이터는 Azure SQL 데이터베이스 또는 Azure Cosmos DB와 같은 운영 데이터 저장소에서 추출되고 분석 워크로드에 더 적합한 구조로 변환됩니다. 관계형 데이터 웨어하우스에 로드되기 전에 분산 처리를 용이하게 하기 위해 데이터가 데이터 레이크에서 스테이징되는 경우가 많습니다. 경우에 따라 데이터 웨어하우스는 외부 테이블을 사용하여 데이터 레이크의 파일에 대한 관계형 메타데이터 계층을 정의하고 하이브리드 "데이터 레이크하우스" 또는 "레이크 데이터베이스" 아키텍처를 만듭니다. 그런 다음 데이터 웨어하우스는 보고 및 시각화에 대한 분석 쿼리를 지원할 수 있습니다.
이러한 종류의 데이터 웨어하우징 아키텍처를 구현하는 방법에는 여러 가지가 있습니다. 다이어그램은 Azure Synapse Analytics가 Azure Data Factory 기술을 사용하여 ETL(추출, 변환 및 로드) 프로세스를 수행하기 위해 파이프라인을 호스트하는 솔루션을 보여 줍니다. 이러한 프로세스는 운영 데이터 원본에서 데이터를 추출하고 Azure Data Lake Storage Gen2 컨테이너에 호스트되는 데이터 레이크에 로드합니다. 그런 다음 데이터는 처리되고 Microsoft Power BI를 사용하여 데이터 시각화 및 보고를 지원할 수 있는 Azure Synapse Analytics 전용 SQL 풀의 관계형 데이터 웨어하우스에 로드됩니다.
실시간 데이터 분석
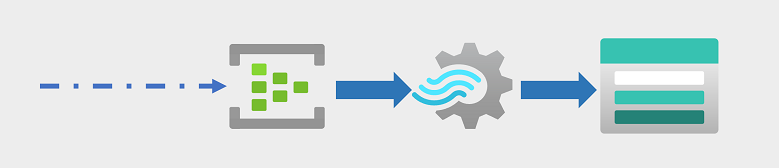
점점 더 많은 기업 및 기타 조직에서 영구 데이터 스트림을 캡처 및 분석하고 실시간으로(또는 가능한 한 실시간으로) 분석해야 합니다. 이러한 데이터 스트림은 연결된 디바이스(사물 인터넷 또는 IoT 디바이스라고도 함) 또는 소셜 미디어 플랫폼 또는 기타 애플리케이션의 사용자가 생성한 데이터에서 생성할 수 있습니다. 기존 일괄 처리 워크로드와 달리 스트리밍 데이터에는 데이터 이벤트가 발생할 때 무한한 데이터 스트림을 캡처하고 처리할 수 있는 솔루션이 필요합니다.
스트리밍 이벤트는 처리를 위해 큐에서 캡처되는 경우가 많습니다. 이미지에 표시된 대로 Azure Event Hubs 포함하여 이 작업을 수행하는 데 사용할 수 있는 여러 기술이 있습니다. 여기에서 데이터는 종종 임시 창을 통해 데이터를 집계하기 위해 처리됩니다(예: 지정된 태그가 있는 소셜 미디어 메시지 수를 5분마다 계산하거나 분당 인터넷에 연결된 센서의 평균 읽기를 계산하는 경우). Azure Stream Analytics를 사용하면 이벤트 데이터가 도착할 때 쿼리 및 집계하는 작업을 만들고 결과를 출력 싱크에 쓸 수 있습니다. 이러한 싱크 중 하나는 캡처된 실시간 데이터를 분석하고 시각화할 수 있는 Azure Data Lake Storage Gen2입니다.
데이터 과학 및 기계 학습

데이터 과학에는 대용량 데이터의 통계 분석이 포함되며, 종종 Apache Spark와 같은 도구 및 Python과 같은 스크립팅 언어를 사용합니다. Azure Data Lake Storage Gen 2는 데이터 과학 워크로드에 필요한 대량의 데이터에 대해 확장성이 뛰어난 클라우드 기반 데이터 저장소를 제공합니다.
기계 학습은 데이터 과학의 하위 집합으로, 예측 모델링을 다룹니다. 모델 학습에는 엄청난 양의 데이터와 해당 데이터를 효율적으로 처리할 수 있는 기능이 필요합니다. Azure Machine Learning은 데이터 과학자가 동적으로 할당된 분산 컴퓨팅 리소스를 사용하여 Notebook에서 Python 코드를 실행할 수 있는 클라우드 서비스입니다. 컴퓨팅은 Azure Data Lake Storage Gen2 컨테이너의 데이터를 처리하여 모델을 학습시킨 다음, 예측 분석 워크로드를 지원하기 위해 프로덕션 웹 서비스로 배포할 수 있습니다.