Uruchomienia potoków
Azure DevOps Services | Azure DevOps Server 2022 — Azure DevOps Server 2019
W tym artykule wyjaśniono sekwencję działań w przebiegach potoków usługi Azure Pipelines. Uruchomienie reprezentuje jedno wykonanie potoku. Potoki ciągłej integracji (CI) i ciągłego dostarczania (CD) składają się z przebiegów. Podczas uruchamiania usługa Azure Pipelines przetwarza potok, a agenci przetwarzają co najmniej jedno zadanie, kroki i zadania.
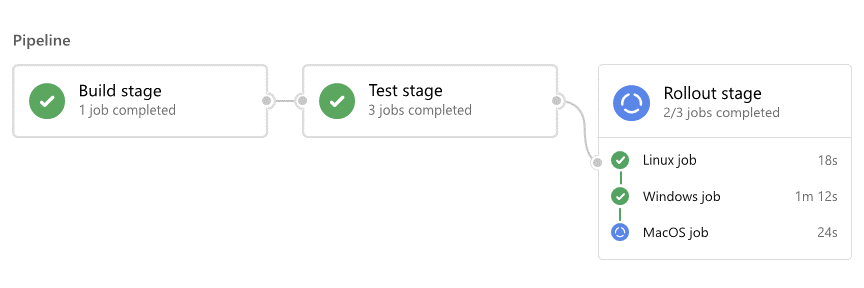
Dla każdego przebiegu usługa Azure Pipelines:
- Przetwarza potok.
- Żąda co najmniej jednego agenta do uruchamiania zadań.
- Przekazuje zadania agentom i zbiera wyniki.
Dla każdego zadania agent:
- Przygotowuje się do zadania.
- Uruchamia każdy krok w zadaniu.
- Raporty wyniki.
Zadania mogą zakończyć się powodzeniem, niepowodzeniem, anulować lub nie zostać ukończone. Zrozumienie tych wyników może pomóc w rozwiązywaniu problemów.
W poniższych sekcjach szczegółowo opisano proces uruchamiania potoku.
Przetwarzanie potoku
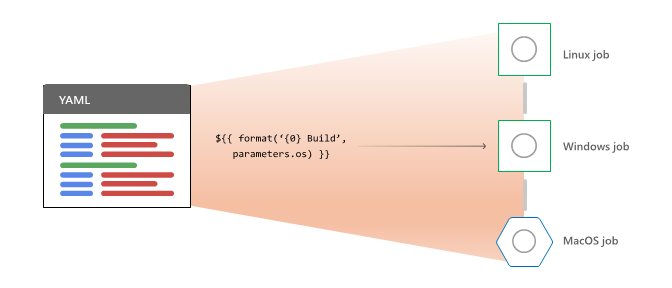
Aby przetworzyć potok dla przebiegu, najpierw usługa Azure Pipelines:
- Rozwija szablony i ocenia wyrażenia szablonu.
- Ocenia zależności na poziomie etapu, aby wybrać pierwszy etap do uruchomienia.
Dla każdego etapu wybranego do uruchomienia usługa Azure Pipelines:
- Zbiera i weryfikuje wszystkie zasoby zadań do uruchomienia autoryzacji .
- Ocenia zależności na poziomie zadania, aby wybrać pierwsze zadanie do uruchomienia.
Usługa Azure Pipelines wykonuje następujące działania dla każdego wybranego zadania do uruchomienia:
- Rozszerza kod YAML
strategy: matrixlubstrategy: parallelwiele konfiguracji do wielu zadań środowiska uruchomieniowego. - Ocenia warunki, aby zdecydować, czy zadanie kwalifikuje się do uruchomienia.
- Żąda agenta dla każdego kwalifikującego się zadania.
Po zakończeniu zadań środowiska uruchomieniowego usługa Azure Pipelines sprawdza, czy istnieją nowe zadania kwalifikujące się do uruchomienia. Podobnie w miarę ukończenia etapów usługa Azure Pipelines sprawdza, czy istnieją jeszcze etapy.
Zmienne
Zrozumienie kolejności przetwarzania wyjaśnia, dlaczego nie można używać pewnych zmiennych w parametrach szablonu. Pierwszy krok rozszerzenia szablonu działa tylko w tekście pliku YAML. Zmienne środowiska uruchomieniowego nie istnieją jeszcze w tym kroku. Po tym kroku parametry szablonu są już rozpoznawane.
Nie można również używać zmiennych do rozpoznawania nazw połączeń usług lub środowisk, ponieważ potok autoryzuje zasoby przed rozpoczęciem działania etapu. Zmienne na poziomie etapu i zadania nie są jeszcze dostępne. Grupy zmiennych są samymi zasobami podlegającymi autoryzacji, więc ich dane nie są dostępne podczas sprawdzania autoryzacji zasobów.
Można użyć zmiennych na poziomie potoku, które są jawnie uwzględnione w definicji zasobu potoku. Aby uzyskać więcej informacji, zobacz Pipeline resource metadata as predefined variables (Metadane zasobów potoku jako wstępnie zdefiniowane zmienne).
Agenci
Gdy usługa Azure Pipelines musi uruchomić zadanie, żąda agenta z puli. Proces działa inaczej w przypadku pul agentów hostowanych przez firmę Microsoft i własnych .
Uwaga
Zadania serwera nie używają puli, ponieważ są one uruchamiane na samym serwerze usługi Azure Pipelines.
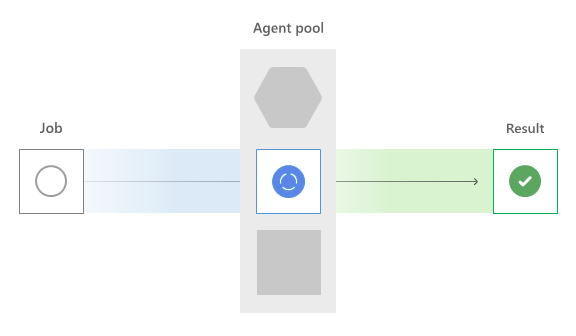
Zadania równoległe
Najpierw usługa Azure Pipelines sprawdza zadania równoległe organizacji. Usługa sumuje wszystkie uruchomione zadania na wszystkich agentach i porównuje je z liczbą przydzielonych lub zakupionych zadań równoległych.
Jeśli nie ma dostępnych gniazd równoległych, zadanie musi czekać na wolne miejsce. Po udostępnieniu miejsca równoległego zadanie kieruje do odpowiedniego typu agenta.
Agenci hostowani przez firmę Microsoft
Koncepcyjnie pula hostowana przez firmę Microsoft jest jedną globalną pulą maszyn, chociaż jest to fizycznie wiele różnych pul podzielonych według lokalizacji geograficznej i typu systemu operacyjnego. Na podstawie żądanej nazwy puli YAML vmImage lub klasycznej puli edytora usługa Azure Pipelines wybiera agenta.
Wszyscy agenci w puli firmy Microsoft to świeże, nowe maszyny wirtualne, które nigdy nie uruchamiały żadnych potoków. Po zakończeniu zadania maszyna wirtualna agenta zostanie odrzucona.
Właśni agenci
Po udostępnieniu miejsca równoległego usługa Azure Pipelines sprawdza pulę hostowaną samodzielnie dla zgodnego agenta. Agenci self-hosted oferują możliwości, które wskazują, że określone oprogramowanie jest zainstalowane lub skonfigurowane ustawienia. Potok ma wymagania, które są możliwościami wymaganymi do uruchomienia zadania.
Jeśli usługa Azure Pipelines nie może znaleźć bezpłatnego agenta, którego możliwości są zgodne z wymaganiami potoku, zadanie będzie nadal czekać. Jeśli w puli nie ma agentów, których możliwości odpowiadają wymaganiom, zadanie kończy się niepowodzeniem.
Agenci self-hosted są zwykle ponownie używane z uruchamiania do uruchomienia. W przypadku własnych agentów zadanie potoku może mieć skutki uboczne, takie jak rozgrzewanie pamięci podręcznych lub posiadanie większości zatwierdzeń dostępnych już w lokalnym repozytorium.
Przygotowywanie zadania
Gdy agent zaakceptuje zadanie, wykonuje następujące zadania przygotowania:
- Pobiera wszystkie zadania potrzebne do uruchomienia zadania i buforuje je do użycia w przyszłości.
- Tworzy miejsce robocze na dysku do przechowywania kodu źródłowego, artefaktów i danych wyjściowych używanych w przebiegu.
Wykonywanie kroków
Agent uruchamia kroki sekwencyjnie w kolejności. Przed rozpoczęciem kroku wszystkie poprzednie kroki muszą zostać zakończone lub pominięte.
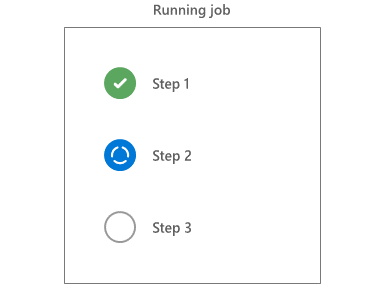
Kroki są implementowane przez zadania, które mogą być Node.js, programu PowerShell lub innych skryptów. System zadań kieruje dane wejściowe i wyjściowe do skryptów zapasowych. Zadania zapewniają również typowe usługi, takie jak zmiana ścieżki systemowej i tworzenie nowych zmiennych potoku.
Każdy krok jest uruchamiany we własnym procesie, izolując środowisko od poprzednich kroków. Ze względu na ten model procesu na krok zmienne środowiskowe nie są zachowywane między krokami. Jednak zadania i skrypty mogą używać mechanizmu nazywanego poleceniami rejestrowania w celu komunikacji z agentem. Gdy zadanie lub skrypt zapisuje polecenie rejestrowania w standardowych danych wyjściowych, agent wykonuje dowolną akcję żądaną przez polecenie.
Aby utworzyć nowe zmienne potoku, możesz użyć polecenia rejestrowania. Zmienne potoku są automatycznie konwertowane na zmienne środowiskowe w następnym kroku. Skrypt może ustawić nową zmienną myVar z wartością myValue w następujący sposób:
echo '##vso[task.setVariable variable=myVar]myValue'
Write-Host "##vso[task.setVariable variable=myVar]myValue"
Raportowanie i zbieranie wyników
Każdy krok może zgłaszać ostrzeżenia, błędy i błędy. Krok zgłasza błędy i ostrzeżenia na stronie podsumowania potoku, oznaczając zadania jako zakończone powodzeniem lub zgłasza błędy, oznaczając zadanie jako zakończone niepowodzeniem. Krok kończy się niepowodzeniem, jeśli jawnie zgłasza błąd przy użyciu ##vso polecenia lub kończy skrypt kodem zakończenia bezzerowym.
Po uruchomieniu kroków agent stale wysyła wiersze wyjściowe do usługi Azure Pipelines, aby zobaczyć kanał informacyjny na żywo konsoli. Na końcu każdego kroku wszystkie dane wyjściowe z kroku są przekazywane jako plik dziennika. Dziennik można pobrać po zakończeniu potoku.
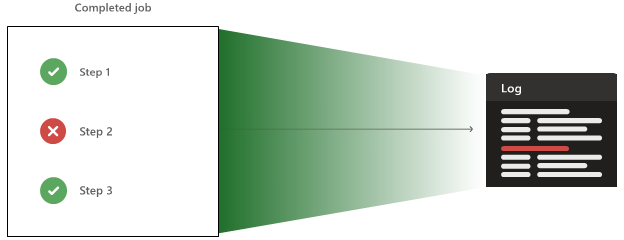
Agent może również przekazać artefakty i wyniki testów, które są również dostępne po zakończeniu potoku.
Stan i warunki
Agent śledzi powodzenie lub niepowodzenie każdego kroku. W miarę powodzenia kroków z problemami lub niepowodzeniem stan zadania jest aktualizowany. Zadanie zawsze odzwierciedla najgorszy wynik każdego z jego kroków. Jeśli krok zakończy się niepowodzeniem, zadanie również zakończy się niepowodzeniem.
Przed uruchomieniem kroku agent sprawdza warunek tego kroku, aby określić, czy krok powinien zostać uruchomiony. Domyślnie krok jest uruchamiany tylko wtedy, gdy stan zadania zakończył się pomyślnie lub zakończył się pomyślnie, ale można ustawić inne warunki.
Wiele zadań ma kroki oczyszczania, które muszą być uruchamiane niezależnie od tego, co się stanie, aby można było określić warunek always(). Oczyszczanie lub inne kroki można również ustawić tak, aby uruchamiać tylko w przypadku anulowania.
Pomyślny krok oczyszczania nie może zapisać zadania z powodu niepowodzenia. Zadania nigdy nie mogą wrócić do sukcesu po wprowadzeniu błędu.
Limity czasu i rozłączenia
Każde zadanie ma limit czasu. Jeśli zadanie nie zostanie ukończone w określonym czasie, serwer anuluje zadanie. Serwer próbuje zasygnalizować zatrzymanie agenta i oznaczy zadanie jako anulowane. Po stronie agenta anulowanie oznacza anulowanie wszystkich pozostałych kroków i przekazanie pozostałych wyników.
Zadania mają okres prolongaty nazywany limitem czasu anulowania, w którym można ukończyć pracę anulowania. Możesz również oznaczyć kroki, aby uruchomić nawet po anulowaniu. Po przekroczeniu limitu czasu zadania i przekroczeniu limitu czasu anulowania, jeśli agent nie zgłosi, że praca zostanie zatrzymana, serwer oznaczy zadanie jako niepowodzenie.
Maszyny agentów mogą przestać odpowiadać na serwer, jeśli maszyna hosta agenta traci zasilanie lub jest wyłączona, lub jeśli wystąpi awaria sieci. Aby ułatwić wykrywanie tych warunków, agent wysyła raz na minutę komunikat pulsu, aby poinformować serwer, że nadal działa.
Jeśli serwer nie otrzyma pulsu przez pięć kolejnych minut, zakłada, że agent nie wraca. Zadanie jest oznaczone jako błąd, informując użytkownika, że powinien ponowić próbę wykonania potoku.
Zarządzanie przebiega za pośrednictwem interfejsu wiersza polecenia usługi Azure DevOps
Przebiegi potoków można zarządzać za pomocą polecenia az pipelines run w interfejsie wiersza polecenia usługi Azure DevOps. Aby rozpocząć, zobacz Wprowadzenie do interfejsu wiersza polecenia usługi Azure DevOps. Aby uzyskać pełną dokumentację poleceń, zobacz Dokumentacja poleceń interfejsu wiersza polecenia usługi Azure DevOps.
W poniższych przykładach pokazano, jak za pomocą interfejsu wiersza polecenia usługi Azure DevOps wyświetlić listę przebiegów potoków w projekcie, wyświetlić szczegółowe informacje o określonym przebiegu i zarządzać tagami dla przebiegów potoków.
Wymagania wstępne
- Interfejs wiersza polecenia platformy Azure z zainstalowanym rozszerzeniem interfejsu wiersza polecenia usługi Azure DevOps zgodnie z opisem w artykule Rozpoczynanie pracy z interfejsem wiersza polecenia usługi Azure DevOps. Zaloguj się do platformy Azure przy użyciu polecenia
az login. - Domyślna organizacja ustawiona przy użyciu polecenia
az devops configure --defaults organization=<YourOrganizationURL>.
Wyświetlanie listy uruchomień potoków
Wyświetl listę przebiegów potoku w projekcie za pomocą polecenia az pipelines runs list .
Poniższe polecenie wyświetla listę pierwszych trzech przebiegów potoku, które mają stan ukończony i wynik powodzenia, i zwraca wynik w formacie tabeli.
az pipelines runs list --status completed --result succeeded --top 3 --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- ------
125 20200124.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 18:56:10.067588 manual
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
122 20200123.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:48:05.574742 manual
Pokaż szczegóły uruchomienia potoku
Pokaż szczegóły uruchomienia potoku w projekcie za pomocą polecenia az pipelines runs show .
Poniższe polecenie pokazuje szczegóły uruchomienia potoku o identyfikatorze 123, zwraca wyniki w formacie tabeli i otwiera przeglądarkę internetową na stronie wyników kompilacji usługi Azure Pipelines.
az pipelines runs show --id 122 --open --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- --------
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
Dodawanie tagu do uruchomienia potoku
Dodaj tag do uruchomienia potoku w projekcie za pomocą polecenia az pipelines runs tag add .
Następujące polecenie dodaje tag YAML do uruchomienia potoku o identyfikatorze 123 i zwraca wynik w formacie JSON.
az pipelines runs tag add --run-id 123 --tags YAML --output json
[
"YAML"
]
Wyświetlanie listy tagów uruchamiania potoku
Wyświetl listę tagów dla uruchomienia potoku w projekcie za pomocą polecenia az pipelines runs tag list . Poniższe polecenie wyświetla listę tagów dla przebiegu potoku o identyfikatorze 123 i zwraca wynik w formacie tabeli.
az pipelines runs tag list --run-id 123 --output table
Tags
------
YAML
Usuwanie tagu z przebiegu potoku
Usuń tag z uruchomienia potoku w projekcie za pomocą polecenia az pipelines run tag delete . Następujące polecenie usuwa tag YAML z przebiegu potoku o identyfikatorze 123.
az pipelines runs tag delete --run-id 123 --tag YAML