RAG (pobieranie rozszerzonej generacji) w usłudze Azure Databricks
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Struktura agentów składa się z zestawu narzędzi usługi Databricks zaprojektowanych w celu ułatwienia deweloperom tworzenia, wdrażania i oceniania agentów sztucznej inteligencji wysokiej jakości w środowisku produkcyjnym, takich jak pobieranie aplikacji generacji rozszerzonej (RAG).
W tym artykule opisano, czym jest rag, oraz korzyści wynikające z tworzenia aplikacji RAG w usłudze Azure Databricks.
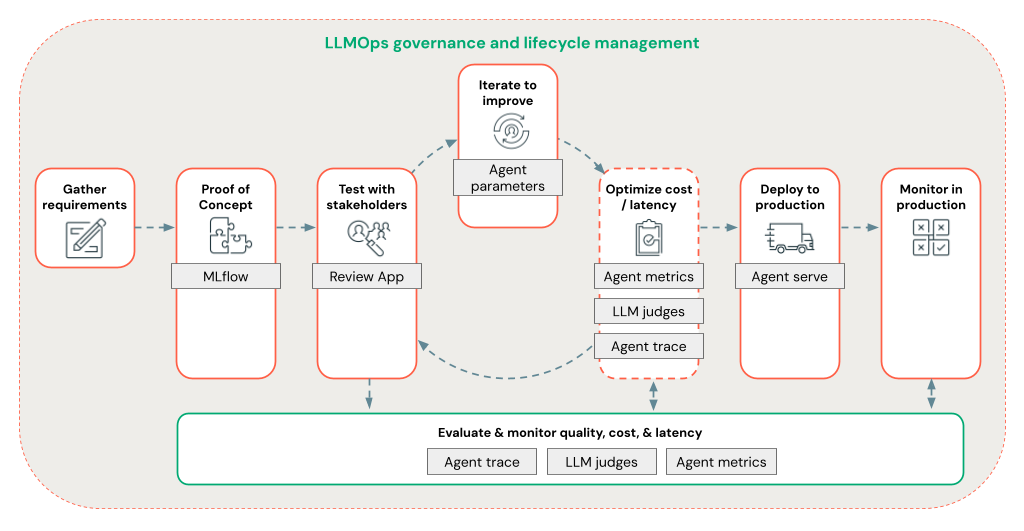
Struktura agentów umożliwia deweloperom szybkie iterowanie we wszystkich aspektach programowania RAG przy użyciu kompleksowego przepływu pracy LLMOps.
Wymagania
- Funkcje pomocnicze sztucznej inteligencji oparte na sztucznej inteligencji platformy Azure muszą być włączone dla obszaru roboczego.
- Wszystkie składniki aplikacji agenta muszą znajdować się w jednym obszarze roboczym. Na przykład w przypadku aplikacji RAG model obsługujący i wystąpienie wyszukiwania wektorowego muszą znajdować się w tym samym obszarze roboczym.
Co to jest RAG?
RAG to generacyjna technika projektowania sztucznej inteligencji, która rozszerza duże modele językowe (LLM) o wiedzę zewnętrzną. Ta technika usprawnia moduły LLM w następujący sposób:
- Zastrzeżona wiedza: RAG może zawierać zastrzeżone informacje, które nie są początkowo używane do trenowania usługi LLM, takich jak notatki, wiadomości e-mail i dokumenty, aby odpowiedzieć na pytania specyficzne dla domeny.
- Aktualne informacje: aplikacja RAG może dostarczyć program LLM z informacjami ze zaktualizowanych źródeł danych.
- Powołując się na źródła: RAG umożliwia LLMs przytaczanie określonych źródeł, umożliwiając użytkownikom weryfikowanie faktycznej dokładności odpowiedzi.
- Listy zabezpieczeń danych i kontroli dostępu (ACL): krok pobierania można zaprojektować w celu selektywnego pobierania informacji osobistych lub zastrzeżonych na podstawie poświadczeń użytkownika.
Złożone systemy sztucznej inteligencji
Aplikacja RAG jest przykładem złożonego systemu sztucznej inteligencji: rozszerza możliwości języka LLM, łącząc je z innymi narzędziami i procedurami.
W najprostszej formie aplikacja RAG wykonuje następujące czynności:
- Pobieranie: żądanie użytkownika służy do wykonywania zapytań względem zewnętrznego magazynu danych, takiego jak magazyn wektorów, wyszukiwanie słów kluczowych tekstu lub baza danych SQL. Celem jest uzyskanie danych pomocniczych dla odpowiedzi LLM.
- Rozszerzenie: pobrane dane są łączone z żądaniem użytkownika, często przy użyciu szablonu z dodatkowym formatowaniem i instrukcjami w celu utworzenia monitu.
- Generowanie: monit jest przekazywany do usługi LLM, która następnie generuje odpowiedź na zapytanie.
Dane NIEustrukturyzowane a ustrukturyzowane dane RAG
Architektura RAG może współdziałać z danymi pomocniczymi bez struktury lub ze strukturą. Dane używane z narzędziem RAG zależą od twojego przypadku użycia.
Dane bez struktury: dane bez określonej struktury lub organizacji. Dokumenty zawierające tekst i obrazy lub zawartość multimedialną, taką jak audio lub wideo.
- Pliki PDF
- Dokumenty Google/Office
- Strony typu wiki
- Obrazy
- Filmy wideo
Dane ustrukturyzowane: dane tabelaryczne rozmieszczone w wierszach i kolumnach z określonym schematem, takim jak tabele w bazie danych.
- Rekordy klientów w systemie analizy biznesowej lub magazynu danych
- Dane transakcji z bazy danych SQL
- Dane z interfejsów API aplikacji (np. SAP, Salesforce itp.)
W poniższych sekcjach opisano aplikację RAG dla danych bez struktury.
Potok danych RAG
Potok danych RAG wstępnie przetwarza i indeksuje dokumenty w celu szybkiego i dokładnego pobierania.
Na poniższym diagramie przedstawiono przykładowy potok danych dla zestawu danych bez struktury przy użyciu algorytmu wyszukiwania semantycznego. Zadania usługi Databricks organizuje każdy krok.
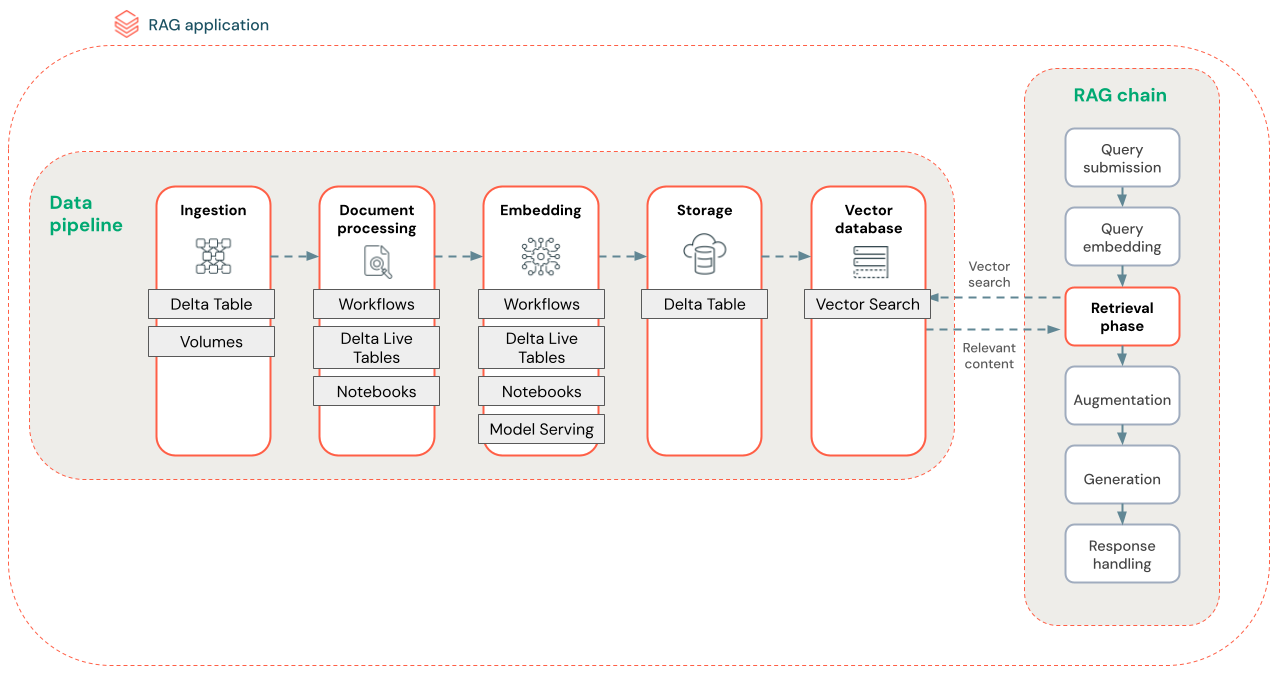
- Pozyskiwanie danych — pozyskiwanie danych z zastrzeżonego źródła. Przechowuj te dane w tabeli delty lub woluminie wykazu aparatu Unity.
- Przetwarzanie dokumentów: te zadania można wykonywać przy użyciu zadań usługi Databricks, notesów usługi Databricks i tabel różnicowych na żywo.
- Analizowanie nieprzetworzonych dokumentów: przekształcanie danych pierwotnych w format użyteczny. Na przykład wyodrębnianie tekstu, tabel i obrazów z kolekcji plików PDF lub używanie technik optycznego rozpoznawania znaków w celu wyodrębnienia tekstu z obrazów.
- Wyodrębnianie metadanych: wyodrębnianie metadanych dokumentu, takich jak tytuły dokumentów, numery stron i adresy URL, aby ułatwić dokładniejsze pobieranie zapytania krokowego.
- Dokumenty fragmentów: podziel dane na fragmenty, które mieszczą się w oknie kontekstowym LLM. Pobieranie tych skoncentrowanych fragmentów, a nie całych dokumentów, zapewnia bardziej docelową zawartość llM do generowania odpowiedzi.
- Osadzanie fragmentów — model osadzania używa fragmentów w celu utworzenia liczbowych reprezentacji informacji nazywanych osadzaniem wektorów. Wektory reprezentują semantyczne znaczenie tekstu, a nie tylko słowa kluczowe na poziomie powierzchni. W tym scenariuszu obliczysz osadzanie i użyjesz usługi Model Serving, aby obsłużyć model osadzania.
- Magazyn osadzania — przechowuj wektorowe osadzanie i tekst fragmentu w tabeli delty zsynchronizowanej z wyszukiwaniem wektorowym.
- Baza danych wektorów — w ramach wyszukiwania wektorowego osadzanie i metadane są indeksowane i przechowywane w bazie danych wektorów w celu łatwego wykonywania zapytań przez agenta RAG. Gdy użytkownik tworzy zapytanie, jego żądanie jest osadzone w wektorze. Następnie baza danych używa indeksu wektorowego do znajdowania i zwracania najbardziej podobnych fragmentów.
Każdy krok obejmuje decyzje inżynieryjne wpływające na jakość aplikacji RAG. Na przykład wybranie odpowiedniego rozmiaru fragmentu w kroku (3) gwarantuje, że funkcja LLM odbiera określone, ale kontekstowe informacje, wybierając odpowiedni model osadzania w kroku (4) określa dokładność fragmentów zwracanych podczas pobierania.
Wyszukiwanie wektorów usługi Databricks
Podobieństwo obliczeniowe jest często kosztowne pod względem obliczeniowym, ale indeksy wektorów, takie jak wyszukiwanie wektorów usługi Databricks, optymalizując je, efektywnie organizując osadzanie. Wyszukiwanie wektorowe szybko klasyfikuje najbardziej odpowiednie wyniki bez porównywania każdego osadzania z zapytaniem użytkownika indywidualnie.
Funkcja wyszukiwania wektorowego automatycznie synchronizuje nowe osadzanie dodane do tabeli delta i aktualizuje indeks wyszukiwania wektorowego.
Co to jest agent RAG?
Agent rozszerzonej generacji pobierania (RAG) to kluczowa część aplikacji RAG, która zwiększa możliwości dużych modeli językowych (LLM) przez zintegrowanie pobierania danych zewnętrznych. Agent RAG przetwarza zapytania użytkowników, pobiera odpowiednie dane z wektorowej bazy danych i przekazuje te dane do modułu LLM w celu wygenerowania odpowiedzi.
Narzędzia takie jak LangChain lub Pyfunc łączą te kroki, łącząc swoje dane wejściowe i wyjściowe.
Na poniższym diagramie przedstawiono agenta RAG dla czatbota oraz funkcje usługi Databricks używane do kompilowania poszczególnych agentów.
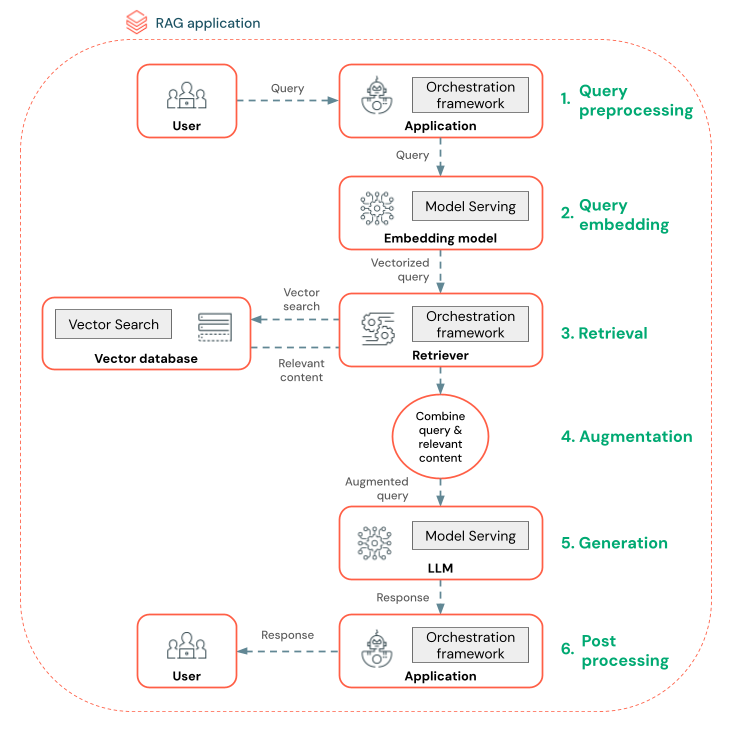
- Przetwarzanie wstępne zapytań — użytkownik przesyła zapytanie, które następnie jest wstępnie przetworzone, aby było odpowiednie do wykonywania zapytań względem bazy danych wektorów. Może to obejmować umieszczenie żądania w szablonie lub wyodrębnianie słów kluczowych.
- Wektoryzacja zapytań — użyj obsługi modelu, aby osadzić żądanie przy użyciu tego samego modelu osadzania używanego do osadzania fragmentów w potoku danych. Te osadzania umożliwiają porównanie podobieństwa semantycznego między żądaniem a wstępnie przetworzonymi fragmentami.
- Faza pobierania — retriever, aplikacja odpowiedzialna za pobieranie odpowiednich informacji, pobiera wektorowe zapytanie i wykonuje wyszukiwanie podobieństwa wektorowego przy użyciu wyszukiwania wektorowego. Najbardziej odpowiednie fragmenty danych są klasyfikowane i pobierane na podstawie ich podobieństwa do zapytania.
- Monitowanie rozszerzone — retriever łączy pobrane fragmenty danych z oryginalnym zapytaniem w celu zapewnienia dodatkowego kontekstu do usługi LLM. Monit jest starannie ustrukturyzowany, aby upewnić się, że usługa LLM rozumie kontekst zapytania. Często usługa LLM ma szablon do formatowania odpowiedzi. Ten proces dostosowywania monitu jest nazywany inżynierią monitu.
- Faza generowania llM — funkcja LLM generuje odpowiedź przy użyciu rozszerzonego zapytania wzbogaconego przez wyniki pobierania. LlM może być modelem niestandardowym lub modelem podstawowym.
- Przetwarzanie końcowe — odpowiedź LLM może zostać przetworzona w celu zastosowania dodatkowej logiki biznesowej, dodania cytatów lub w inny sposób uściślić wygenerowany tekst na podstawie wstępnie zdefiniowanych reguł lub ograniczeń
W tym procesie można zastosować różne zabezpieczenia w celu zapewnienia zgodności z zasadami przedsiębiorstwa. Może to obejmować filtrowanie odpowiednich żądań, sprawdzanie uprawnień użytkownika przed uzyskaniem dostępu do źródeł danych oraz używanie technik racja con tryb namiotu ration na wygenerowanych odpowiedziach.
Opracowywanie agentów RAG na poziomie produkcyjnym
Szybkie iterowanie tworzenia agentów przy użyciu następujących funkcji:
Tworzenie i rejestrowanie agentów przy użyciu dowolnej biblioteki i biblioteki MLflow. Parametryzowanie agentów w celu szybkiego eksperymentowania i iterowania na potrzeby opracowywania agentów.
Wdróż agentów w środowisku produkcyjnym z natywną obsługą przesyłania strumieniowego tokenu i rejestrowania żądań/odpowiedzi oraz wbudowaną aplikację do przeglądu, aby uzyskać opinie użytkowników dotyczące agenta.
Śledzenie agenta umożliwia rejestrowanie, analizowanie i porównywanie śladów w kodzie agenta w celu debugowania i zrozumienia sposobu reagowania agenta na żądania.
Ocena i monitorowanie
Ocena i monitorowanie pomagają określić, czy aplikacja RAG spełnia wymagania dotyczące jakości, kosztów i opóźnień. Ocena odbywa się podczas programowania, podczas gdy monitorowanie odbywa się po wdrożeniu aplikacji w środowisku produkcyjnym.
Funkcja RAG nad danymi bez struktury ma wiele składników, które mają wpływ na jakość. Na przykład zmiany formatowania danych mogą mieć wpływ na pobrane fragmenty i możliwość generowania odpowiednich odpowiedzi przez moduł LLM. Dlatego ważne jest, aby oceniać poszczególne składniki oprócz ogólnej aplikacji.
Aby uzyskać więcej informacji, zobacz Co to jest ocena agenta mozaiki sztucznej inteligencji?.
Dostępność w regionach
Aby uzyskać dostępność regionalną platformy Agent Framework, zobacz Funkcje z ograniczoną dostępnością regionalną