przyspieszanie zapytań Azure Data Lake Storage
Przyspieszanie zapytań umożliwia aplikacjom i strukturom analitycznym radykalne optymalizowanie przetwarzania danych przez pobieranie tylko danych, których potrzebują do wykonania danej operacji. Skraca to czas i moc obliczeniową wymaganą do uzyskania krytycznych informacji na temat przechowywanych danych.
Omówienie
Przyspieszanie zapytań akceptuje predykaty filtrowania i projekcje kolumn, które umożliwiają aplikacjom filtrowanie wierszy i kolumn w czasie odczytywania danych z dysku. Tylko dane, które spełniają warunki predykatu, są przesyłane przez sieć do aplikacji. Zmniejsza to opóźnienie sieci i koszt obliczeniowy.
Za pomocą języka SQL można określić predykaty filtru wierszy i projekcje kolumn w żądaniu przyspieszania zapytań. Żądanie przetwarza tylko jeden plik. W związku z tym zaawansowane funkcje relacyjne języka SQL, takie jak sprzężenia i grupowanie według agregacji, nie są obsługiwane. Przyspieszanie zapytań obsługuje dane w formacie CSV i JSON jako dane wejściowe dla każdego żądania.
Funkcja przyspieszania zapytań nie jest ograniczona do Data Lake Storage (konta magazynu z włączoną hierarchiczną przestrzenią nazw). Przyspieszanie zapytań jest zgodne z obiektami blob na kontach magazynu, które nie mają włączonej hierarchicznej przestrzeni nazw. Oznacza to, że można osiągnąć takie samo zmniejszenie opóźnienia sieci i kosztów obliczeniowych podczas przetwarzania danych, które zostały już zapisane jako obiekty blob na kontach magazynu.
Aby zapoznać się z przykładem używania przyspieszania zapytań w aplikacji klienckiej, zobacz Filtrowanie danych przy użyciu przyspieszania zapytań Azure Data Lake Storage.
Przepływ danych
Na poniższym diagramie pokazano, jak typowa aplikacja używa przyspieszania zapytań do przetwarzania danych.
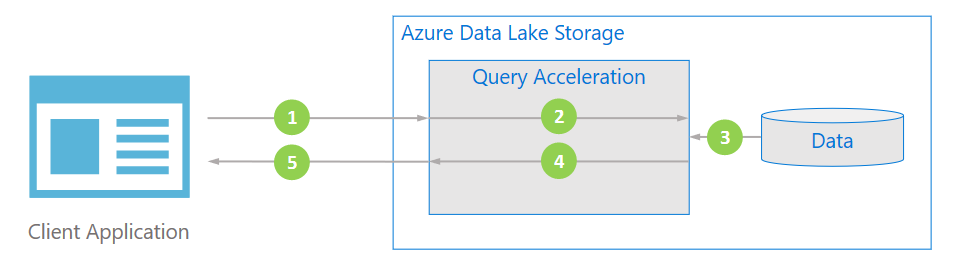
Aplikacja kliencka żąda danych pliku, określając predykaty i projekcje kolumn.
Przyspieszanie zapytań analizuje określone zapytanie SQL i dystrybuuje pracę w celu analizowania i filtrowania danych.
Procesory odczytują dane z dysku, analizują dane przy użyciu odpowiedniego formatu, a następnie filtrują dane, stosując określone predykaty i projekcje kolumn.
Przyspieszanie zapytań łączy fragmenty odpowiedzi, aby przesyłać strumieniowo z powrotem do aplikacji klienckiej.
Aplikacja kliencka odbiera i analizuje przesyłaną strumieniowo odpowiedź. Aplikacja nie musi filtrować żadnych innych danych i może bezpośrednio zastosować żądane obliczenia lub przekształcenie.
Lepsza wydajność przy niższych kosztach
Przyspieszanie zapytań optymalizuje wydajność, zmniejszając ilość danych przesyłanych i przetwarzanych przez aplikację.
Aby obliczyć zagregowaną wartość, aplikacje często pobierają wszystkie dane z pliku, a następnie przetwarzają i filtrują dane lokalnie. Analiza wzorców danych wejściowych/wyjściowych dla obciążeń analitycznych pokazuje, że aplikacje zwykle wymagają tylko 20% odczytywanych danych w celu wykonania dowolnego obliczenia. Ta statystyka jest prawdziwa nawet po zastosowaniu technik, takich jak oczyszczanie partycji. Oznacza to, że 80% tych danych jest niepotrzebnie przesyłanych przez sieć, analizowane i filtrowane przez aplikacje. Ten wzorzec, przeznaczony do usuwania niepotrzebnych danych, wiąże się ze znacznymi kosztami obliczeniowymi.
Mimo że platforma Azure oferuje wiodącą w branży sieć, zarówno pod względem przepływności, jak i opóźnienia, niepotrzebnie transfer danych przez sieć jest nadal kosztowna dla wydajności aplikacji. Filtrując niepożądane dane podczas żądania magazynu, przyspieszanie zapytań eliminuje ten koszt.
Ponadto obciążenie procesora CPU wymagane do analizowania i filtrowania niepotrzebnych danych wymaga od aplikacji aprowizacji większej liczby i większych maszyn wirtualnych w celu wykonania swojej pracy. Dzięki przeniesieniu tego obciążenia obliczeniowego do przyspieszania zapytań aplikacje mogą uzyskać znaczne oszczędności kosztów.
Aplikacje, które mogą korzystać z przyspieszania zapytań
Przyspieszanie zapytań jest przeznaczone dla rozproszonych struktur analitycznych i aplikacji do przetwarzania danych.
Rozproszone struktury analityczne, takie jak Apache Spark i Apache Hive, obejmują warstwę abstrakcji magazynu w ramach platformy. Aparaty te obejmują również optymalizatory zapytań, które mogą uwzględniać wiedzę na temat możliwości podstawowej usługi we/wy podczas określania optymalnego planu zapytania dla zapytań użytkowników. Te struktury zaczynają integrować przyspieszanie zapytań. W związku z tym użytkownicy tych struktur widzą większe opóźnienie zapytań i niższy całkowity koszt posiadania bez konieczności wprowadzania żadnych zmian w zapytaniach.
Przyspieszanie zapytań jest również przeznaczone dla aplikacji do przetwarzania danych. Te typy aplikacji zwykle wykonują przekształcenia danych na dużą skalę, które mogą nie prowadzić bezpośrednio do analizy szczegółowych informacji, dzięki czemu nie zawsze używają ustalonych rozproszonych struktur analitycznych. Te aplikacje często mają bardziej bezpośrednią relację z podstawową usługą magazynu, dzięki czemu mogą korzystać bezpośrednio z funkcji, takich jak przyspieszanie zapytań.
Aby zapoznać się z przykładem sposobu integrowania przyspieszania zapytań przez aplikację, zobacz Filtrowanie danych przy użyciu przyspieszania zapytań Azure Data Lake Storage.
Cennik
Ze względu na zwiększone obciążenie obliczeniowe w usłudze Azure Data Lake Storage model cen użycia przyspieszania zapytań różni się od normalnego modelu transakcji Azure Data Lake Storage. Przyspieszanie zapytań obciąża koszt ilości zeskanowanych danych, a także koszt ilości danych zwróconych do obiektu wywołującego. Aby uzyskać więcej informacji, zobacz Azure Data Lake Storage Gen2 cennik.
Pomimo zmiany modelu rozliczeniowego model cen przyspieszania zapytań został zaprojektowany tak, aby obniżyć całkowity koszt posiadania obciążenia, biorąc pod uwagę zmniejszenie znacznie droższych kosztów maszyn wirtualnych.