노드 준비 안 됨 오류의 기본 문제 해결
이 문서에서는 실패 후 AKS(Microsoft Azure Kubernetes Service) 클러스터 노드를 복구하는 문제 해결 단계를 제공합니다. 이 문서에서는 특히 노드 준비 안 됨 오류가 발생할 때 생성되는 가장 일반적인 오류 메시지를 설명하고 Windows 및 Linux 노드 모두에 대해 노드 복구 기능을 수행하는 방법을 설명합니다.
시작하기 전에
Kubernetes 클러스터 문제 해결을 위한 공식 가이드를 읽어보세요. 또한 Kubernetes 문제 해결에 대한 Microsoft 엔지니어의 가이드를 읽어보세요. 이 가이드에는 Pod, 노드, 클러스터 및 기타 기능 문제를 해결하기 위한 명령이 포함되어 있습니다.
필수 조건
- Azure CLI, 버전 2.31 이상. Azure CLI가 이미 설치된 경우 실행
az --version하여 버전 번호를 찾을 수 있습니다.
기본 문제 해결
AKS는 작업자 노드의 상태를 지속적으로 모니터링하고 비 정상 상태가 되면 노드를 자동으로 복구 합니다. Azure VM(Virtual Machine) 플랫폼 은 문제가 발생하는 VM을 유지 관리합니다 . AKS와 Azure VM은 함께 작동하여 클러스터의 서비스 중단을 줄입니다.
노드의 경우 두 가지 형태의 하트비트가 있습니다.
개체의 .status 로
Node업데이트됩니다.kube-node-lease 네임스페이스 내의 임대 개체입니다. 각
Node개체에는 연결된 개체가Lease있습니다.
.status Node 에 대한 업데이트와 비교할 때 a Lease 는 간단한 리소스입니다. 하트비트에 개체를 사용하면 Lease 대규모 클러스터에 대한 이러한 업데이트의 성능 영향을 줄일 수 있습니다.
kubelet은 개체에 대한 .status Node 를 만들고 업데이트하는 역할을 담당합니다. 또한 개체와 관련된 개체를 Lease 업데이트해야 합니다 Node .
- kubelet은 상태가 변경되거나 구성된 간격에 대한 업데이트가 없는 경우 노드
.status를 업데이트합니다. 노드 업데이트의.status기본 간격은 5분으로, 연결할 수 없는 노드의 기본 제한 시간인 40초보다 훨씬 깁니다. - kubelet은 10초마다 개체를 만들고 업데이트합니다
Lease(기본 업데이트 간격).Lease업데이트는 노드.status에 대한 업데이트와 독립적으로 수행됩니다. 업데이트가Lease실패하면 kubelet은 200밀리초에서 시작하여 7초로 제한되는 지수 백오프를 사용하여 다시 시도합니다.
상태 NotReady 또는 UnknownPod가 있는 노드에서는 Pod를 예약할 수 없습니다. 상태에 있는 노드에서만 Pod를 예약할 Ready 수 있습니다.
노드가 상태 또는 PIDPressure 상태인 경우 노드에서 MemoryPressureDiskPressure추가 Pod를 예약하기 위해 리소스를 관리해야 합니다. 노드가 모드인 NetworkUnavailable 경우 노드에서 네트워크를 올바르게 구성해야 합니다.
AKS는 에이전트 노드의 수명 주기 및 작업을 관리합니다. 에이전트 노드와 연결된 IaaS 리소스 수정은 지원되지 않습니다. 예를 들어 SSH 연결을 통해 노드를 사용자 지정하거나, 패키지를 업데이트하거나, 노드에서 네트워크 구성을 변경하는 것은 지원되지 않습니다. 자세한 내용은 에이전트 노드에 대한 AKS 지원 범위를 참조 하세요.
다음 조건이 충족되는지 확인합니다.
클러스터가 성공(실행 중) 상태입니다. Azure Portal에서 클러스터 상태를 확인하려면 Kubernetes 서비스를 검색하여 선택하고 AKS 클러스터의 이름을 선택합니다. 그런 다음 클러스터의 개요 페이지에서 Essentials를 확인하여 상태를 찾습니다. 또는 Azure CLI에서 az aks show 명령을 입력합니다.
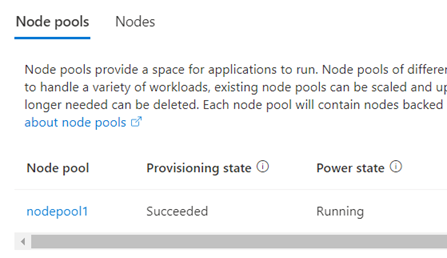
노드 풀의 프로비전 상태가 성공 상태이고 실행 중 전원 상태가 있습니다. Azure Portal에서 노드 풀 상태를 확인하려면 AKS 클러스터의 페이지로 돌아가서 노드 풀을 선택합니다. 또는 Azure CLI에서 az aks nodepool show 명령을 입력합니다.
필요한 송신 포트는 API 서버의 IP 주소에 연결할 수 있도록 NSG(네트워크 보안 그룹) 및 방화벽에서 열립니다. 자세한 내용은 AKS 클러스터에 대한 필수 아웃바운드 네트워크 규칙 및 FQDN을 참조하세요.
노드에서 최신 노드 이미지를 배포했습니다.
노드가
Running대신StoppedDeallocated또는 .클러스터에서 AKS 지원 버전의 Kubernetes를 실행하고 있습니다.
자세한 정보
노드의 Not Ready 상태를 해결하려면 정상 노드에서 준비되지 않음 상태로 변경 문제 해결을 참조하세요.
타사 연락처 고지
이 문서에 포함된 타사의 연락처 정보는 이 항목에 대한 추가 정보를 찾는 데 도움을 주기 위한 것입니다. 이 연락처 정보는 공지 없이 변경될 수 있습니다. Microsoft는 타사 연락처 정보의 정확성을 보증하지 않습니다.