Co to jest transkrypcja spotkań? (wersja zapoznawcza)
Transkrypcja spotkań to rozwiązanie zamiany mowy na tekst , które zapewnia transkrypcję w czasie rzeczywistym lub asynchroniczną dowolnego spotkania. Ta funkcja, która jest obecnie dostępna w wersji zapoznawczej, łączy rozpoznawanie mowy, identyfikację osoby mówiącej i przypisywanie zdań w celu określenia, kto powiedział, co i kiedy, na spotkaniu.
Ważne
Nazwa byłego scenariusza "transkrypcji konwersacji" została zmieniona na "transkrypcja spotkań". Na przykład użyj polecenia MeetingTranscriber zamiast ConversationTranscriber, a nie CreateConversationAsync.CreateMeetingAsync Nowa funkcja "transkrypcji konwersacji" jest udostępniana bez korzystania z profilów użytkowników i podpisów głosowych. Aby uzyskać więcej informacji, zobacz informacje o wersji.
Kluczowe cechy i funkcje
Przydatne mogą być następujące funkcje transkrypcji spotkań:
- Znaczniki czasu: Każda wypowiedź osoby mówiącej ma sygnaturę czasową, dzięki czemu można łatwo znaleźć, kiedy fraza została powiedziana.
- Transkrypcje z możliwością odczytu: Transkrypcje mają automatycznie dodane formatowanie i znaki interpunkcyjne, aby upewnić się, że tekst jest ściśle zgodny z tym, co zostało powiedziane.
- Profile użytkowników: profile użytkowników są generowane przez zbieranie przykładów głosowych użytkowników i wysyłanie ich do generowania podpisów.
- Identyfikacja osoby mówiącej: osoby mówiące są identyfikowane przy użyciu profilów użytkowników, a do każdego z nich jest przypisany identyfikator osoby mówiącej.
- Diaryzacja z wieloma głośnikami: określ, kto powiedział, co powiedział, syntetyzując strumień audio przy użyciu każdego identyfikatora osoby mówiącej.
- Transkrypcja w czasie rzeczywistym: podaj transkrypcje na żywo, kto mówi, co i kiedy, podczas spotkania.
- Transkrypcja asynchroniczna: podaj transkrypcje z większą dokładnością przy użyciu strumienia audio z wieloma kanałami.
Uwaga
Chociaż transkrypcja spotkań nie ogranicza liczby osób mówiących w pomieszczeniu, jest zoptymalizowana pod kątem 2–10 głośników na sesję.
Rozpocznij
Zobacz przewodnik Szybki start dotyczący transkrypcji spotkań w czasie rzeczywistym, aby rozpocząć pracę.
Przypadki użycia
Aby spotkania były integracyjne dla wszystkich, takich jak uczestnicy, którzy są głuchi i trudne do słuchu, ważne jest, aby transkrypcja była w czasie rzeczywistym. Transkrypcja spotkania w trybie czasu rzeczywistego pobiera dźwięk spotkania i określa, kto mówi, co, dzięki czemu wszyscy uczestnicy spotkania mogą śledzić transkrypcję i uczestniczyć w spotkaniu bez opóźnień.
Uczestnicy spotkania mogą skupić się na spotkaniu i pozostawić notatkę do transkrypcji spotkania. Uczestnicy mogą aktywnie zaangażować się w spotkanie i szybko wykonać kolejne kroki, korzystając z transkrypcji zamiast robienia notatek i potencjalnie brakuje czegoś podczas spotkania.
Jak to działa
Na poniższym diagramie przedstawiono ogólny przegląd sposobu działania funkcji.
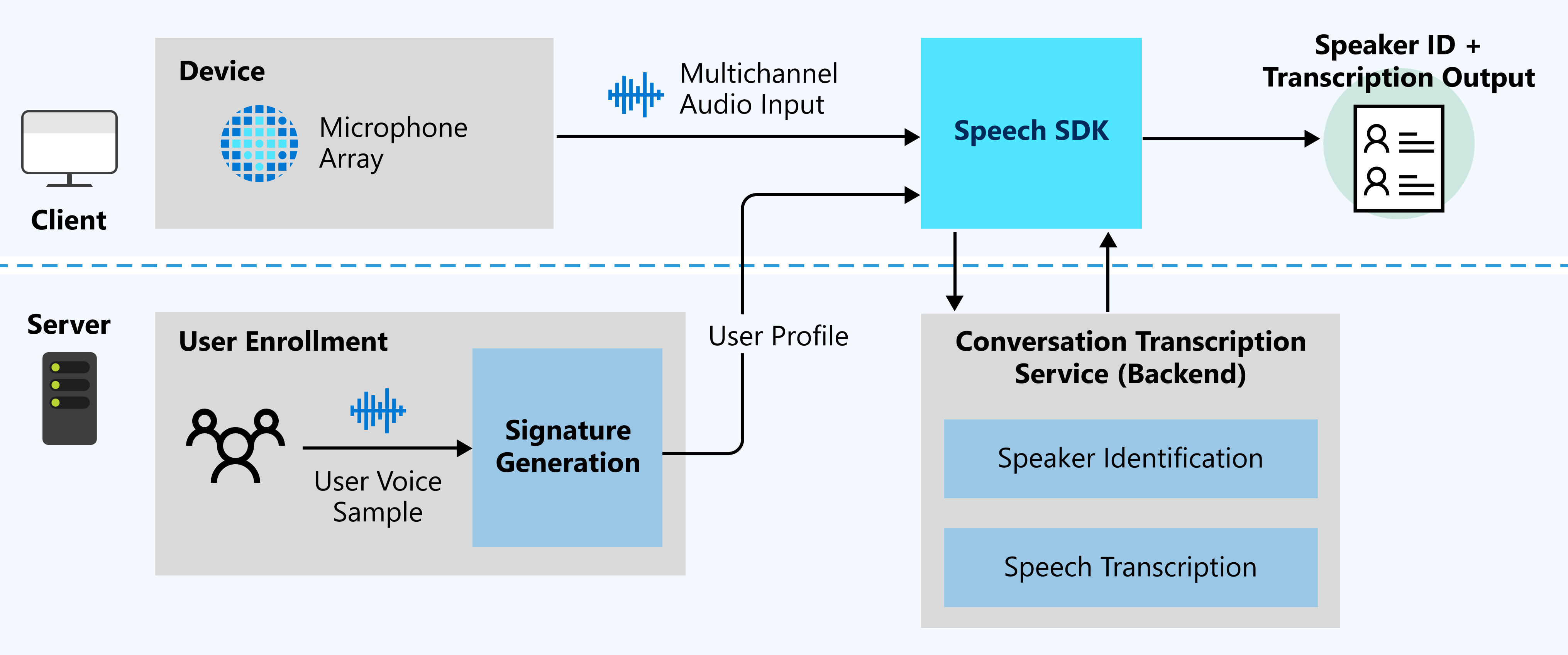
Oczekiwane dane wejściowe
Transkrypcja spotkania używa dwóch typów danych wejściowych:
- Strumień audio z wieloma kanałami: aby uzyskać szczegółowe informacje o specyfikacji i projekcie, zobacz Zalecenia dotyczące tablicy mikrofonów.
- Przykłady głosu użytkownika: Transkrypcja spotkań wymaga profilów użytkowników przed rozmową na potrzeby identyfikacji osoby mówiącej. Zbierz nagrania audio od każdego użytkownika, a następnie wyślij nagrania do usługi generowania podpisów, aby zweryfikować dźwięk i wygenerować profile użytkowników.
Uwaga
Konfiguracja dźwięku pojedynczego kanału na potrzeby transkrypcji spotkania jest obecnie dostępna tylko w prywatnej wersji zapoznawczej.
Przykłady głosu użytkownika dla podpisów głosowych są wymagane do identyfikacji osoby mówiącej. Prelegenci, którzy nie mają próbek głosowych, są rozpoznawani jako niezidentyfikowani. Niezidentyfikowane głośniki mogą być nadal rozróżniane, gdy DifferentiateGuestSpeakers właściwość jest włączona (zobacz poniższy przykład). Następnie dane wyjściowe transkrypcji przedstawiają osoby mówiące jako Guest_0 i Guest_1, zamiast rozpoznawać je jako wstępnie zarejestrowane nazwy osób mówiących.
config.SetProperty("DifferentiateGuestSpeakers", "true");
Czas rzeczywisty a asynchroniczny
Poniższe sekcje zawierają więcej szczegółowych informacji na temat trybów transkrypcji, które można wybrać.
W czasie rzeczywistym
Dane audio są przetwarzane na żywo w celu zwrócenia identyfikatora osoby mówiącej i transkrypcji. Wybierz ten tryb, jeśli wymaganie dotyczące rozwiązania transkrypcji polega na udostępniniu uczestnikom spotkania na żywo wgląd w bieżące spotkanie. Na przykład utworzenie aplikacji w celu zwiększenia dostępności spotkań dla uczestników z utratą słuchu lub głuchotą jest idealnym przypadkiem użycia dla transkrypcji w czasie rzeczywistym.
Asynchroniczny
Dane audio są przetwarzane wsadowe w celu zwrócenia identyfikatora i transkrypcji osoby mówiącej. Wybierz ten tryb, jeśli wymaganie rozwiązania transkrypcji ma zapewnić większą dokładność bez widoku transkrypcji na żywo. Jeśli na przykład chcesz utworzyć aplikację, aby umożliwić uczestnikom spotkania łatwe nadrobienie zaległych spotkań, użyj trybu transkrypcji asynchronicznej, aby uzyskać wyniki transkrypcji o wysokiej dokładności.
Asynchroniczna i asynchroniczna w czasie rzeczywistym
Dane audio są przetwarzane na żywo w celu zwrócenia identyfikatora i transkrypcji osoby mówiącej, a ponadto żądania transkrypcji o wysokiej dokładności za pośrednictwem przetwarzania asynchronicznego. Wybierz ten tryb, jeśli aplikacja potrzebuje transkrypcji w czasie rzeczywistym, a także wymaga wyższej dokładności transkrypcji do użycia po wystąpieniu spotkania.
Obsługa języków
Obecnie transkrypcja spotkań obsługuje wszystkie języki zamiany mowy na języki tekstowe w następujących regionach: centralus, , eastasiaeastus, westeurope.