Stosy MLOps: proces tworzenia modelu jako kod
W tym artykule opisano, jak stosy MLOps umożliwiają zaimplementowanie procesu programowania i wdrażania jako kodu w repozytorium kontrolowanym przez źródło. Opisano również zalety opracowywania modeli na platformie analizy danych usługi Databricks, jednej platformy, która łączy każdy krok procesu tworzenia i wdrażania modelu.
Co to są stosy MLOps?
W przypadku stosów MLOps cały proces tworzenia modelu jest implementowany, zapisywany i śledzony jako kod w repozytorium kontrolowanym przez źródło. Automatyzacja procesu w ten sposób ułatwia bardziej powtarzalne, przewidywalne i systematyczne wdrożenia oraz umożliwia integrację z procesem ciągłej integracji/ciągłego wdrażania. Reprezentowanie procesu tworzenia modelu jako kodu umożliwia wdrożenie kodu zamiast wdrażania modelu. Wdrożenie kodu automatyzuje możliwość kompilowania modelu, co znacznie ułatwia ponowne trenowanie modelu w razie potrzeby.
Podczas tworzenia projektu przy użyciu stosów MLOps definiuje się składniki procesu programowania i wdrażania uczenia maszynowego, takie jak notesy do użycia na potrzeby inżynierii funkcji, trenowania, testowania i wdrażania, potoki do trenowania i testowania, obszary robocze do użycia dla każdego etapu oraz przepływy pracy ciągłej integracji/ciągłego wdrażania przy użyciu funkcji GitHub Actions lub Azure DevOps na potrzeby zautomatyzowanego testowania i wdrażania kodu.
Środowisko utworzone przez stosy MLOps implementuje przepływ pracy metodyki MLOps zalecany przez usługę Databricks. Możesz dostosować kod, aby tworzyć stosy w celu dopasowania ich do procesów lub wymagań organizacji.
Jak działają stosy MLOps?
Interfejs wiersza polecenia usługi Databricks służy do tworzenia stosu MLOps. Aby uzyskać instrukcje krok po kroku, zobacz Zestawy zasobów usługi Databricks dla stosów MLOps.
Po zainicjowaniu projektu stosów MLOps oprogramowanie wykonuje kroki przez wprowadzenie szczegółów konfiguracji, a następnie tworzy katalog zawierający pliki, które tworzą projekt. Ten katalog lub stos implementuje produkcyjny przepływ pracy MLOps zalecany przez usługę Databricks. Składniki pokazane na diagramie są tworzone dla Ciebie i potrzebne są tylko edycje plików w celu dodania kodu niestandardowego.
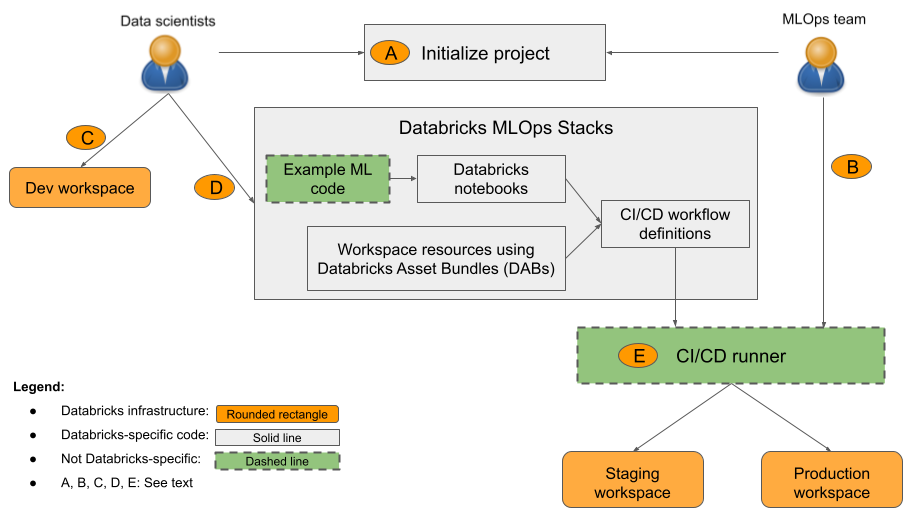
Na diagramie:
- 1: Analityk danych lub inżynier uczenia maszynowego inicjuje projekt przy użyciu metody
databricks bundle init mlops-stacks. Podczas inicjowania projektu można skonfigurować składniki kodu uczenia maszynowego (zwykle używane przez analityków danych), składniki ciągłej integracji/ciągłego wdrażania (zwykle używane przez inżynierów uczenia maszynowego) lub oba te składniki. - B: Inżynierowie uczenia maszynowego konfigurują wpisy tajne jednostki usługi Databricks dla ciągłej integracji/ciągłego wdrażania.
- C: Analitycy danych opracowują modele w usłudze Databricks lub w systemie lokalnym.
- D: Analitycy danych tworzą żądania ściągnięcia w celu zaktualizowania kodu uczenia maszynowego.
- E: Moduł uruchamiający ciągłą integrację/ciągłe wdrażanie uruchamia notesy, tworzy zadania i wykonuje inne zadania w obszarach roboczych przejściowych i produkcyjnych.
Organizacja może używać domyślnego stosu lub dostosowywać go zgodnie z potrzebami, aby dodawać, usuwać lub poprawiać składniki zgodnie z praktykami organizacji. Aby uzyskać szczegółowe informacje, zobacz readme repozytorium GitHub.
Stosy MLOps zaprojektowano z modułową strukturą, aby umożliwić różnym zespołom uczenia maszynowego niezależnie pracę nad projektem przy jednoczesnym przestrzeganiu najlepszych rozwiązań inżynierii oprogramowania i utrzymywaniu ciągłej integracji/ciągłego wdrażania klasy produkcyjnej. Inżynierowie produkcyjni konfigurują infrastrukturę uczenia maszynowego, która umożliwia analitykom danych opracowywanie, testowanie i wdrażanie potoków i modeli uczenia maszynowego w środowisku produkcyjnym.
Jak pokazano na diagramie, domyślny stos MLOps obejmuje następujące trzy składniki:
- Kod uczenia maszynowego. Stosy MLOps tworzą zestaw szablonów dla projektu uczenia maszynowego, w tym notesy do trenowania, wnioskowania wsadowego itd. Standardowy szablon umożliwia analitykom danych szybkie rozpoczęcie pracy, łączenie struktury projektu między zespołami i wymusza modułowe przygotowanie kodu do testowania.
- Zasoby uczenia maszynowego jako kod. Stosy MLOps definiują zasoby, takie jak obszary robocze i potoki dla zadań, takich jak trenowanie i wnioskowanie wsadowe. Zasoby są definiowane w pakietach zasobów usługi Databricks w celu ułatwienia testowania, optymalizacji i kontroli wersji środowiska uczenia maszynowego. Na przykład można wypróbować większy typ wystąpienia na potrzeby ponownego trenowania modelu zautomatyzowanego, a zmiana jest automatycznie śledzona w celu uzyskania przyszłego odwołania.
- Ciągła integracja/ciągłe wdrażanie. Za pomocą funkcji GitHub Actions lub Azure DevOps można testować i wdrażać kod i zasoby uczenia maszynowego, zapewniając, że wszystkie zmiany produkcyjne są wykonywane za pośrednictwem automatyzacji i że tylko przetestowany kod jest wdrażany w środowisku prod.
Przepływ projektu MLOps
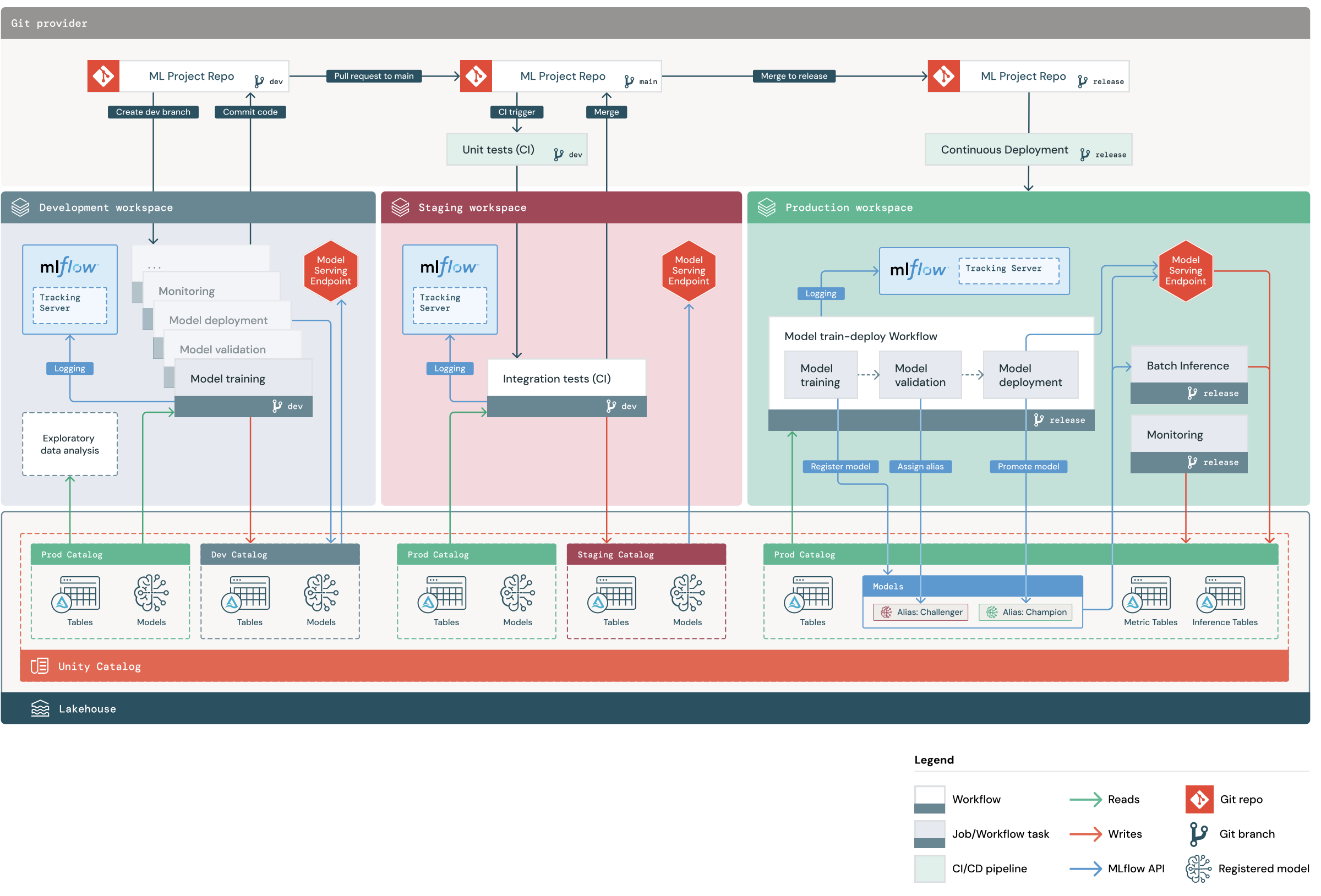
Domyślny projekt stosów MLOps obejmuje potok uczenia maszynowego z przepływami pracy ciągłej integracji/ciągłego wdrażania w celu testowania i wdrażania zautomatyzowanych zadań trenowania modelu i wnioskowania wsadowego w obszarach roboczych programowania, przemieszczania i produkcji usługi Databricks. Stosy MLOps można konfigurować, dzięki czemu można zmodyfikować strukturę projektu tak, aby spełniała procesy organizacji.
Na diagramie przedstawiono proces implementowany przez domyślny stos MLOps. W obszarze roboczym programowania analitycy danych iterują kod uczenia maszynowego i żądania ściągnięcia plików (PRs). Żądania ściągnięcia wyzwalają testy jednostkowe i testy integracji w izolowanym przejściowym obszarze roboczym usługi Databricks. Po scaleniu żądania ściągnięcia z głównymi zadaniami trenowania modelu i wnioskowania wsadowego, które są uruchamiane w środowisku przejściowym natychmiast aktualizują, aby uruchomić najnowszy kod. Po scaleniu żądania ściągnięcia z gałęzią główną można wyciąć nową gałąź wydania w ramach zaplanowanego procesu wydania i wdrożyć zmiany kodu w środowisku produkcyjnym.
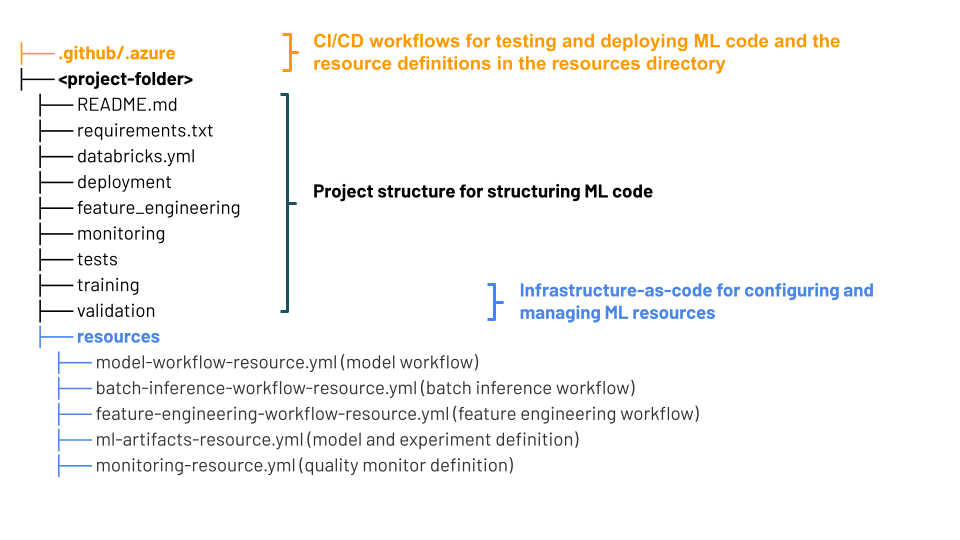
Struktura projektu stosów MLOps
Stos MLOps używa pakietów zasobów usługi Databricks — kolekcji plików źródłowych, która służy jako kompleksowa definicja projektu. Te pliki źródłowe zawierają informacje o sposobie ich testowania i wdrażania. Zbieranie plików jako pakietu ułatwia zmianę wersji i używanie najlepszych rozwiązań inżynierii oprogramowania, takich jak kontrola źródła, przegląd kodu, testowanie i ciągła integracja/ciągłe wdrażanie.
Na diagramie przedstawiono pliki utworzone dla domyślnego stosu MLOps. Aby uzyskać szczegółowe informacje o plikach zawartych w stosie, zapoznaj się z dokumentacją w repozytorium GitHub lub pakietami zasobów usługi Databricks dla stosów MLOps.
Składniki stosów MLOps
"Stos" odnosi się do zestawu narzędzi używanych w procesie programowania. Domyślny stos MLOps korzysta z ujednoliconej platformy usługi Databricks i korzysta z następujących narzędzi:
| Składnik | Narzędzie w usłudze Databricks |
|---|---|
| Kod programowania modelu uczenia maszynowego | Notesy usługi Databricks, MLflow |
| Opracowywanie funkcji i zarządzanie nimi | Inżynieria cech |
| Repozytorium modeli uczenia maszynowego | Modele w wykazie aparatu Unity |
| Obsługa modelu uczenia maszynowego | Obsługa modelu mozaiki sztucznej inteligencji |
| Infrastruktura jako kod | Pakiety zasobów usługi Databricks |
| Orchestrator | Zadania usługi Databricks |
| CI/CD | GitHub Actions, Azure DevOps |
| Monitorowanie wydajności danych i modelu | Monitorowanie usługi Lakehouse |
Następne kroki
Aby rozpocząć, zobacz Databricks Asset Bundles for MLOps Stacks (Pakiety zasobów usługi Databricks dla stosów MLOps usługi Databricks) w witrynie GitHub.