Go from Zero to Big Data in 15 Minutes with Azure Hortonworks Sandbox
If you've been wondering how to get started with Big Data solutions and not really sure where to go then Microsoft Azure has a solution that will get you going in less than 15 minutes. The Hortonworks Sandbox has tonnes of tutorials built in and you can create a sandbox environment on Azure with just a few clicks. So here is how to get going:
- Create a Sandbox VM using this marketplace link. Clicking the 'Create Virtual Machine' button will open the Azure management portal and allow you to create the virtual machine in your subscription. You can use 'Resource Manager' or Classic as the deployment model and then fill out the rest of the details including networking, instance size and resource group. I would recommend you create a new resource group just for this sandbox as a number of resources will be created as well as the VM and this is a good way of logically grouping them together, either to tear down later or apply role based access to everything associated with this sandbox. Note: There is no license charge for the Sandbox but you will be charged for the VM instance size that you choose.
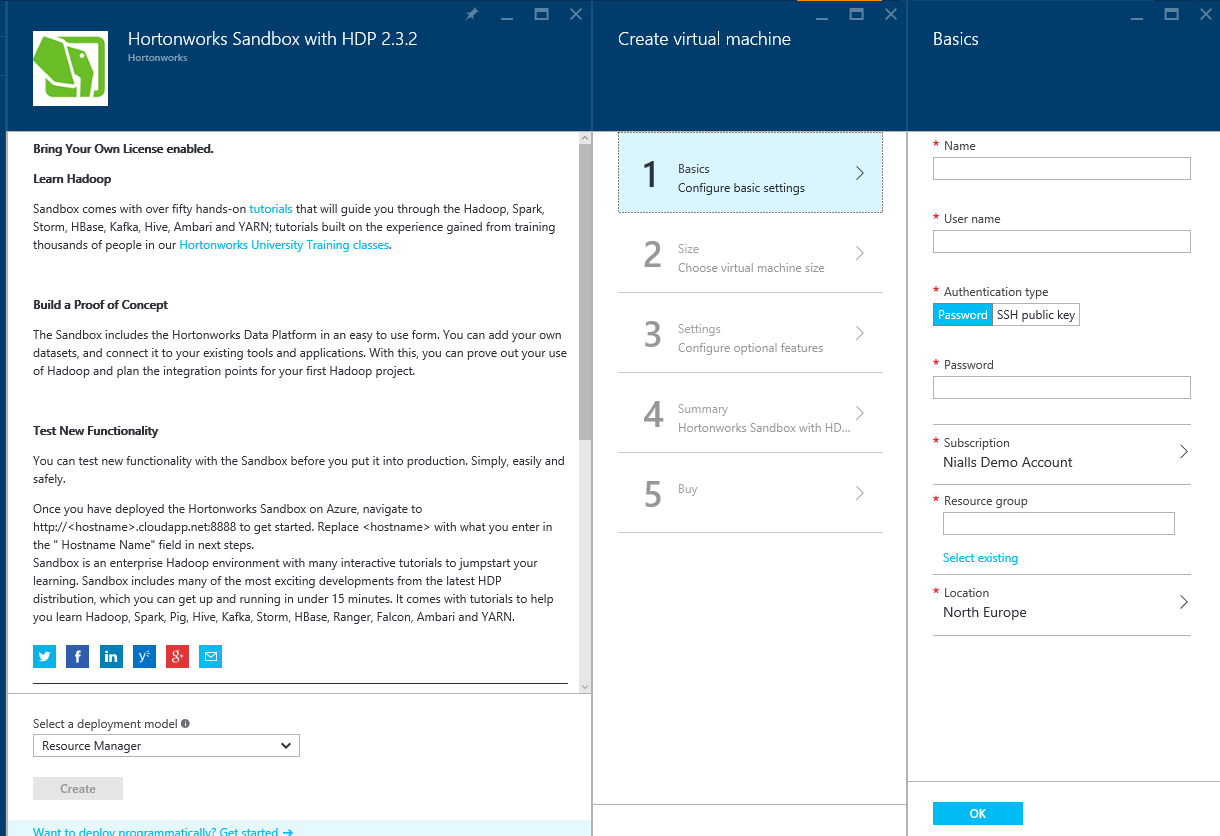
- Once you have filled out the details click to create the VM and then click on the VM to open its properties blade. When you create a VM it will have a tile on the home screen, clicking this will open the properties blade, otherwise you can simply browse for the VM using the left menu or search box in the top right of the portal.
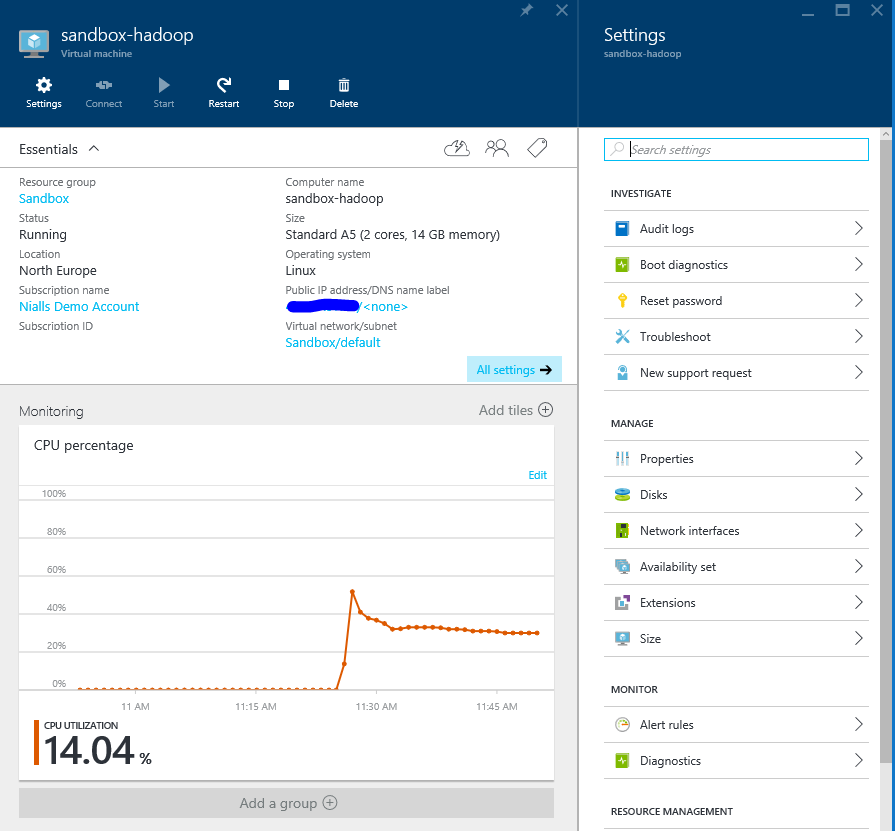
- Once the status of the VM is 'running' take note of the public IP address from the properties blade.
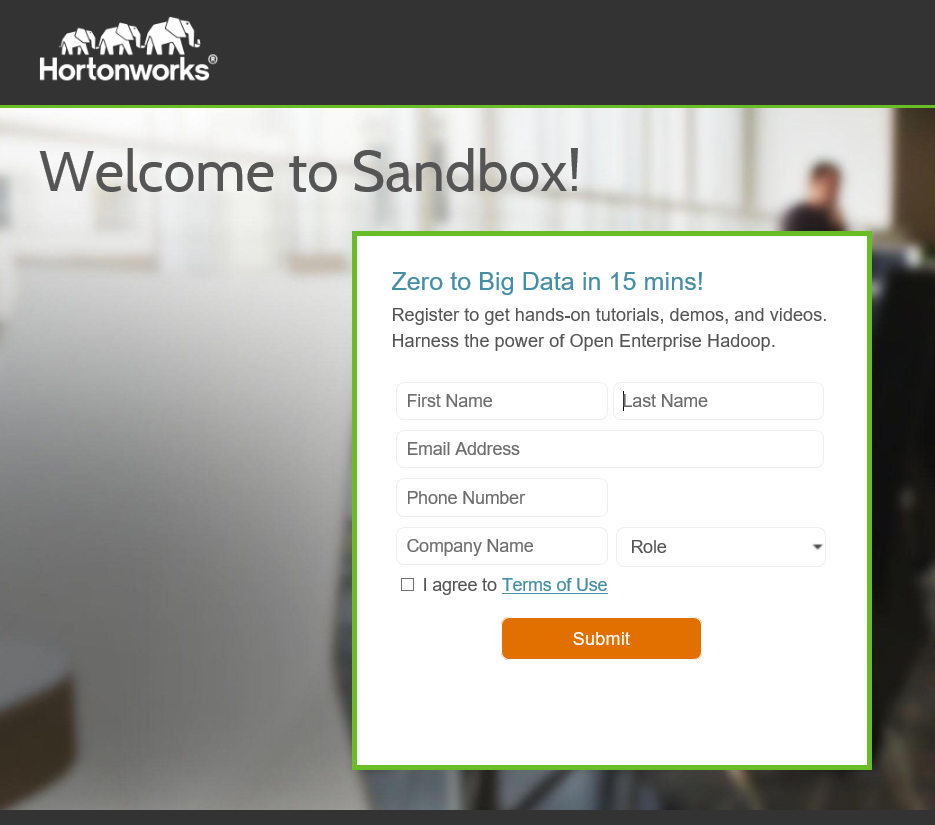
- Now using your favourite browser navigate to the URL: https://publicip:8888. Using the public IP noted above. This will bring you to the Hortonworks welcome page. Simply fill out the form to activate the Sandbox.
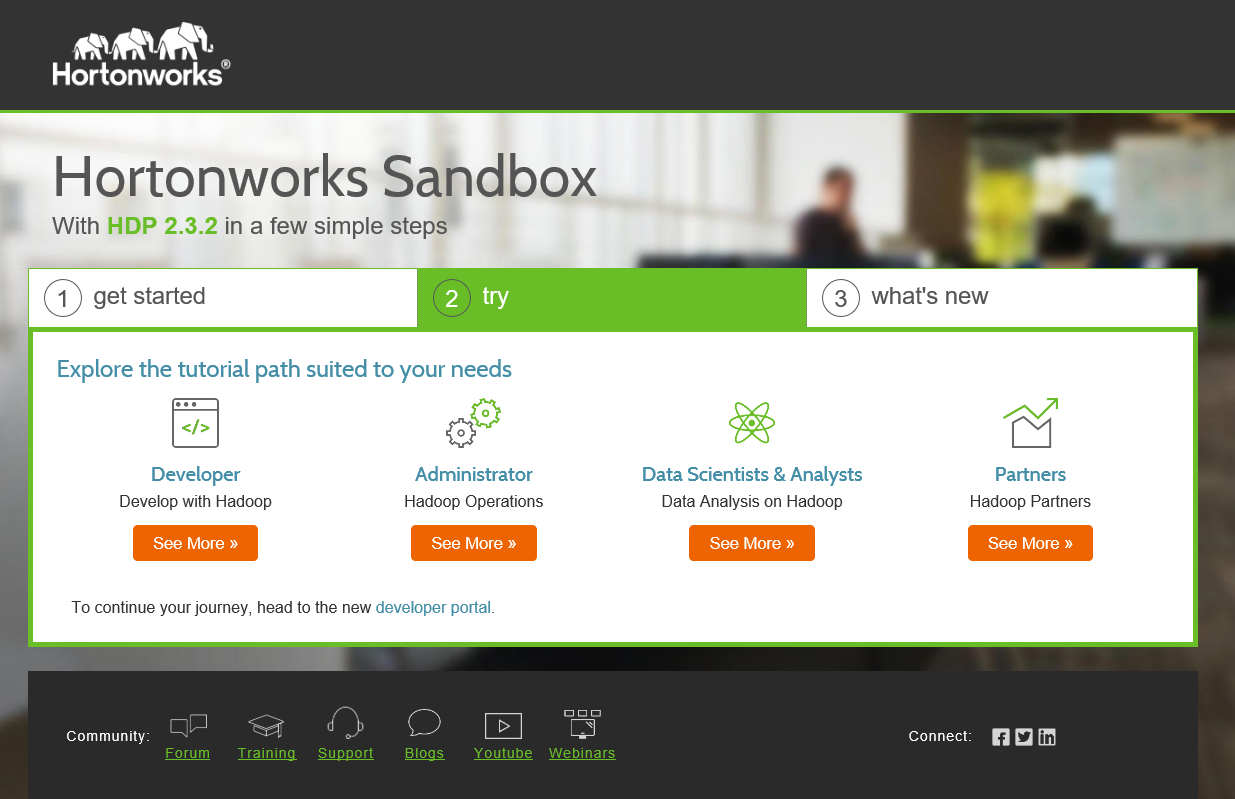
- Next you will be brought to the getting started screen and you are now setup to learn Hadoop as well as a tonne of technologies that can be used with it. The first screen offers a very simple Hello World tutorial which is a good place to start.
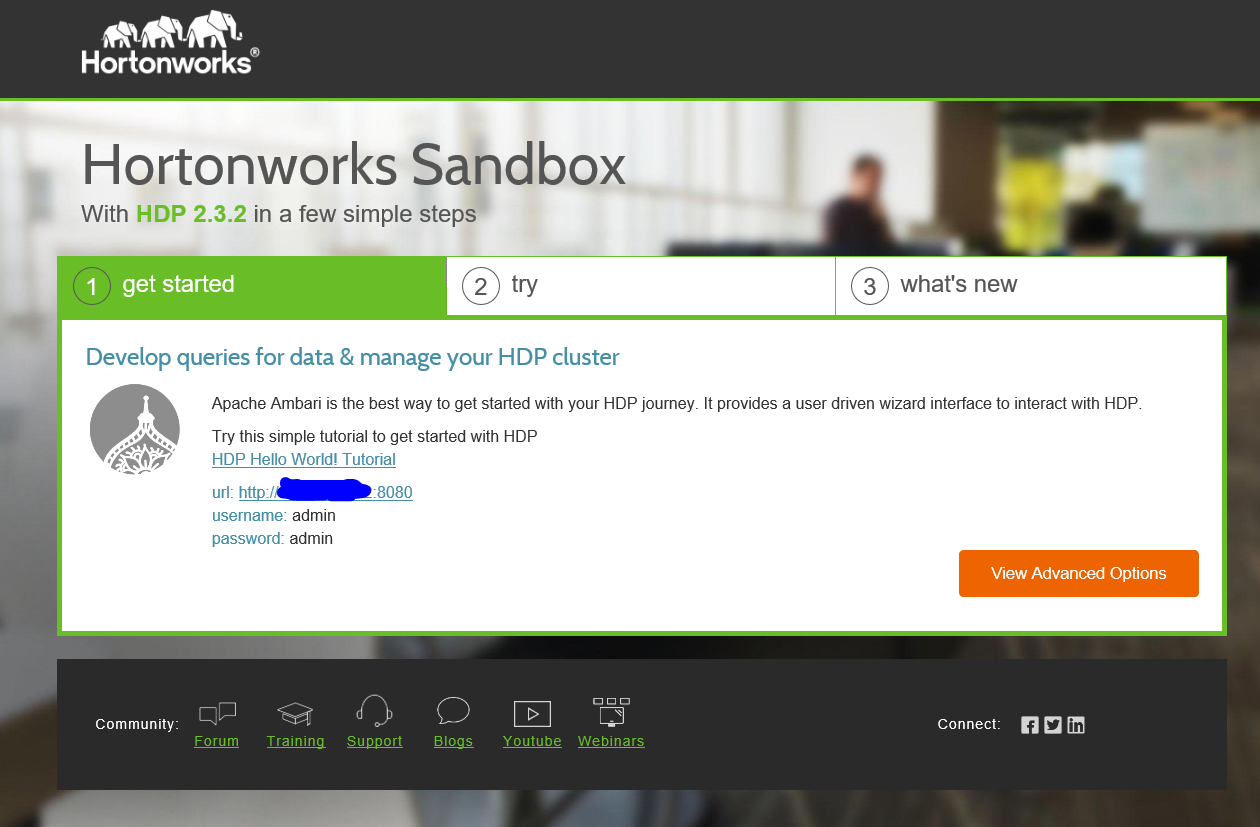
- Once you have that done why not try some of the more advanced tutorials or use the second tab to select a path best suited to your role.
This is a great way to learn and get started. If you decide to use Hadoop in production you could look at HDinsight a fully managed Hadoop service.
NOTES: A couple of issues I had during my tutorials and how I fixed them. You may not have similar issues but if you do hopefully these tips will help:
- If you get out of memory errors when running your Hive queries then increase the Tez container size to 1024 or 2048 in the config settings for Hive.
- If you find that your queries stay at 0% for a long time, this is not normal. They should execute quite quickly. In my case the only way I could get them to run (the ones that did grouping) was to change the execution engine to MapReduce from Tez. So in the Hive query editor I used the gear icon to the right of the editor to add hive.execution.engine as MR and then clicked 'save default setting' option to remember this for all of my queries.
- Based on comment below from Daragh try azure/azure for the Ambari UI if admin/admin doesn't work for username and password
Comments
Anonymous
January 10, 2016
Thanks Niall, that's very useful information.Anonymous
February 09, 2016
hi Niall, thanks for makeing this available. One tricky point was that the ambari dashboard password is not admin/admin as indicated on the web portal. Instead its azure/azure , that gives access to ambari dashboard. Community post indicates that will be fixed in next sandbox. br, DaraghAnonymous
February 09, 2016
Hi @Daragh, I used admin/admin myself, but I will update the post to keep an eye for this. Thanks for the comment Niall