Konfigurowanie bramy sztucznej inteligencji w modelach obsługujących punkty końcowe
Z tego artykułu dowiesz się, jak skonfigurować bramę mozaiki AI w punkcie końcowym obsługującym model.
Wymagania
- Obszar roboczy usługi Databricks w obsługiwanym regionie obsługa modelu.
- Wykonaj kroki 1 i 2 sekcji Tworzenie punktu końcowego obsługującego model zewnętrzny.
Konfigurowanie bramy sztucznej inteligencji przy użyciu interfejsu użytkownika
Poniżej przedstawiono sposób konfigurowania bramy sztucznej inteligencji podczas tworzenia punktu końcowego przy użyciu interfejsu użytkownika obsługującego.
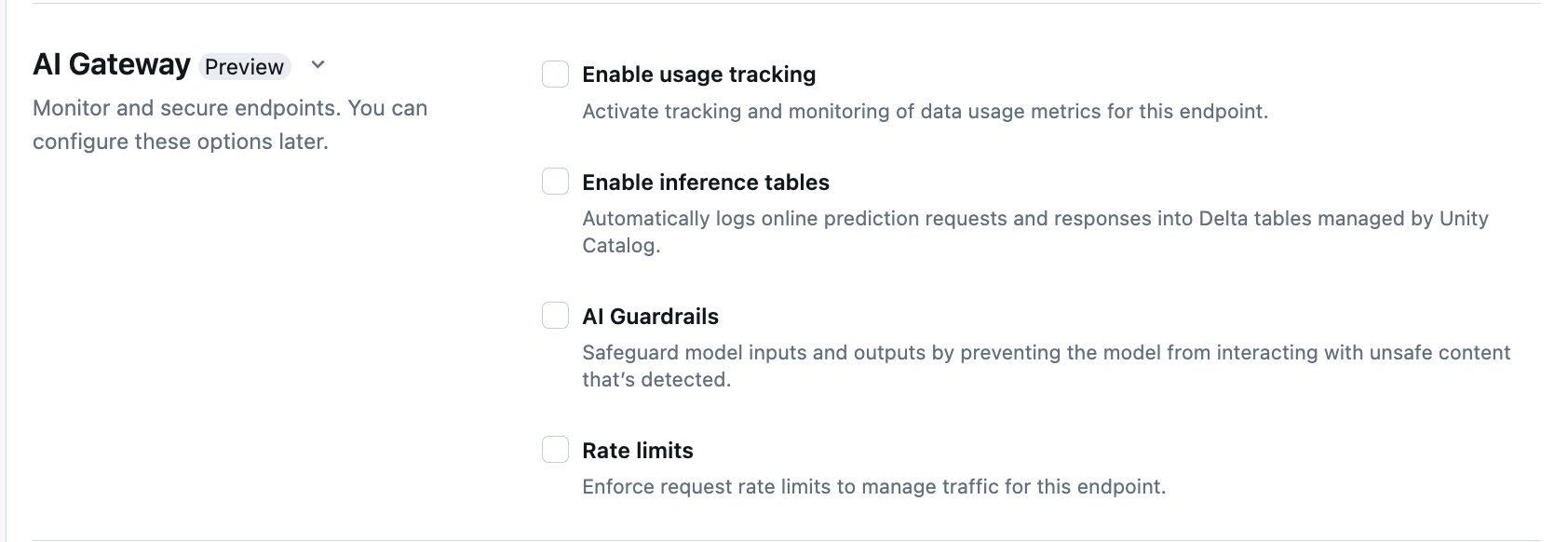
W sekcji Brama sztucznej inteligencji na stronie tworzenia punktu końcowego można indywidualnie skonfigurować następujące funkcje bramy AI:
| Funkcja | Jak włączyć | Szczegóły |
|---|---|---|
| Śledzenie użycia | Wybierz pozycję Włącz śledzenie użycia, aby włączyć śledzenie i monitorowanie metryk użycia danych. | — Musisz mieć włączony wykaz aparatu Unity. — Administratorzy kont muszą włączyć schemat tabeli systemu obsługującego przed użyciem tabel systemowych: system.serving.endpoint_usage który przechwytuje liczbę tokenów dla każdego żądania do punktu końcowego i system.serving.served_entities który przechowuje metadane dla każdego modelu zewnętrznego.— Zobacz Schematy tabeli śledzenia użycia — Tylko administratorzy kont mają uprawnienia do wyświetlania lub wykonywania zapytań dotyczących served_entities tabeli lub endpoint_usage tabeli, mimo że użytkownik zarządzający punktem końcowym musi włączyć śledzenie użycia. Zobacz Udzielanie dostępu do tabel systemowych— Liczba tokenów wejściowych i wyjściowych jest szacowana jako ( text_length+1)/4, jeśli liczba tokenów nie jest zwracana przez model. |
| Rejestrowanie ładunku | Wybierz pozycję Włącz tabele wnioskowania, aby automatycznie rejestrować żądania i odpowiedzi z punktu końcowego do tabel delty zarządzanych przez wykaz aparatu Unity. | — Musisz mieć włączony wykaz aparatu Unity i CREATE_TABLE dostęp w określonym schemacie wykazu.- Tabele wnioskowania włączone przez bramę sztucznej inteligencji mają inny schemat niż te utworzone dla punktów końcowych obsługujących modele obsługujące modele niestandardowe. Zobacz Schemat tabeli wnioskowania z obsługą bramy sztucznej inteligencji. — Dane rejestrowania ładunku wypełniają te tabele mniej niż godzinę po wykonaniu zapytania o punkt końcowy. - Ładunki większe niż 1 MB nie są rejestrowane. — Ładunek odpowiedzi agreguje odpowiedź wszystkich zwróconych fragmentów. — Przesyłanie strumieniowe jest obsługiwane. W scenariuszach przesyłania strumieniowego ładunek odpowiedzi agreguje odpowiedź zwróconych fragmentów. |
| Zabezpieczenia sztucznej inteligencji | Zobacz Konfigurowanie barier AI Guardrails w interfejsie użytkownika. | — Zabezpieczenia uniemożliwiają modelowi interakcję z niebezpieczną i szkodliwą zawartością wykrytą w danych wejściowych i wyjściowych modelu. — Zabezpieczenia wyjściowe nie są obsługiwane w przypadku osadzania modeli ani przesyłania strumieniowego. |
| Limity szybkości | Możesz wymusić limity szybkości żądań w celu zarządzania ruchem dla punktu końcowego dla poszczególnych użytkowników i poszczególnych punktów końcowych | - Limity szybkości są definiowane w zapytaniach na minutę (QPM). — Wartość domyślna to Brak limitu zarówno dla użytkownika, jak i dla punktu końcowego. |
| Routing ruchu | Aby skonfigurować routing ruchu w punkcie końcowym, zobacz Obsługa wielu modeli zewnętrznych do punktu końcowego. |
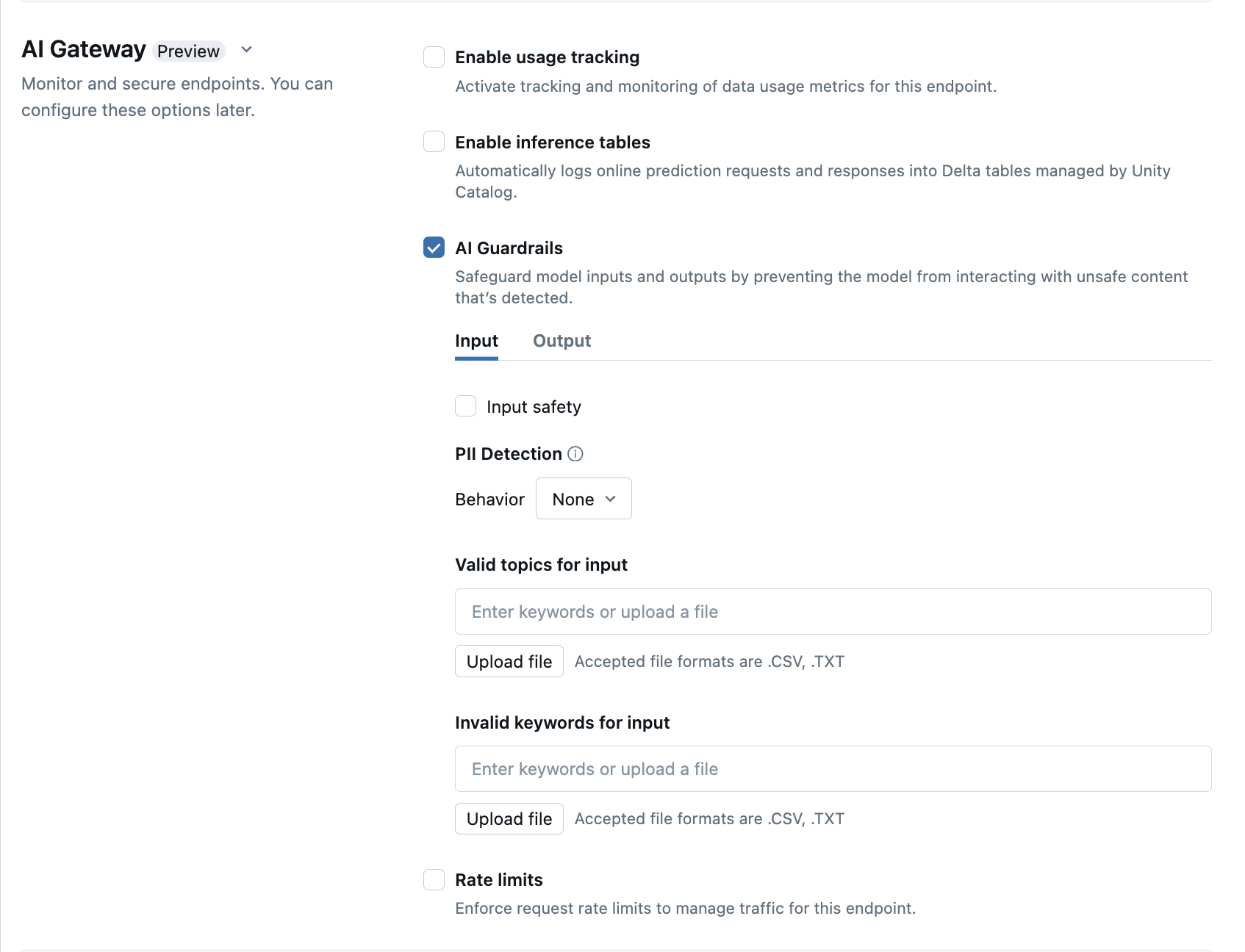
Konfigurowanie barier AI Guardrails w interfejsie użytkownika
W poniższej tabeli przedstawiono sposób konfigurowania obsługiwanych poręczy.
| Poręcze | Jak włączyć | Szczegóły |
|---|---|---|
| Bezpieczeństwo | Wybierz pozycję Bezpieczeństwo , aby umożliwić ochronę, aby uniemożliwić modelowi interakcję z niebezpieczną i szkodliwą zawartością. | |
| Wykrywanie danych osobowych | Wybierz pozycję Wykrywanie danych pii, aby wykryć dane osobowe, takie jak nazwy, adresy, numery kart kredytowych. | |
| Prawidłowe tematy | Tematy można wpisać bezpośrednio w tym polu. Jeśli masz wiele wpisów, pamiętaj, aby nacisnąć Enter po każdym temacie. Alternatywnie możesz przekazać plik .csv lub .txt . |
Można określić maksymalnie 50 prawidłowych tematów. Każdy temat nie może przekraczać 100 znaków |
| Nieprawidłowe słowa kluczowe | Tematy można wpisać bezpośrednio w tym polu. Jeśli masz wiele wpisów, pamiętaj, aby nacisnąć Enter po każdym temacie. Alternatywnie możesz przekazać plik .csv lub .txt . |
Można określić maksymalnie 50 nieprawidłowych słów kluczowych. Każde słowo kluczowe nie może przekraczać 100 znaków. |
Schematy tabeli śledzenia użycia
Tabela system.serving.served_entities systemu śledzenia użycia ma następujący schemat:
| Nazwa kolumny | opis | Type |
|---|---|---|
served_entity_id |
Unikatowy identyfikator obsługiwanej jednostki. | STRUNA |
account_id |
Identyfikator konta klienta na potrzeby udostępniania różnicowego. | STRUNA |
workspace_id |
Identyfikator obszaru roboczego klienta punktu końcowego obsługi. | STRUNA |
created_by |
Identyfikator twórcy. | STRUNA |
endpoint_name |
Nazwa obsługującego punktu końcowego. | STRUNA |
endpoint_id |
Unikatowy identyfikator punktu końcowego obsługi. | STRUNA |
served_entity_name |
Nazwa obsługiwanej jednostki. | STRUNA |
entity_type |
Typ obsługiwanej jednostki. Może to być FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODELlub CUSTOM_MODEL |
STRUNA |
entity_name |
Podstawowa nazwa jednostki. Różni się od served_entity_name nazwy podanej przez użytkownika. Na przykład entity_name to nazwa modelu wykazu aparatu Unity. |
STRUNA |
entity_version |
Wersja obsługiwanej jednostki. | STRUNA |
endpoint_config_version |
Wersja konfiguracji punktu końcowego. | INT |
task |
Typ zadania. Może to być llm/v1/chat, llm/v1/completionslub llm/v1/embeddings. |
STRUNA |
external_model_config |
Konfiguracje modeli zewnętrznych. Na przykład {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Konfiguracje modeli podstawowych. Na przykład{min_provisioned_throughput: null, max_provisioned_throughput: null, pt_model_type: mpt-7b} |
STRUCT |
custom_model_config |
Konfiguracje modeli niestandardowych. Na przykład{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Konfiguracje specyfikacji funkcji. Na przykład { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Sygnatura czasowa zmiany dla obsługiwanej jednostki. | TIMESTAMP |
endpoint_delete_time |
Sygnatura czasowa usuwania jednostki. Punkt końcowy jest kontenerem dla obsługiwanej jednostki. Po usunięciu punktu końcowego obsługiwana jednostka zostanie również usunięta. | TIMESTAMP |
Tabela system.serving.endpoint_usage systemu śledzenia użycia ma następujący schemat:
| Nazwa kolumny | opis | Type |
|---|---|---|
account_id |
Identyfikator konta klienta. | STRUNA |
workspace_id |
Identyfikator obszaru roboczego klienta obsługującego punkt końcowy. | STRUNA |
client_request_id |
Użytkownik podał identyfikator żądania, który można określić w treści żądania obsługującego model. | STRUNA |
databricks_request_id |
Wygenerowany identyfikator żądania usługi Azure Databricks dołączony do wszystkich żądań obsługi modelu. | STRUNA |
requester |
Identyfikator użytkownika lub jednostki usługi, którego uprawnienia są używane do żądania wywołania punktu końcowego obsługującego. | STRUNA |
status_code |
Kod stanu HTTP zwrócony z modelu. | LICZBA CAŁKOWITA |
request_time |
Sygnatura czasowa, w której żądanie zostanie odebrane. | TIMESTAMP |
input_token_count |
Liczba tokenów danych wejściowych. | DŁUGI |
output_token_count |
Liczba tokenów danych wyjściowych. | DŁUGI |
input_character_count |
Liczba znaków ciągu wejściowego lub monitu. | DŁUGI |
output_character_count |
Liczba znaków ciągu wyjściowego odpowiedzi. | DŁUGI |
usage_context |
Użytkownik podał mapę zawierającą identyfikatory użytkownika końcowego lub aplikacji klienta, która wykonuje wywołanie punktu końcowego. Zobacz Dalsze definiowanie użycia za pomocą usage_context. | MAPA |
request_streaming |
Czy żądanie jest w trybie strumienia. | BOOLOWSKI |
served_entity_id |
Unikatowy identyfikator używany do łączenia z tabelą wymiarów system.serving.served_entities w celu wyszukiwania informacji o punkcie końcowym i obsługiwanej jednostce. |
STRUNA |
Dalsze definiowanie użycia za pomocą polecenia usage_context
Podczas wykonywania zapytań względem modelu zewnętrznego z włączonym śledzeniem użycia można podać usage_context parametr o typie Map[String, String]. Mapowanie kontekstu użycia jest wyświetlane w tabeli śledzenia użycia w kolumnie usage_context . Administratorzy kont mogą agregować różne wiersze na podstawie kontekstu użycia, aby uzyskać szczegółowe informacje i połączyć te informacje z informacjami w tabeli rejestrowania ładunków. Możesz na przykład dodać end_user_to_charge element do usage_context śledzenia przypisania kosztów dla użytkowników końcowych.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Schemat tabeli wnioskowania z obsługą bramy sztucznej inteligencji
Tabele wnioskowania włączone przy użyciu bramy sztucznej inteligencji mają następujący schemat:
| Nazwa kolumny | opis | Type |
|---|---|---|
request_date |
Data UTC, w której odebrano żądanie obsługi modelu. | DATE |
databricks_request_id |
Wygenerowany identyfikator żądania usługi Azure Databricks dołączony do wszystkich żądań obsługi modelu. | STRUNA |
client_request_id |
Opcjonalny identyfikator żądania wygenerowany przez klienta, który można określić w treści żądania obsługującego model. | STRUNA |
request_time |
Sygnatura czasowa, w której żądanie zostanie odebrane. | TIMESTAMP |
status_code |
Kod stanu HTTP zwrócony z modelu. | INT |
sampling_fraction |
Ułamek próbkowania używany w przypadku, gdy żądanie zostało próbkowane w dół. Ta wartość wynosi od 0 do 1, gdzie 1 oznacza, że uwzględniono 100% żądań przychodzących. | PODWÓJNY |
execution_duration_ms |
Czas w milisekundach, dla których model wykonał wnioskowanie. Nie obejmuje to opóźnień sieci narzutów i reprezentuje tylko czas, jaki zajęło modelowi generowanie przewidywań. | BIGINT |
request |
Treść nieprzetworzonego żądania JSON, która została wysłana do punktu końcowego obsługującego model. | STRUNA |
response |
Treść nieprzetworzonej odpowiedzi JSON zwrócona przez punkt końcowy obsługujący model. | STRUNA |
served_entity_id |
Unikatowy identyfikator obsługiwanej jednostki. | STRUNA |
logging_error_codes |
TABLICA | |
requester |
Identyfikator użytkownika lub jednostki usługi, którego uprawnienia są używane do żądania wywołania punktu końcowego obsługującego. | STRUNA |
Aktualizowanie funkcji bramy sztucznej inteligencji w punktach końcowych
Funkcje bramy sztucznej inteligencji można zaktualizować w modelu obsługującym punkty końcowe, które wcześniej były włączone, i punkty końcowe, które nie zostały wcześniej włączone. Zastosowanie aktualizacji konfiguracji bramy sztucznej inteligencji trwa około 20–40 sekund, jednak ograniczanie szybkości aktualizacji może potrwać do 60 sekund.
Poniżej pokazano, jak zaktualizować funkcje bramy sztucznej inteligencji w punkcie końcowym obsługującym model przy użyciu interfejsu użytkownika obsługującego.
W sekcji Brama strony punktu końcowego można zobaczyć, które funkcje są włączone. Aby zaktualizować te funkcje, kliknij pozycję Edytuj bramę sztucznej inteligencji.

Przykład notesu
W poniższym notesie przedstawiono sposób programowego włączania i używania funkcji bramy mozaiki usługi Databricks Do zarządzania modelami od dostawców i zarządzania nimi.