Najlepsze rozwiązania dotyczące projektów nauki o danych z analizą w skali chmury na platformie Azure
Zalecamy te najlepsze rozwiązania dotyczące używania analizy w skali chmury na platformie Microsoft Azure do operacjonalizacji projektów nauki o danych.
Tworzenie szablonu
Tworzenie szablonu, który zawiera zestaw usług dla projektów nauki o danych. Użyj szablonu, który zawiera zestaw usług, aby zapewnić spójność w różnych przypadkach użycia zespołów nauki o danych. Zalecamy opracowanie spójnej strategii w postaci repozytorium szablonów. Tego repozytorium można użyć dla różnych projektów nauki o danych w przedsiębiorstwie, aby skrócić czas wdrażania.
Wskazówki dotyczące szablonów nauki o danych
Utwórz szablon nauki o danych dla organizacji, postępując zgodnie z następującymi wytycznymi:
Opracowywanie zestawu szablonów infrastruktury jako kodu (IaC) w celu wdrożenia obszaru roboczego usługi Azure Machine Edukacja. Uwzględnij zasoby, takie jak magazyn kluczy, konto magazynu, rejestr kontenerów i Szczegółowe informacje aplikacji.
Uwzględnij konfigurację magazynów danych i docelowych obiektów obliczeniowych w tych szablonach, takich jak wystąpienia obliczeniowe, klastry obliczeniowe i usługa Azure Databricks.
Najlepsze praktyki dotyczące wdrażania
W czasie rzeczywistym
- Uwzględnij wdrożenie usługi Azure Data Factory lub Azure Synapse w szablonach i usługach Azure Cognitive Services.
- Szablony powinny dostarczać wszystkie niezbędne narzędzia do wykonywania fazy eksploracji nauki o danych i początkowej operacji modelu.
Zagadnienia dotyczące konfiguracji początkowej
W niektórych przypadkach analitycy danych w organizacji mogą wymagać środowiska do szybkiej analizy zgodnie z potrzebami. Taka sytuacja jest powszechna, gdy projekt nauki o danych nie jest formalnie skonfigurowany. Na przykład menedżer projektu, kod kosztów lub centrum kosztów, które mogą być wymagane do krzyżowego ładowania na platformie Azure, może brakować, ponieważ brakujący element wymaga zatwierdzenia. Użytkownicy w organizacji lub zespole mogą potrzebować dostępu do środowiska nauki o danych, aby zrozumieć dane i ewentualnie ocenić wykonalność projektu. Ponadto niektóre projekty mogą nie wymagać pełnego środowiska nauki o danych z powodu niewielkiej liczby produktów danych.
W innych przypadkach może być wymagany pełny projekt nauki o danych wraz z dedykowanym środowiskiem, zarządzaniem projektami, kodem kosztów i centrum kosztów. Pełne projekty nauki o danych są przydatne dla wielu członków zespołu, którzy chcą współpracować, udostępniać wyniki i muszą operacjonalizować modele po pomyślnym zakończeniu fazy eksploracji.
Proces instalacji
Szablony powinny być wdrażane na podstawie poszczególnych projektów po ich skonfigurowaniu. Każdy projekt powinien otrzymywać co najmniej dwa wystąpienia dla środowisk deweloperskich i produkcyjnych, które mają być oddzielone. W środowisku produkcyjnym żadna osoba nie powinna mieć dostępu i wszystkie elementy powinny być wdrażane za pośrednictwem potoków ciągłej integracji lub ciągłego programowania i jednostki usługi. Te zasady środowiska produkcyjnego są ważne, ponieważ usługa Azure Machine Edukacja nie zapewnia szczegółowego modelu kontroli dostępu opartego na rolach w obszarze roboczym. Nie można ograniczyć dostępu użytkowników do określonego zestawu eksperymentów, punktów końcowych ani potoków.
Te same prawa dostępu są zwykle stosowane do różnych typów artefaktów. Ważne jest oddzielenie programowania od środowiska produkcyjnego, aby zapobiec usunięciu potoków produkcyjnych lub punktów końcowych w obszarze roboczym. Wraz z szablonem należy skompilować proces, aby umożliwić zespołom ds. produktów danych możliwość żądania nowych środowisk.
Zalecamy skonfigurowanie różnych usług sztucznej inteligencji, takich jak Azure Cognitive Services, na podstawie poszczególnych projektów. Konfigurując różne usługi sztucznej inteligencji dla poszczególnych projektów, wdrożenia są wykonywane dla każdej grupy zasobów produktu danych. Te zasady tworzą wyraźną separację od punktu widzenia dostępu do danych i ograniczają ryzyko nieautoryzowanego dostępu do danych przez niewłaściwe zespoły.
Scenariusz przesyłania strumieniowego
W przypadku przypadków użycia w czasie rzeczywistym i przesyłania strumieniowego wdrożenia powinny być testowane na niesualizowanej usłudze Azure Kubernetes Service (AKS). Testowanie może być w środowisku deweloperskim, aby zaoszczędzić na kosztach przed wdrożeniem w produkcyjnej usłudze AKS lub aplikacja systemu Azure Service dla kontenerów. Należy wykonać proste testy wejściowe i wyjściowe, aby upewnić się, że usługi reagują zgodnie z oczekiwaniami.
Następnie możesz wdrożyć modele w żądanej usłudze. Ten docelowy obiekt obliczeniowy wdrożenia jest jedynym, który jest ogólnie dostępny i zalecany dla obciążeń produkcyjnych w klastrze usługi AKS. Ten krok jest bardziej konieczny, jeśli wymagana jest obsługa układów procesora graficznego (GPU) lub programowalnej przez pole macierzy bramy. Inne natywne opcje wdrażania, które obsługują te wymagania sprzętowe, nie są obecnie dostępne w usłudze Azure Machine Edukacja.
Usługa Azure Machine Edukacja wymaga mapowania jeden do jednego w klastrach usługi AKS. Każde nowe połączenie z obszarem roboczym usługi Azure Machine Edukacja przerywa poprzednie połączenie między usługą AKS i usługą Azure Machine Edukacja. Po ograniczeniu tego ograniczenia zalecamy wdrożenie centralnych klastrów usługi AKS jako zasobów udostępnionych i dołączenie ich do odpowiednich obszarów roboczych.
Inne centralne wystąpienie usługi AKS powinno być hostowane, jeśli przed przeniesieniem modelu do produkcyjnego usługi AKS należy przeprowadzić testy obciążeniowe. Środowisko testowe powinno zapewnić ten sam zasób obliczeniowy co środowisko produkcyjne, aby upewnić się, że wyniki są jak najbardziej podobne do środowiska produkcyjnego.
Scenariusz usługi Batch
Nie wszystkie przypadki użycia wymagają wdrożeń klastra usługi AKS. Przypadek użycia nie wymaga wdrożenia klastra usługi AKS, jeśli duże ilości danych wymagają regularnego oceniania lub są oparte na zdarzeniu. Na przykład duże ilości danych mogą być oparte na tym, kiedy dane spadną na określone konto magazynu. Potoki usługi Azure Machine Edukacja i klastry obliczeniowe usługi Azure Machine Edukacja powinny być używane do wdrażania w tych typach scenariuszy. Te potoki powinny być orkiestrowane i wykonywane w usłudze Data Factory.
Identyfikowanie odpowiednich zasobów obliczeniowych
Przed wdrożeniem modelu w usłudze Azure Machine Edukacja w usłudze AKS użytkownik musi określić zasoby, takie jak procesor CPU, pamięć RAM i procesor GPU, które powinny zostać przydzielone dla odpowiedniego modelu. Definiowanie tych parametrów może być złożonym i żmudnym procesem. Należy przeprowadzić testy obciążeniowe z różnymi konfiguracjami, aby zidentyfikować dobry zestaw parametrów. Ten proces można uprościć za pomocą funkcji profilowania modelu w usłudze Azure Machine Edukacja, która jest długotrwałym zadaniem, które testuje różne kombinacje alokacji zasobów i używa zidentyfikowanego opóźnienia i czasu rundy (RTT), aby zalecić optymalną kombinację. Te informacje mogą pomóc w rzeczywistym wdrożeniu modelu w usłudze AKS.
Aby bezpiecznie aktualizować modele w usłudze Azure Machine Edukacja, zespoły powinny używać kontrolowanej funkcji wdrażania (wersja zapoznawcza), aby zminimalizować przestoje i zachować spójny punkt końcowy REST modelu.
Najlepsze rozwiązania i przepływ pracy dla metodyki MLOps
Dołączanie przykładowego kodu w repozytoriach nauki o danych
Możesz uprościć i przyspieszyć projekty nauki o danych, jeśli zespoły mają pewne artefakty i najlepsze rozwiązania. Zalecamy utworzenie artefaktów, których mogą używać wszystkie zespoły nauki o danych podczas pracy z usługą Azure Machine Edukacja i odpowiednimi narzędziami środowiska produktów danych. Inżynierowie zajmujący się danymi i uczeniem maszynowym powinni tworzyć i udostępniać artefakty.
Te artefakty powinny obejmować:
Przykładowe notesy pokazujące, jak:
- Ładowanie, instalowanie i praca z produktami danych.
- Metryki i parametry dziennika.
- Przesyłanie zadań szkoleniowych do klastrów obliczeniowych.
Artefakty wymagane do operacjonalizacji:
- Przykładowe potoki usługi Azure Machine Edukacja
- Przykładowe usługi Azure Pipelines
- Więcej skryptów wymaganych do wykonywania potoków
Dokumentacja
Używanie dobrze zaprojektowanych artefaktów do operacjonalizacji potoków
Artefakty mogą przyspieszyć fazy eksploracji i operacjonalizacji projektów nauki o danych. Strategia tworzenia rozwidlenie metodyki DevOps może pomóc w skalowaniu tych artefaktów we wszystkich projektach. Ponieważ ta konfiguracja promuje korzystanie z usługi Git, użytkownicy i ogólny proces automatyzacji mogą korzystać z dostarczonych artefaktów.
Napiwek
Przykładowe potoki usługi Azure Machine Edukacja powinny być tworzone przy użyciu zestawu SDK (Software Developer Kit) języka Python lub opartego na języku YAML. Nowe środowisko YAML będzie bardziej odporne na przyszłość, ponieważ zespół produktu Azure Machine Edukacja pracuje obecnie nad nowym zestawem SDK i interfejsem wiersza polecenia (CLI). Zespół produktu usługi Azure Machine Edukacja jest przekonany, że język YAML będzie służyć jako język definicji dla wszystkich artefaktów w usłudze Azure Machine Edukacja.
Przykładowe potoki nie działają w pudełku dla każdego projektu, ale mogą być używane jako plan bazowy. Możesz dostosować przykładowe potoki dla projektów. Potok powinien zawierać najbardziej istotne aspekty każdego projektu. Na przykład potok może odwoływać się do docelowego obiektu obliczeniowego, odwołać się do produktów danych, zdefiniować parametry, zdefiniować dane wejściowe i zdefiniować kroki wykonywania. Ten sam proces należy wykonać dla usługi Azure Pipelines. Usługa Azure Pipelines powinna również używać zestawu AZURE Machine Edukacja SDK lub interfejsu wiersza polecenia.
Potoki powinny pokazać, jak:
- Połączenie do obszaru roboczego z poziomu potoku DevOps.
- Sprawdź, czy wymagane zasoby obliczeniowe są dostępne.
- Prześlij zadanie.
- Rejestrowanie i wdrażanie modelu.
Artefakty nie są odpowiednie dla wszystkich projektów przez cały czas i mogą wymagać dostosowania, ale posiadanie podstaw może przyspieszyć operacjonalizacja i wdrażanie projektu.
Struktura repozytorium MLOps
Mogą wystąpić sytuacje, w których użytkownicy tracą śledzenie miejsca, w którym mogą znajdować i przechowywać artefakty. Aby uniknąć tych sytuacji, należy poprosić o więcej czasu na komunikowanie się i konstruowanie struktury folderów najwyższego poziomu dla standardowego repozytorium. Wszystkie projekty powinny być zgodne ze strukturą folderów.
Uwaga
Pojęcia wymienione w tej sekcji mogą być używane w środowiskach lokalnych, Amazon Web Services, Palantir i Azure.
Proponowana struktura folderów najwyższego poziomu dla repozytorium MLOps (operacje uczenia maszynowego) jest pokazana na poniższym diagramie:
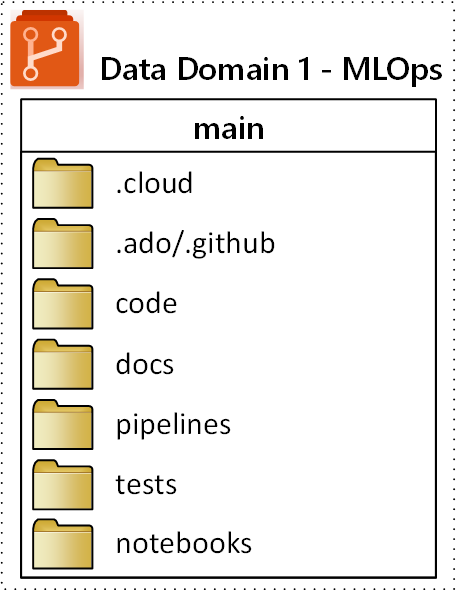
Następujące cele dotyczą każdego folderu w repozytorium:
| Folder | Purpose |
|---|---|
.cloud |
Przechowuj kod i artefakty specyficzne dla chmury w tym folderze. Artefakty obejmują pliki konfiguracji dla obszaru roboczego usługi Azure Machine Edukacja, w tym definicje obiektów docelowych obliczeń, zadania, zarejestrowane modele i punkty końcowe. |
.ado/.github |
Przechowuj artefakty usługi Azure DevOps lub GitHub, takie jak potoki YAML lub właściciele kodu w tym folderze. |
code |
Uwzględnij rzeczywisty kod opracowany w ramach projektu w tym folderze. Ten folder może zawierać pakiety języka Python i niektóre skrypty, które są używane do odpowiednich kroków potoku uczenia maszynowego. Zalecamy oddzielenie poszczególnych kroków, które należy wykonać w tym folderze. Typowe kroki to wstępne przetwarzanie, trenowanie modelu i rejestracja modelu. Zdefiniuj zależności, takie jak zależności Conda, obrazy platformy Docker lub inne dla każdego folderu. |
docs |
Ten folder służy do celów dokumentacji. W tym folderze są przechowywane pliki i obrazy języka Markdown w celu opisania projektu. |
pipelines |
Przechowywanie definicji potoków usługi Azure Machine Edukacja w języku YAML lub Python w tym folderze. |
tests |
Napisz testy jednostkowe i integracyjne, które należy wykonać w celu odnalezienia usterek i problemów na wczesnym etapie projektu w tym folderze. |
notebooks |
Oddziel notesy Jupyter od rzeczywistego projektu języka Python przy użyciu tego folderu. W folderze każda osoba powinna mieć podfolder, aby zaewidencjonować swoje notesy i zapobiec konfliktom scalania usługi Git. |