Omówienie przesyłania strumieniowego ze strukturą platformy Apache Spark
Przesyłanie strumieniowe ze strukturą platformy Apache Spark umożliwia implementowanie skalowalnych, odpornych na błędy aplikacji do przetwarzania strumieni danych. Przesyłanie strumieniowe ze strukturą jest oparte na akompilowaniu aparatu Spark SQL i ulepsza konstrukcje z ramek danych i zestawów danych Spark SQL, dzięki czemu można zapisywać zapytania przesyłane strumieniowo w taki sam sposób, jak zapytania wsadowe.
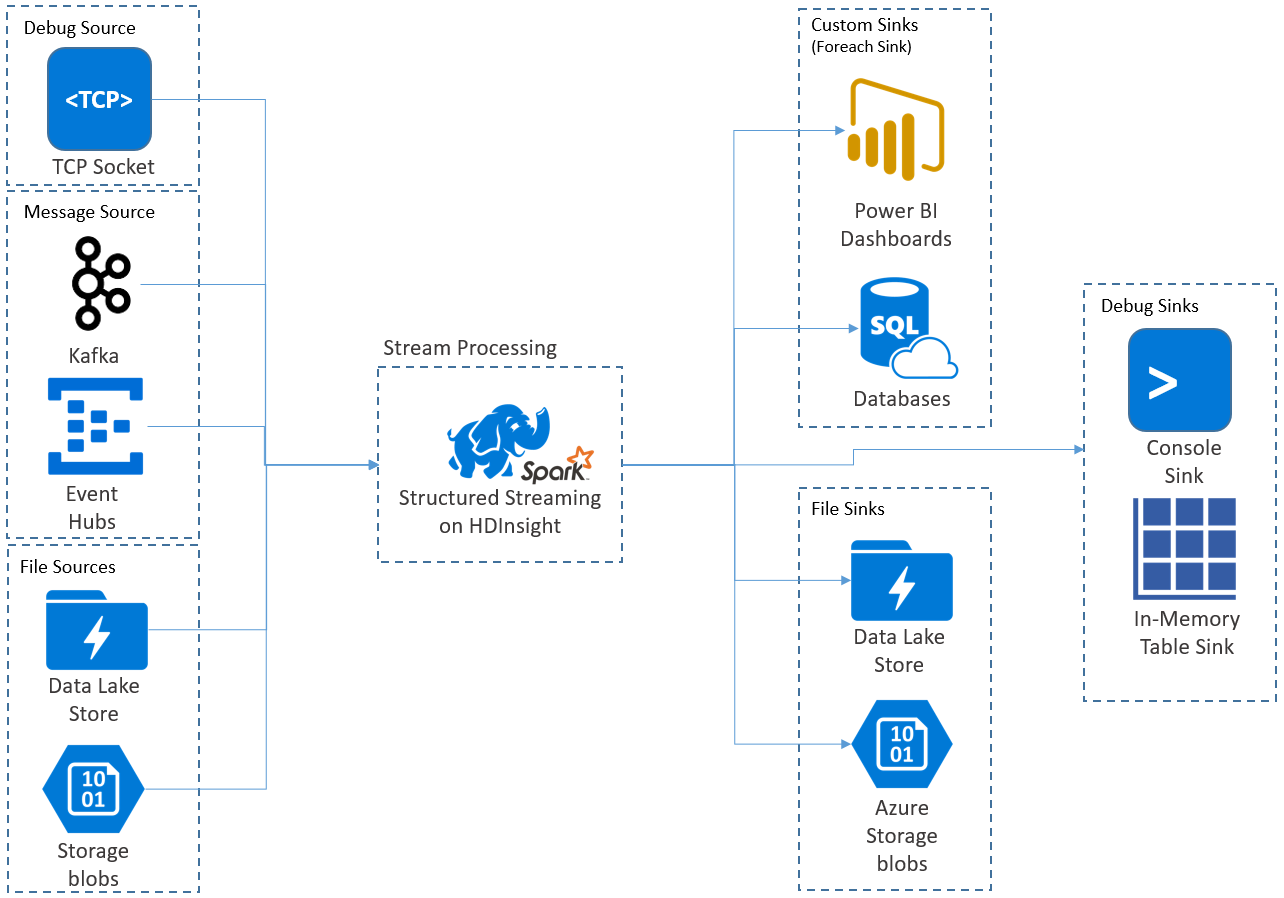
Aplikacje do przesyłania strumieniowego ze strukturą działają w klastrach HDInsight Spark i łączą się z danymi przesyłanymi strumieniowo z platformy Apache Kafka, gniazdem TCP (na potrzeby debugowania), usługą Azure Storage lub usługą Azure Data Lake Storage. Dwie ostatnie opcje, które opierają się na usługach magazynu zewnętrznego, umożliwiają obserwowanie nowych plików dodanych do magazynu i przetwarzanie ich zawartości tak, jakby były przesyłane strumieniowo.
Przesyłanie strumieniowe ze strukturą tworzy długotrwałe zapytanie, podczas którego stosujesz operacje do danych wejściowych, takich jak wybór, projekcja, agregacja, okno i łączenie przesyłania strumieniowego ramki danych z ramkami danych referencyjnych. Następnie wyprowadź wyniki do magazynu plików (obiektów blob usługi Azure Storage lub usługi Data Lake Storage) lub do dowolnego magazynu danych przy użyciu kodu niestandardowego (takiego jak usługa SQL Database lub Power BI). Przesyłanie strumieniowe ze strukturą udostępnia również dane wyjściowe do konsoli do debugowania lokalnie oraz do tabeli w pamięci, dzięki czemu można wyświetlić dane wygenerowane do debugowania w usłudze HDInsight.
Uwaga
Przesyłanie strumieniowe ze strukturą platformy Spark zastępuje przesyłanie strumieniowe platformy Spark (D Strumienie). W przyszłości przesyłanie strumieniowe ze strukturą będzie otrzymywać ulepszenia i konserwację, podczas gdy D Strumienie będzie działać tylko w trybie konserwacji. Przesyłanie strumieniowe ze strukturą nie jest obecnie tak kompletne, jak D Strumienie dla źródeł i ujść, które obsługuje poza urządzeniem, więc oceń wymagania, aby wybrać odpowiednią opcję przetwarzania strumienia spark.
Strumienie jako tabele
Przesyłanie strumieniowe ze strukturą platformy Spark reprezentuje strumień danych jako tabelę, która jest w głębi systemu, czyli tabela nadal rośnie wraz z nadejściem nowych danych. Ta tabela wejściowa jest stale przetwarzana przez długotrwałe zapytanie, a wyniki wysyłane do tabeli wyjściowej:

W przypadku przesyłania strumieniowego ze strukturą dane docierają do systemu i są natychmiast pozyskiwane do tabeli wejściowej. Zapytania są zapisywane (przy użyciu interfejsów API ramek danych i zestawu danych), które wykonują operacje względem tej tabeli wejściowej. Dane wyjściowe zapytania dają kolejną tabelę, tabelę wyników. Tabela wyników zawiera wyniki zapytania, z którego są rysowane dane dla zewnętrznego magazynu danych, takiego jak relacyjna baza danych. Czas przetwarzania danych z tabeli wejściowej jest kontrolowany przez interwał wyzwalacza. Domyślnie interwał wyzwalacza wynosi zero, więc przesyłanie strumieniowe ze strukturą próbuje przetworzyć dane natychmiast po ich nadejściu. W praktyce oznacza to, że gdy tylko przesyłanie strumieniowe ze strukturą zostanie wykonane przetwarzanie przebiegu poprzedniego zapytania, uruchamia kolejne uruchomienie przetwarzania względem wszystkich nowo odebranych danych. Wyzwalacz można skonfigurować tak, aby był uruchamiany w odstępach czasu, tak aby dane przesyłane strumieniowo są przetwarzane w partiach opartych na czasie.
Dane w tabelach wyników mogą zawierać tylko dane, które są nowe od czasu ostatniego przetworzenia zapytania (tryb dołączania) lub tabela może być odświeżona za każdym razem, gdy istnieją nowe dane, więc tabela zawiera wszystkie dane wyjściowe od rozpoczęcia zapytania przesyłania strumieniowego (tryb pełny).
Tryb dołączania
W trybie dołączania tylko wiersze dodane do tabeli wyników od ostatniego uruchomienia zapytania są obecne w tabeli wyników i zapisywane w magazynie zewnętrznym. Na przykład najprostsze zapytanie po prostu kopiuje wszystkie dane z tabeli wejściowej do tabeli wyników niezrealizowanych. Za każdym razem, gdy interwał wyzwalacza upłynie, nowe dane są przetwarzane, a wiersze reprezentujące te nowe dane są wyświetlane w tabeli wyników.
Rozważmy scenariusz, w którym przetwarzasz dane telemetryczne z czujników temperatury, takich jak termostat. Załóżmy, że pierwszy wyzwalacz przetworzył jedno zdarzenie jednocześnie 00:01 dla urządzenia 1 z odczytem temperatury 95 stopni. W pierwszym wyzwalaczu zapytania w tabeli wyników pojawia się tylko wiersz z czasem 00:01. W czasie 00:02 po nadejściu innego zdarzenia jedynym nowym wierszem jest wiersz o godzinie 00:02, więc tabela wyników będzie zawierać tylko ten jeden wiersz.
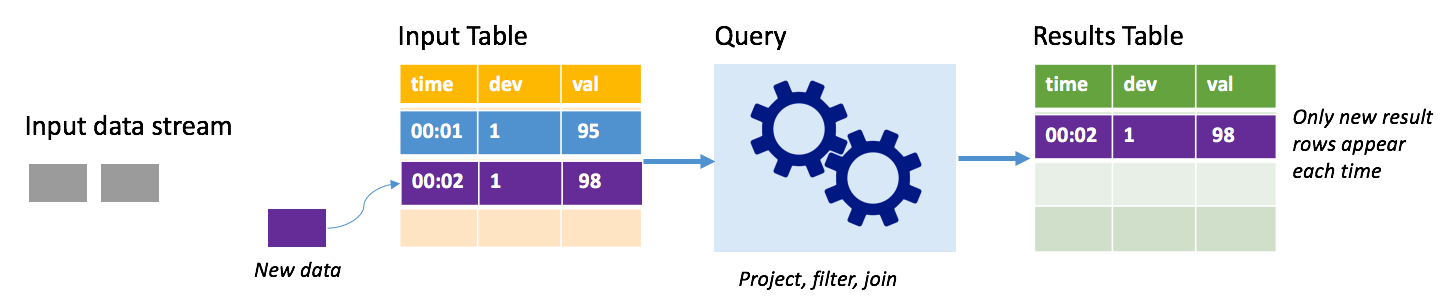
W przypadku korzystania z trybu dołączania zapytanie będzie stosować projekcje (wybierając kolumny, których dotyczy), filtrowanie (wybieranie tylko wierszy spełniających określone warunki) lub łączenie (rozszerzanie danych danymi z statycznej tabeli odnośników). Tryb dołączania ułatwia wypychanie tylko odpowiednich nowych danych do magazynu zewnętrznego.
Tryb ukończenia
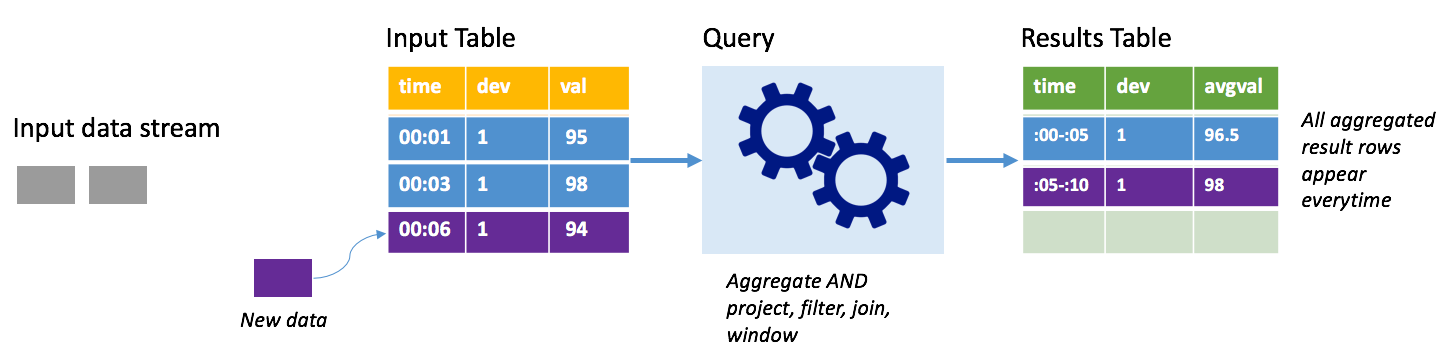
Rozważmy ten sam scenariusz, tym razem przy użyciu trybu pełnego. W trybie pełnym cała tabela danych wyjściowych jest odświeżona na każdym wyzwalaczu, więc tabela zawiera dane nie tylko z ostatniego uruchomienia wyzwalacza, ale ze wszystkich przebiegów. Możesz użyć trybu pełnego, aby skopiować dane niezmodyfikowane z tabeli wejściowej do tabeli wyników. Na każdym wyzwolonym uruchomieniu nowe wiersze wyników są wyświetlane wraz ze wszystkimi poprzednimi wierszami. Tabela wyników wyjściowych spowoduje zapisanie wszystkich zebranych danych od rozpoczęcia zapytania i w końcu zabraknie pamięci. Tryb kompletny jest przeznaczony do użycia z zapytaniami agregowanymi, które podsumowują dane przychodzące w jakiś sposób, więc na każdym wyzwalaczu tabela wyników jest aktualizowana przy użyciu nowego podsumowania.
Załóżmy, że do tej pory są już przetwarzane dane o wartości pięciu sekund i nadszedł czas, aby przetworzyć dane na szóstą sekundę. Tabela wejściowa zawiera zdarzenia dotyczące czasu 00:01 i godziny 00:03. Celem tego przykładowego zapytania jest zapewnienie średniej temperatury urządzenia co pięć sekund. Implementacja tego zapytania stosuje agregację, która przyjmuje wszystkie wartości, które należą do każdego 5-sekundowego okna, średnia temperatura i tworzy wiersz dla średniej temperatury w danym interwale. Na końcu pierwszego 5-sekundowego okna znajdują się dwie krotki: (00:01, 1, 95) i (00:03, 1, 98). Dlatego dla okna 00:00-00:05 agregacja generuje krotkę ze średnią temperaturą 96,5 stopni. W następnym 5-sekundowym oknie istnieje tylko jeden punkt danych w czasie 00:06, więc wynikowa średnia temperatura wynosi 98 stopni. W czasie 00:10 przy użyciu trybu pełnego tabela wyników zawiera wiersze dla obu okien 00:00-00:05 i 00:05-00:10, ponieważ zapytanie zwraca wszystkie zagregowane wiersze, a nie tylko nowe. W związku z tym tabela wyników nadal rośnie w miarę dodawania nowych okien.
Nie wszystkie zapytania korzystające z trybu pełnego spowodują wzrost tabeli bez ograniczeń. Rozważmy w poprzednim przykładzie, że zamiast średniej temperatury według przedziału czasu, średnia jest zamiast tego według identyfikatora urządzenia. Tabela wyników zawiera stałą liczbę wierszy (jeden na urządzenie) ze średnią temperaturą dla urządzenia we wszystkich punktach danych odebranych z tego urządzenia. W miarę odbierania nowych temperatur tabela wyników jest aktualizowana tak, aby średnie w tabeli były zawsze aktualne.
Składniki aplikacji do przesyłania strumieniowego ze strukturą platformy Spark
Proste przykładowe zapytanie może podsumować odczyty temperatury według godzinnych okien. W takim przypadku dane są przechowywane w plikach JSON w usłudze Azure Storage (dołączonej jako domyślny magazyn dla klastra usługi HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Te pliki JSON są przechowywane w temps podfolderze pod kontenerem klastra usługi HDInsight.
Definiowanie źródła danych wejściowych
Najpierw skonfiguruj ramkę danych, która opisuje źródło danych i wszystkie ustawienia wymagane przez to źródło. Ten przykład jest pobierany z plików JSON w usłudze Azure Storage i stosuje do nich schemat w czasie odczytu.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Stosowanie zapytania
Następnie zastosuj zapytanie zawierające żądane operacje względem ramki danych przesyłania strumieniowego. W tym przypadku agregacja grupuje wszystkie wiersze w oknach 1-godzinnych, a następnie oblicza minimalną, średnią i maksymalną temperaturę w tym 1-godzinnym przedziale czasu.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definiowanie ujścia wyjściowego
Następnie zdefiniuj lokalizację docelową wierszy, które są dodawane do tabeli wyników w każdym interwale wyzwalacza. W tym przykładzie tylko dane wyjściowe wszystkich wierszy do tabeli temps w pamięci, którą można później wykonać za pomocą usługi SparkSQL. Pełny tryb danych wyjściowych zapewnia, że wszystkie wiersze dla wszystkich okien są danymi wyjściowymi za każdym razem.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Uruchamianie zapytania
Uruchom zapytanie przesyłania strumieniowego i uruchom je do momentu odebrania sygnału zakończenia.
val query = streamingOutDF.start()
Wyświetlanie wyników
Gdy zapytanie jest uruchomione, w tej samej usłudze SparkSession można uruchomić zapytanie SparkSQL względem temps tabeli, w której są przechowywane wyniki zapytania.
select * from temps
To zapytanie daje wyniki podobne do następujących:
| Okno | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Aby uzyskać szczegółowe informacje na temat interfejsu API strumienia ze strukturą platformy Spark wraz z obsługiwanymi źródłami danych wejściowymi, operacjami i ujściami danych wyjściowych, zobacz Przewodnik programowania przesyłania strumieniowego ze strukturą platformy Apache Spark.
Tworzenie punktów kontrolnych i zapisywanie dzienników z wyprzedzeniem
Aby zapewnić odporność i odporność na uszkodzenia, przesyłanie strumieniowe ze strukturą opiera się na punktach kontrolnych, aby zapewnić nieprzerwane przetwarzanie strumienia, nawet w przypadku awarii węzłów. W usłudze HDInsight platforma Spark tworzy punkty kontrolne w celu trwałego magazynu— usługi Azure Storage lub Data Lake Storage. Te punkty kontrolne przechowują informacje o postępie zapytania przesyłania strumieniowego. Ponadto przesyłanie strumieniowe ze strukturą używa dziennika z wyprzedzeniem zapisu (WAL). Plik WAL przechwytuje pozyskane dane, które zostały odebrane, ale nie zostały jeszcze przetworzone przez zapytanie. Jeśli wystąpi awaria i ponowne uruchomienie przetwarzania z pliku WAL, wszystkie zdarzenia odebrane ze źródła nie zostaną utracone.
Wdrażanie aplikacji do przesyłania strumieniowego platformy Spark
Zazwyczaj aplikację Spark Streaming można utworzyć lokalnie w pliku JAR, a następnie wdrożyć ją na platformie Spark w usłudze HDInsight, kopiując plik JAR do domyślnego magazynu dołączonego do klastra usługi HDInsight. Aplikację można uruchomić przy użyciu interfejsów API REST usługi Apache Livy dostępnych w klastrze przy użyciu operacji POST. Treść pliku POST zawiera dokument JSON, który zawiera ścieżkę do pliku JAR, nazwę klasy, której główna metoda definiuje i uruchamia aplikację przesyłania strumieniowego oraz opcjonalnie wymagania dotyczące zasobów zadania (takie jak liczba funkcji wykonawczych, pamięci i rdzeni) oraz wszystkie ustawienia konfiguracji wymagane przez kod aplikacji.
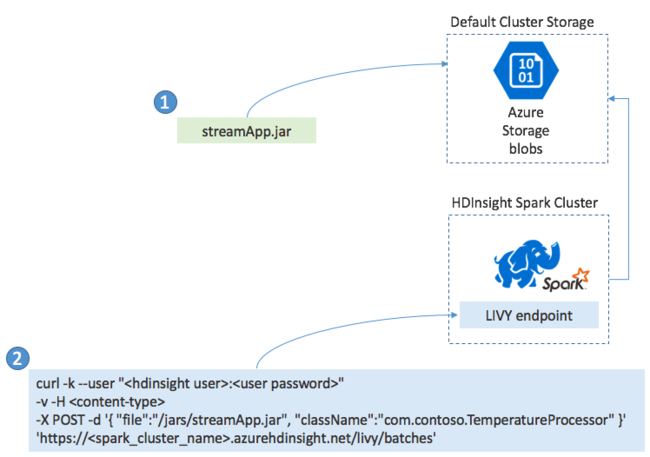
Stan wszystkich aplikacji można również sprawdzić za pomocą żądania GET względem punktu końcowego usługi LIVY. Na koniec możesz zakończyć działającą aplikację, wysyłając żądanie DELETE względem punktu końcowego usługi LIVY. Aby uzyskać szczegółowe informacje na temat interfejsu API usługi LIVY, zobacz Zdalne zadania za pomocą usługi Apache LIVY