Aplikacje danych (wyrównane do źródła)
Jeśli nie chcesz implementować aparatu niezależnego od danych do pozyskiwania danych raz ze źródeł operacyjnych lub jeśli złożone połączenia nie są obsługiwane w agnostyce danych, należy utworzyć aplikację danych, która jest wyrównana do źródła. Podczas pozyskiwania danych z zewnętrznych źródeł danych powinien on być zgodny z tym samym przepływem.
Omówienie
Grupa zasobów aplikacji jest odpowiedzialna za pozyskiwanie i wzbogacanie danych tylko ze źródeł zewnętrznych, takich jak telemetria, finanse lub CRM. Ta warstwa może działać w czasie rzeczywistym, wsadowym i mikrosadowym.
W tej sekcji opisano infrastrukturę wdrożoną dla każdej grupy zasobów aplikacji danych (dostosowanej do źródła) wewnątrz strefy docelowej danych.
Porada
W przypadku siatki danych można wybrać wdrożenie jednego ze źródeł lub jednego na domenę. Należy nadal przestrzegać zasad standaryzacji danych, jakości danych i pochodzenia danych. Zespoły ds. operacji platformy danych mogą opracowywać fragmenty kodu standardowego i wzywać ich do osiągnięcia tego celu.
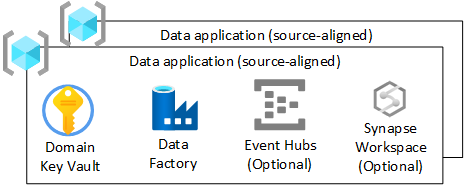
Dla każdej grupy zasobów aplikacji danych (dostosowanej do źródła) w strefie docelowej danych należy utworzyć:
- Azure Key Vault
- Azure Data Factory do uruchamiania opracowanych potoków inżynieryjnych, które przekształcają dane z nieprzetworzonych na wzbogacone
- Jednostka usługi używana przez aplikację danych (wyrównana do źródła) do wdrażania zadań pozyskiwania w usłudze Azure Databricks (tylko w przypadku korzystania z usługi Azure Databricks)
Możesz również tworzyć wystąpienia innych usług, takich jak Azure Event Hubs, Azure IoT Hub, Azure Stream Analytics i Azure Machine Learning.
Uwaga
Aby wymusić standard delta lake, musisz użyć aparatu spark, takiego jak Azure Synapse Spark lub Azure Databricks.
Jeśli zdecydujesz się na korzystanie z usługi Azure Databricks, zalecamy wdrożenie Azure Data Factory, a nie Azure Synapse Obszaru roboczego usługi Analytics, aby zmniejszyć obszar powierzchni tylko do wymaganych funkcji.
Jeśli jednak potrzebujesz całego obszaru projektowego z potokami i platformą Spark, użyj usługi Azure Synapse Analytics. Zastosuj zasady, aby zezwolić tylko na używanie platformy Spark i potoków, aby uniknąć tworzenia silosów w puli Azure Synapse SQL.
Azure Key Vault
Korzystanie z funkcji usługi Azure Key Vault do przechowywania wpisów tajnych na platformie Azure, gdy tylko jest to możliwe.
Każda aplikacja danych (wyrównana do źródła) grupa zasobów lub domena danych (jeśli siatka) będzie mieć Key Vault Platformy Azure. Dzięki temu klucz szyfrowania, wpis tajny i wyprowadzanie certyfikatu spełniają wymagania środowiska. Pozwala to na lepsze rozdzielenie obowiązków administracyjnych, a także zmniejsza ryzyko mieszania kluczy, integracji i wpisów tajnych różnych klasyfikacji.
Wszystkie klucze dotyczące aplikacji danych (dostosowane do źródła) powinny być zawarte w usłudze Azure Key Vault.
Ważne
Magazyny kluczy aplikacji danych (dostosowane do źródła) powinny być zgodne z modelem najniższych uprawnień i powinny unikać zarówno limitów skalowania transakcji, jak i udostępniania wpisów tajnych w różnych środowiskach.
Azure Data Factory
Wdróż Azure Data Factory, aby umożliwić potokom napisanym przez zespół aplikacji danych zbieranie danych z danych pierwotnych do wzbogaconych przy użyciu opracowanych potoków. Użyj przepływów danych mapowania na potrzeby przekształceń i podziel się, aby używać obszaru roboczego usługi Azure Databricks (pozyskiwania) lub Azure Synapse Platformy Spark na potrzeby złożonych przekształceń.
Należy połączyć Azure Data Factory z wystąpieniem metodyki DevOps repozytorium aplikacji danych (wyrównane do źródła). To połączenie umożliwia wdrożenia ciągłej integracji/ciągłego wdrażania.
Event Hubs
Jeśli aplikacja danych (wyrównana do źródła) ma wymóg przesyłania strumieniowego danych, możesz wdrożyć podrzędne usługi Event Hubs w grupie zasobów aplikacji danych (dostosowanej do źródła).